08 数据采集:如何自动化采集数据?

重点介绍爬虫做抓取
1.Python 爬虫
1)使用 Requests 爬取内容。我们可以使用 Requests 库来抓取网页信息。Requests 库可以说是 Python 爬虫的利器,也就是 Python 的 HTTP 库,通过这个库爬取网页中的数据,非常方便,可以帮我们节约大量的时间。
2)使用 XPath 解析内容。XPath 是 XML Path 的缩写,也就是 XML 路径语言。它是一种用来确定 XML 文档中某部分位置的语言,在开发中经常用来当作小型查询语言。XPath 可以通过元素和属性进行位置索引。
3)使用 Pandas 保存数据。Pandas 是让数据分析工作变得更加简单的高级数据结构,我们可以用 Pandas 保存爬取的数据。最后通过 Pandas 再写入到 XLS 或者 MySQL 等数据库中。Requests、XPath、Pandas 是 Python 的三个利器。当然做 Python 爬虫还有很多利器,比如 Selenium,PhantomJS,或者用 Puppeteer 这种无头模式。##这里可以实践一下
2.抓取工具
1)火车采集器
2)八爪鱼
3)集搜客
09 数据采集:如何用八爪鱼采集微博上的“D&G”评论
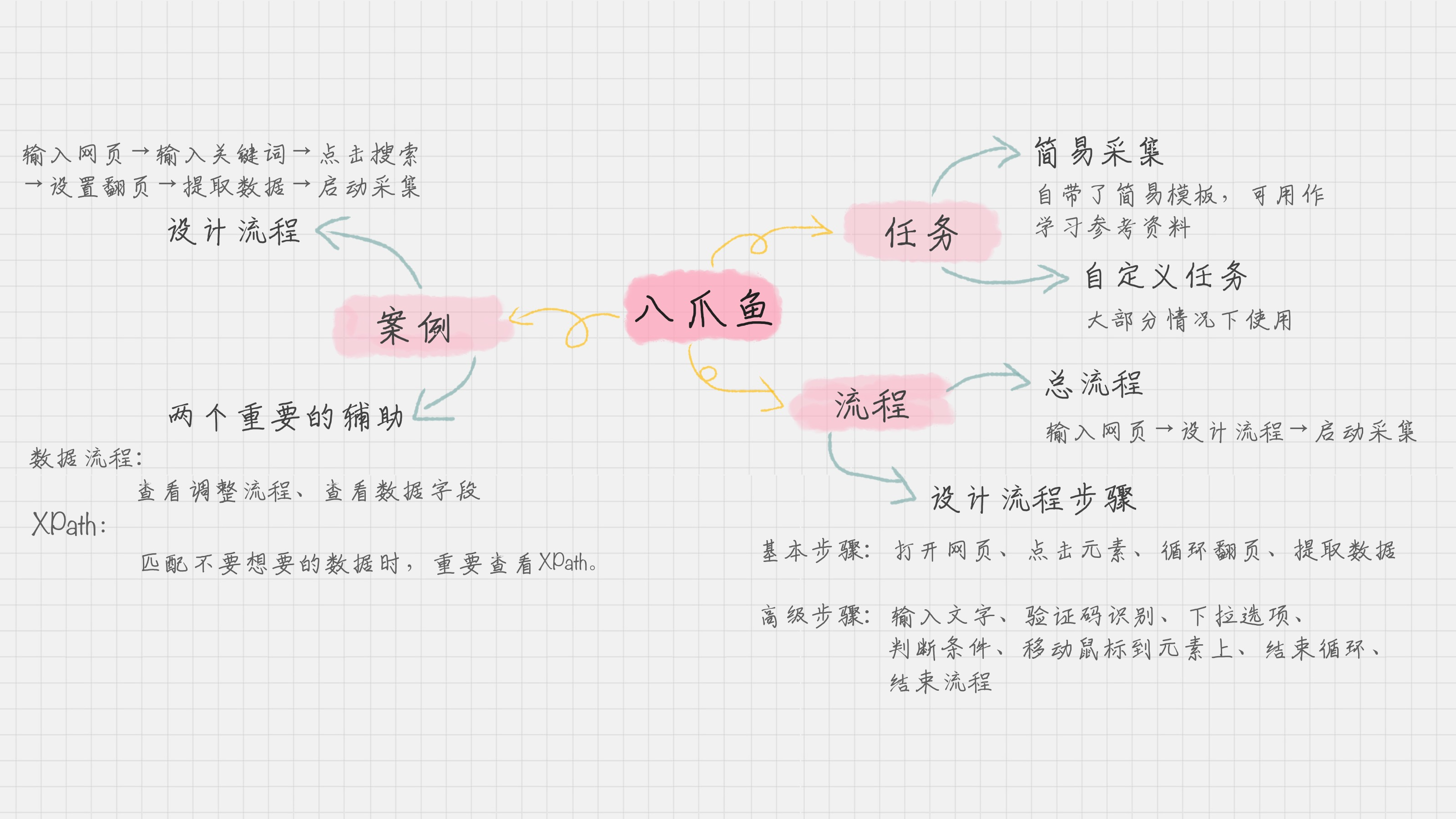
八爪鱼傻瓜软件,操作非常方便,比python爬虫更容易上手用
10 Python爬虫:如何自动化下载王祖贤海报?
python爬虫笔记中介绍了用urlretrieve可以下载xpath的非结构化数据,参考:爬虫3-python爬取非结构化数据下载到本地
这篇教程是从JSON和Xpath来介绍补充
如何使用 JSON 数据自动下载王祖贤的海报
