
论文源址:https://arxiv.org/abs/1811.12030
开源代码:未公开
摘要
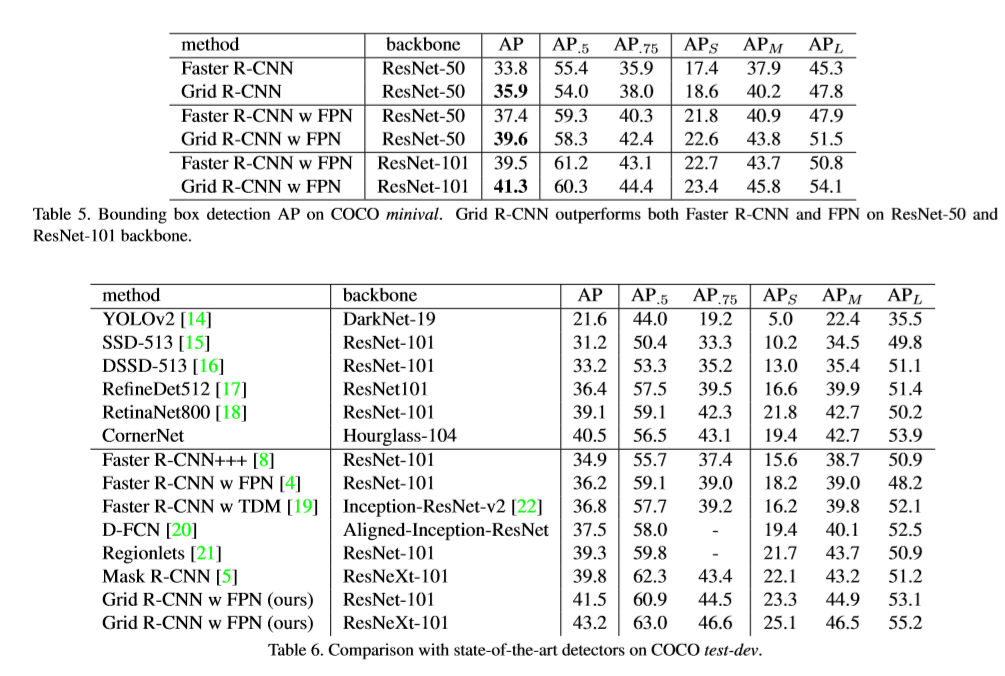
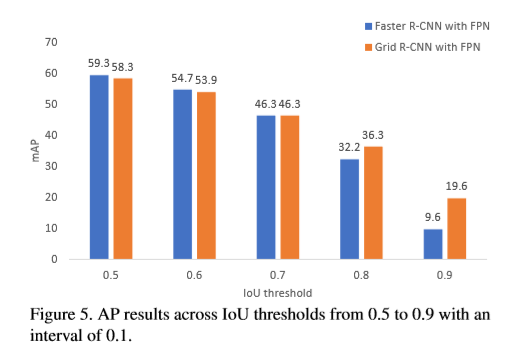
本文提出了目标检测网络Grid R-CNN,其基于网格定位机制实现准确的目标检测。传统方法主要基于回归操作,Grid R-CNN则捕捉详细的空间信息,同时具有全卷积结构中对位置信息的敏感性。【 Instead of using only two independent points】是指CornerNet预测的不准确性。Grid R-CNN使用多点监督,用于编码更多的细节信息,同时降低了不准确的特定点的影响。为了很好的利用网格中点的相关性,提出了一个两阶段信息融合策略融合相邻网格点的feature map。基于网格定位机制可以扩展的其他目标检测框架中。与基于Res50的Faster R-CNN相比在COCO数据集上 ,Grid R-CNN在IOU=0.8下AP提升了4.1%。基于FPN结构在IOU=0.9条件下提升了10.0%。
介绍
目标检测任务可以拆分为目标分类及定位两部分。经典的边界框定位模型为一个回归分支,其带有几个全连接层,并在高层次的feature map上进行候选框偏移的预测(propsoal或者预定义的anchor )。
本文提出的Grid R-CNN,将传统的回归部分替换为一个基于网格点定位的机制。显式的空间表示对于准确定位发挥重要作用。回归方法 是将feature map通过一个全连接层压缩为一个向量,而Grid R-CNN将目标边界框划分为一个个格子,同时应用一个全卷积网络,预测格子中点的位置。由于全卷积结构具有位置敏感性。Grid R-CNN保存显式的空间信息,同时可以得到格子中点的位置信息。如下图,当某个特定位置中一定数量的网格点确定,则对应的边界框位置也就确定了。由网格点指引,Grid R-CNN可以得到比传统回归方法更准确的空间信息。

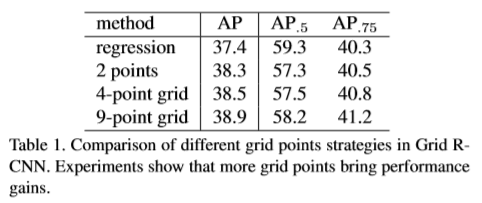
由于边界框有四个自由度,两个独立的点(左上角及右下角)足够可以用于定位目标。然而,由于点的位置与局部特征并未直接对应,因此,预测工作仍具有挑战性。比如,上图中,猫右上角的点不在猫身上。同时该点邻域只包含图片的背景,与周围像素共享相似的局部特征。为解决此问题,本文设计了多点监督机制。通过在一个格子中预定义目标点,可以得到更多的细节信息,从而降低预测不准确点的影响。比如,对于一个典型的3x3的格子监督。右上角的y坐标可能是不准确的,因此可以用刚好位于物体边界上的中上点(橘色点)与右上角点的y轴进行校准。网格点可以有效的减少总偏差。
此外,为了更好的利用格子中点的相关性,本文提出了信息融合的方法。具体实现为,对每一个grid point 设计一个单独的feature maps集。对于一个网格点,其相邻点的feature maps融合为一张feature map。融合后的feature map用于对应网格点的位置预测。因此,结合网格相关点的空间信息,提高了位置预测的准确率。
