
论文源址:https://arxiv.org/abs/1504.08083
参考博客:https://blog.csdn.net/shenxiaolu1984/article/details/51036677
摘要
该文提出了一个快速的基于区域框的卷积网络用于目标检测任务。Fast RCNN使用深度卷积网络对proposals进行分类。相比先前的工作,Fast R-CNN在提高准确率的基础上提高了训练和测试的速度。在VGG19的网络中,Fast R-CNN训练时间比R-CNN快9倍,而测试要快213倍。相比SPP net ,Fast R-CNN训练VGG16要快3倍,测试时快10倍。
介绍
深度卷积网络增强了图像的分类,和物体检测的准确率。相比图像分类,目标检测是一项更具挑战性的工作,需要更加复杂的方法进行解决。由于复杂度,目前的方法采用多阶段的方式进行训练,效率十分低。
复杂性主要来自于需要对物体位置的精确定位,这就造成了两个挑战,首先,大量的proposals需要被处理,其次,proposals只能提供粗略的物体位置,需要对其进行增强得到精细的位置,上述问题的解决需要计算速度,准确率和复杂度。
该文简化了基于卷积网络的目标检测器的训练处理过程。该文提出了单阶段的训练算法,将proposals的分类和位置的增强进行联合训练。
R-CNN与SPPnet:R-CNN基于深度卷积网络对proposals进行分类出色的实现了目标检测,但仍存在一些问题。(1)训练是多阶段的:R-CNN利用proposlas基于log损失对卷积网络进行微调。然后,用卷积网络提取的特征训练SVM。最后第三阶段,是框回归操作。(2)训练占用大量的时间和空间:SVM和框回归训练,每一个proposal提取的特征存入内存中。大量的proposals需要占用大量的内存资源。(3)目标检测的过程十分慢。基于VGG16每张图要花47S的时间。
R-CNN由于卷积网络需要处理每个proposal,没有共享计算,而SPPnet提出通过共享计算来提速R-CNN。SPPnet将整个图片送入卷积网络得到feature map,然后从feature map提取特征向量,对每一个proposal进行分类。通过最大池化操作来提取特征信息,并将proposal内部的部分feature map进行固定尺寸的输出。不同池化后的尺寸参考SPPnet进行拼接。SPPnet也存在缺点:与R-CNN相同都是一个多阶段的处理过程。也是特征提取,基于log损失对网络进行微调,训练SVM,最后对框进行回归操作。特征也是写入内存。不像R-CNN,SPPnet在金字塔池化层之前的卷积网络无法进行微调。进而限制了深度网络准确率的提升。
本文贡献:Fast R-CNN具有以下优点:(1)比R-CNN,SPPnet有更高的检测特性(mAP)(2)通过多任务损失实现单阶段的训练。(3)训练可以更新整个网络层。
Fast R-CNN结构与训练
结构如下,Fast R-CNN将一张图片与多个proposals送入卷积网络中,网络首先通过几个卷积和最大池化层处理整张图片来提取卷积特征。然后,针对每个目标物体,提出了ROI pooling用于从特征中提取固定长度的特征向量。每个特征向量送入一系列的全连接层。最终,产生两个分支:一个分支用于产生K+1个类别的softmax概率,另一个针对K个类别的每一个输出四个值用于编码框的位置信息。