这里我们用的url:https://www.douban.com/j/search_photo?q=%E7%8E%8B%E7%A5%96%E8%B4%A4&limit=20&start=0(这里给出的是json的链接。有时候显示会有细微不同,方法是:用Chrome浏览器的开发者工具,可以监测出来网页中是否有json数据的传输),打开JSON格式的,解析发现结构是:
{"images":
[{"src": …, "author": …, "url":…, "id": …, "title": …, "width":…, "height":…},
…
{"src": …, "author": …, "url":…, "id": …, "title": …, "width":…, "height":…}],
"total":26069,"limit":20,"more":true}
不如先用第一个页面上手来个下载小例子:
# -*- coding: utf-8 -* import requests import json query = '王祖贤' url = 'https://www.douban.com/j/search_photo?q=' + 'query' + '&limit=20&start=0' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/69.0.3497.81 Safari/537.36 Maxthon/5.3.8.2000 " } html = requests.get(url, headers=headers).text # 得到返回结果,是一个json格式 response = json.loads(html, encoding='utf-8') # 将 JSON 格式转换成 Python 对象 i=0 for image in response['images']: print(i) img_src = image['src'] #image是一个dict pic = requests.get(img_src, timeout=10) #这时候image其实是动态页面 XHR 数据。还需要再请求对应的url filename='C:/Users/.../image_json_test/'+str(i)+'.jpg' fp=open(filename,'wb') #'b一般处理非结构化如图片,wb有文件则覆盖,无文件则新增' fp.write(pic.content) #注意这里content fp.close() i+=1
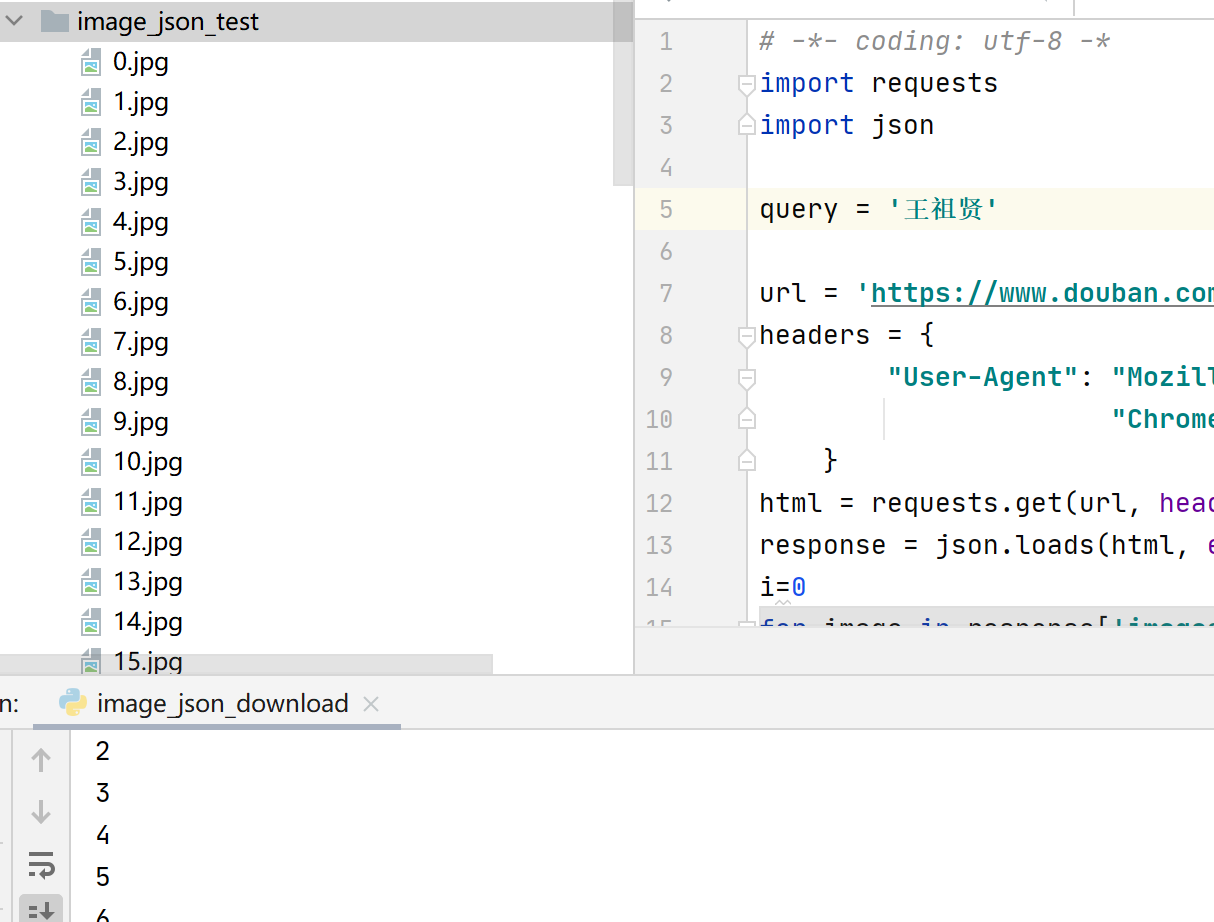
这里我们只爬取了20张图片,从上面的json串:"total":26069,"limit":20,"more":true我们知道总数量26069,每20张分页,要爬取更多,我们可以将图片download写成幻术,控制url翻页循环:
import requests import json query = '王祖贤' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/69.0.3497.81 Safari/537.36 Maxthon/5.3.8.2000 " } def download(src, id): # 图片下载函数 filename = 'C:/Users/luxia/PycharmProjects/shujuyunying/image_json_test/' + str(id) + '.jpg' try: pic = requests.get(src, timeout=10) f = open(filename, 'wb') f.write(pic.content) f.close() except requests.exceptions.ConnectionError: print('图片无法下载') ''' for 循环 请求全部的 url ''' for i in range(20, 26069, 20): url = 'https://www.douban.com/j/search_photo?q=' + query + '&limit=20&start=' + str(i) html = requests.get(url, headers=headers).text # 得到返回结果 response = json.loads(html, encoding='utf-8') # 将 JSON 格式转换成 Python 对象 for image in response['images']: img_src = image['src'] # 当前下载的图片网址 download(img_src, image['id']) # 下载一张图片
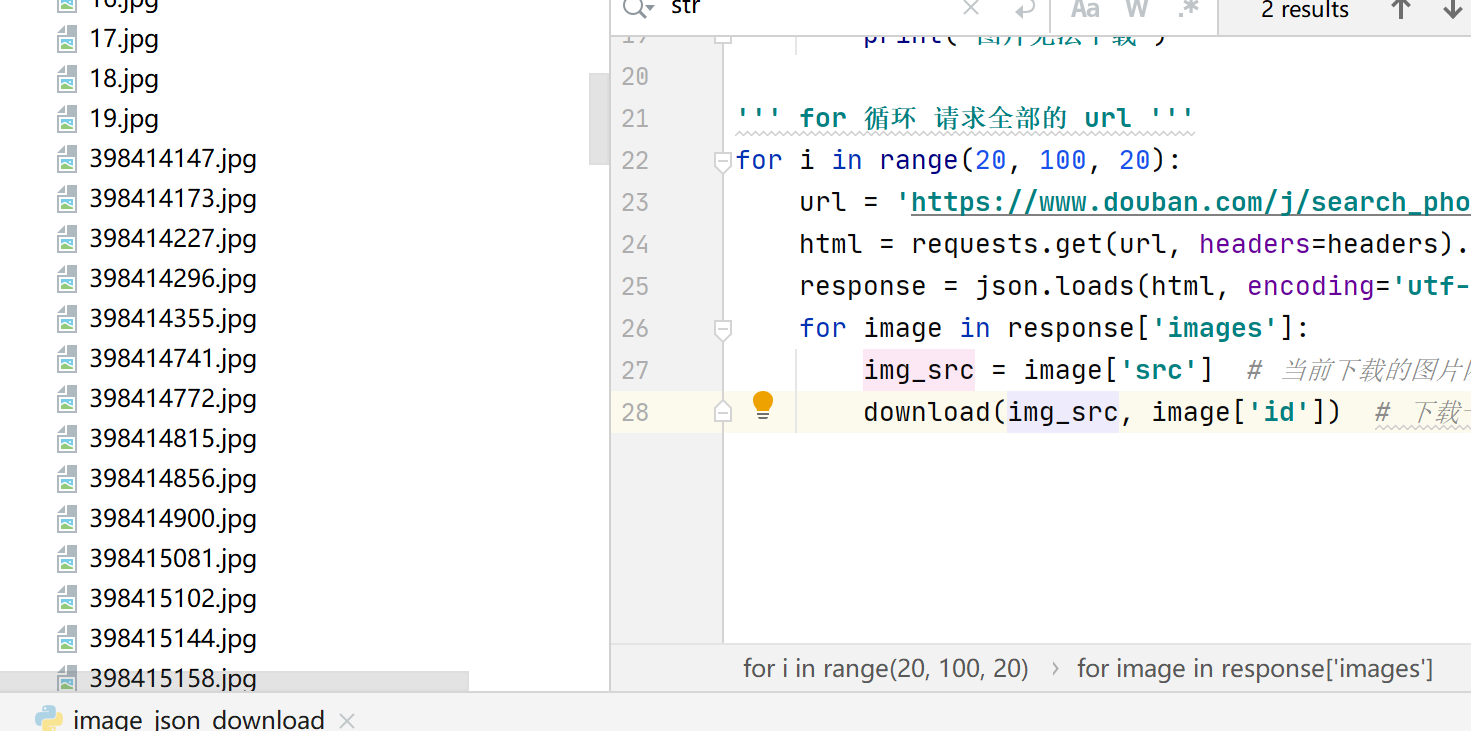
如何使用 XPath 自动下载王祖贤的电影海报封面
JSON 的数据格式数据结构很清爽,通过 Python 的 JSON 库就可以解析。
但有时候,网页会用 JS 请求数据,那么只有 JS 都加载完之后,我们才能获取完整的 HTML 文件。XPath 可以不受加载的限制,帮我们定位想要的元素。
讲义中推荐使用XPath Helper 插件获取Xpath路径,其中在浏览器 中可以用f12开启开发者模式点选页面元素查看xpath,在HTML中右键也可以复制粘贴xpath路径,具体可以参考爬虫相关的博文。
有时候当我们直接用 Requests 获取 HTML 的时候,发现想要的 XPath 并不存在。这是因为 HTML 还没有加载完,因此你需要一个工具,来进行网页加载的模拟,直到完成加载后再给你完整的 HTML。在 Python 中,这个工具就是 Selenium 库(这里暂时不涉及)。