本文主要贡献:
(1)提出了Grid R-CNN,替换掉传统的基于全连接层保存空间i信息的回归网络。Grid R-CNN首次提出基于像素级预测网格点定位目标的二阶段的目标检测网络。
(2)设计了一个多点监督机制,用预测网格中的点,从而减少不准确点的作用。进一步提出了基于feature map级别的信息融合可以编码相关网格点的空间信息,可以对位置很好的进行校准。
(3)实验发现Grid R-CNN可以应用至不同的目标检测框架,同时,取得较好的结果。
相关工作
本文方法基于两阶段的目标检测,做了简单的回顾,两阶段的目标检测从R-CNN开始,基于区域的深度网络用于对每个RoI进行分类及定位。RoI由一些低层次的据算计视觉算法得到。SPP-Net,与Fast R-CNN通过在共享feature map上提取区域feature map。虽然,SPP-Net,Fast R-CNN有效的提升了目标检测的效果,但ROI生成部分仍无法进行端到端的训练。随后,Faster R-CNN通过提出了一个轻量级的区域生成网络(RPN)解决上述问题,进而产生一系列离散的RoI。可以使整个网络进行端到端的训练,从而提高了训练的精度与速度。
进来,许多工作在不同方面扩展Faster R-CNN的结构来实现更好的检测。R-FCN提出用一个基于区域的全卷积网络替换原始的全连接网络。FPN提出了一个t带有侧连接的op-down的结构用于建立高层次的不同尺寸的语义信息。Mask R-CNN通过在原始边界框回归分支增加一个平行分支用于预测一个像素级的目标mask扩展Faster R-CNN。本文与Mask R-CNN不同,用一个新的网格分支替换回归分支用于目标的定位。
CornerNet 是一个单阶段的目标检测器是一个单阶段的目标检测网络,使用成对的关键点对目标的边界框进行定位。CornerNet是自底向上的检测器,通过一个沙漏网络检测边界框所有可能关键点位置。同时,设计了一个嵌入式网络尽可能的映射成对的关键点。通过嵌入式机制,可以将检测器的角成对分组,并对边界框进行定位。
本文方法与CornerNet不同,CornerNet为一个自底下个上的方法,因此,在没有实例的情况下直接生成关键点。CorenerNet的关键是识别属于相同实例的关键点,并对其进行组合。本文是自顶向底的二阶段方式。首先定义实例。本文关注如何更准确的定位边界关键点,此外,本文设计了网格点的特征融合,利用网格中相关点的特征进行校准,相比两个点,准确率较高。
Grid R-CNN
网络整体结构如下,基于Region proposal,每个RoI的特征独立的从CNN的feature map中提取。提取的ROI特征用于后续相应proposal的分类及定位工作。本文用网格引导机制预测定位来替换偏差回归。基于全卷积网络作为网格预测分支。输出一个空间map(概率heatmap),可以定位与目标物对齐的边界框的网格点。借助网格点,通过feature map级别的特征融合,最终确定目标物的准确边界框。
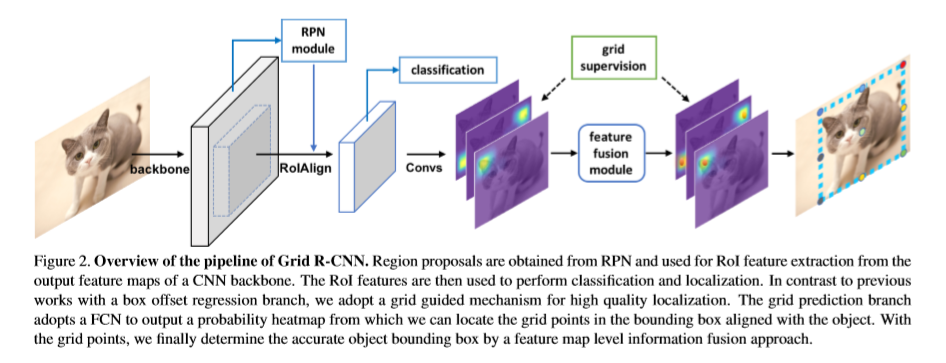