ROI pooling
ROI pooling通过使用最大池化层将每个ROI的有效区域变为具有固定尺寸的小型feature map(HXW,比如7X7),每个ROI通过一个元组(r,c,h,w)进行定义,分别代表框中左上角的坐标(r,c),与框的高和宽(h,w)。
ROI max pooling通过将hxw的ROI窗口分为HxW的网格,每个子窗口的大小为h/H x w/W。对每个子窗口取最大处理,得到相应的输出。独立的将池化操作应用至每个特征通道上。ROI pooling 可以看作是金字塔池化层的特殊情形。只用了金字塔的一层,并利用池化处理后得到的值。
预训练网络的初始化
本文基于三种网络进行预训练,每个包含五层池化层和13层卷积层,将其改造为Fast R-CNN的预训练网络做了三处改动。(1)将最后一个最大池化层替换为RoI pooling层通过设置H,W的值与全连接曾进行匹配。(对于VGG16,设置H=W=7)。(2)网络最后的全连接层和soft max层被替换为两个分支。(3)网络包含两个输入,一个为图片的输入,另一个为图片中ROIs的输入。
微调检测网络
Fast R-CNN基于反向传播算法进行权重的训练。首先,对SPPnet金字塔池化层之前的网络权重无法更新进行了说明。本质原因是SPP层中训练来自不同图片的Rois利用反向传播算法,其效率是低效的。这样,会使每个RoI可能会有一个较大的感受野,一般会跨越整个输入图片。由于,输入需要处理整个感受野的大小,因此,训练的输入是巨大的。
该文利用特征共享提出了一种高效的训练的方法。在Fast R-CNN的训练阶段,使用SGD ,minibBatch进行分层次采样。首先,采样N个图片,然后,从每张图片中采样R/N个RoIs。来自相同图片的ROI在前向和反向传播的过程中共享计算与内存。这种方法并不会造成训练缓慢的收敛。本文采用N=2,R=128使用SGD优化方法迭代的效果优于R-CNN。
Fast R-CNN同时实现单阶段的训练,将Softmax分类器与框回归进行结合训练。
多任务损失
Fast R-CNN网络包含两个分支,第一个分支为每个Roi对应K+1个类别的概率离散值。另一个分支输出输出框回归的偏差。针对每个类别,都会产生一组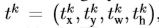 ,k代表类别中对应的某个类(4xk个元组)。t_k确定尺寸不变性和相关目标proposal log空间的变换。每个训练的ROI都存在一个类别为u的ground truth和目标为v的回归框。对每一个ROI,定义一个损失函数,用于联合训练分类和框回归。
,k代表类别中对应的某个类(4xk个元组)。t_k确定尺寸不变性和相关目标proposal log空间的变换。每个训练的ROI都存在一个类别为u的ground truth和目标为v的回归框。对每一个ROI,定义一个损失函数,用于联合训练分类和框回归。
![]()

对于框回归,定义损失函数如下:
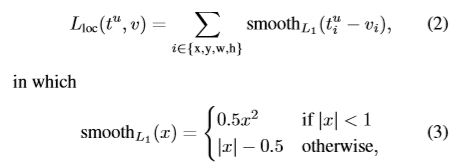
L1对异常值的敏感度要小于R-CNN与SPPnet中的L2损失。对L2进行训练时,要注意学习率,防止梯度消失。
Mini-batch sampling
本文选择batch 为2,每张图采样64个ROIs。从ROIs中筛选出四分之一的框作为object proposals,这些与ground truth的IoU值大于0.5.。筛选出来的框用前景类别进行标记。从剩下的框中选出与ground Truth IOU([0.1,0.5))值最大的候选框作为背景。标记类别为0。IOU值在0.1以下的执行类似于hard example mining 的启发式算法。
RoI pooling 层的反向传播算法
该文嘉定mini-batch 为1,对于多个batch,前向过程单独的处理图片。x_i作为第i个输入RoI pooling的激活值,y_rj代表第r个ROI对应的第j个输出。
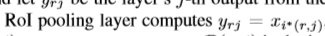
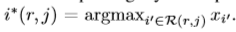

对于每一个RoI r及pooling 输出单元y_rj,通过最大池化操作中选择出的i。对y_r,j进行求偏导操作。
SGD隐层参量
全连接层使用0均值的高分布初始化softmax分类器和框回归,偏差分别为0.01 ,0.001,偏差初始化为0,每一层的权重学习率为1,偏差为2,整体学习率为0.001。
尺寸不变性
本文研究两个针对目标检测中的尺寸不变性的方式。(1)暴力方式解决,在训练和测试时,事先将图片调整为网络输入的尺寸大小,网络直接从训练数中学习尺寸不变性(2)使用图像金字塔。通过金字塔为网络提供一种相对较弱的尺寸不变性。测试时,图像金字塔用于规范化目标proposals。
Fast R-CNN检测
输入为一张图片和大量的目标proposals。测试时,proposals的数量大约为2000,针对每个测试的RoI r,前向过程输出一个类别后验概率分布p和一些列有关RoIr的预测框。(K个类别中的每个类别都有一个增强的框)。最后单独的对每个类别进行NMS处理。
基于阶段奇异值分解加速检测

用SVD处理权重矩阵利于简化网络的参数。
实验






Reference
[1] J. Carreira, R. Caseiro, J. Batista, and C. Sminchisescu. Semantic segmentation with second-order pooling. In ECCV, 2012. 5
[2] R. Caruana. Multitask learning. Machine learning, 28(1), 1997.
[3] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman. Return of the devil in the details: Delving deep into convolutional nets. In BMVC, 2014. 5