Grid Guided Localization
以前基于全连接层对框的偏差进行回归用于目标定位,本文应用一个全卷积网络对预先定义的网格点的位置进行预测,然后利用这些点去欸的那个目标边界框。设计了一个大小为NxN的网格形式的目标点于目标物的边界框对齐。本文举了一个3x3的栗子。这里的网格点包含四个角点,四条边的重点及中心点共9个点。每个proposal的特征通过RoIAlign操作进行提取,经过固定空间大小的14x14,后接8个3x3的空洞卷积层。然后,接两层反卷积层增大feature map的分辨率为56x56,网格预测分支输出NxN heatmaps,分辨率为56x56,将每个heatmap上使用像素级的sigmoid用于得到概率图。每一个heatmap有一个相对应的监督map。其中,5个交叉的像素被标记为目标网格点的正位置。使用二分类交叉熵损失作为优化方法。
推理时,在每个heatmap上挑选confidence最高的像素,计算原图中对应位置作为网格点。在heatmap上的一个点(Hx,Hy)将按如下等式映射至原图点。

然后,通过预测的网格点确定目标边界框的四个边界。将四个边界的坐标定义为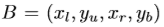 ,分别代表左,上,右,底边。
,分别代表左,上,右,底边。 表示第j个坐标为
表示第j个坐标为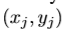
的网格点,预测的概率为Pj。Ei代表定位第i个边的网格点的索引集合。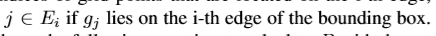 ,边界坐标按如下方式计算。
,边界坐标按如下方式计算。
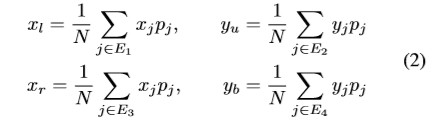
以上边界yu举例,代表顶边三个y轴坐标的概率加权平均。
Grid Points Feature Fusion
网格内部各点之间存在空间相关性,同时其位置可以彼此互相校准,从而减少整体的偏差,因此,本文设计了空间信息融合模型。一种直观感觉是对坐标水平的平均, 但这样做会丢失丰富的feature map信息。另一种方法是提取feature map上相关网格点的局部特征用于融合操作。然而,这种方法仍会丢失不同feature maps中潜在的有效信息。以3x3的网格举例,为了校准左上角的定点,左上角的特征区域中,邻域点的feature maps(如上层中间点)可能会提供有效信息,但并未加以利用。为此,设计了一个feature map级的信息融合机制用于利用grid中的每个点。为了区分不同点的feature map,使用NxN组卷积核单独的提取特征。同时,相应的网格点进行监督。因此,对于一个确定的网格点,每个feature map都由确定的关系。Fi表示第i个点相关的feature map。
对于每个网格点,具有L1距离为1的点有利于融合操作,这些点称为源点。将源点集合定义为Si,对于Si中的第j个源点,Fj将被3个连续的5x5的卷积层处理,用于信息转移,处理过程定义为Tj-i。所有源点处理后的特征于Fi进行融合,最终得到一个融合的feature map 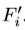 ,如下图,本文使用简单的加法操作用于融合进行增强。
,如下图,本文使用简单的加法操作用于融合进行增强。
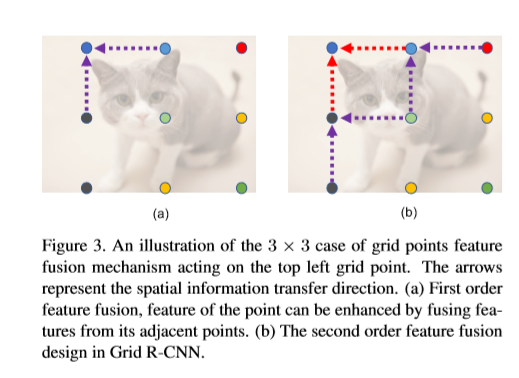
融合信息用下式表示。在每个网格点基础上得到的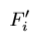 ,在新的卷积层
,在新的卷积层 执行融合操作,此过程的参数与上一级之间是独立互不影响的。第二次得到的融合信息
执行融合操作,此过程的参数与上一级之间是独立互不影响的。第二次得到的融合信息 用于最终heatmap的输出,进而用于网格点的位置预测。第二级融合可以使信息以距离为2的范围进行转移。如上图b,左上角的点可以结合其他5个点的信息用于校准。
用于最终heatmap的输出,进而用于网格点的位置预测。第二级融合可以使信息以距离为2的范围进行转移。如上图b,左上角的点可以结合其他5个点的信息用于校准。

Extended Region Mapping
网格预测模型输出heatmaps,其具有固定的空间大小,用于表示网格点位置的confidnece 分布。由于全卷积网络结构的使用,空间信息始终被保存,输出的heatmap很自然与输入的propsoal的原图中的位置进行相关联。然而,有的region proposal可能无法覆盖目标,意味着,有些groudnd truth 可能会超过region proposal的边界,从而无法在进行推理时在监督map上进行标记。
训练时,一些网格点labels的缺失会无法有效的利用训练样本。在推理时,选出heatmap中最大的像素,网格点可能会得到一个完全错误的位置,对应的ground truth会在对应区域的外侧。如下图。
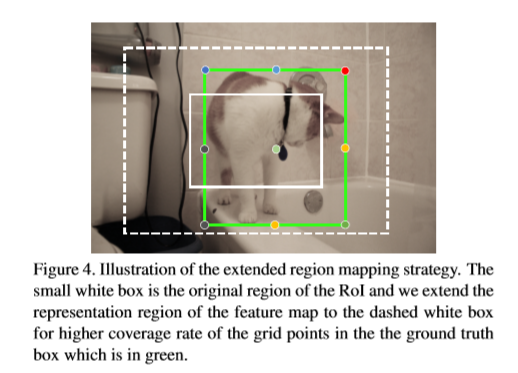
一种方法是扩大proposal的区域,此方法可以确保大部分的网格点被包含在proposal中,但也会引入大量无用的背景,甚至其他目标物体。实验发现,此方法对准确率无较大提升,甚至会使准确率降低。
为解决上述问题,本文通过扩展的区域映射方法修改了输出的heatmaps与原图中区域之间的联系。具体实现为,当得到proposals时,仍从feature map中相同的区域提取RoI特征。然而,本文重新定义了输出heatmap的表示区间。修改为原图对应区域的两倍,因此,网格点会以较大的概率被覆盖。扩展的区域映射等式如下。
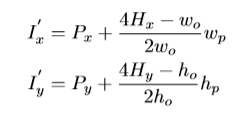
映射完后,所有正例propossals(与ground truth box 重合率大于0.5的proposals)的目标网格点都被heatmap的相关区域覆盖。
Implementation Detail
网络配置: 使用深度为50/101的ResNets或者FPN网络作为模型的backbone。RPN用于提取候选区域。针对COCO数据集设置的最短输入边为800像素,VOC为600像素。RPN中,每个图片包含256个anchors,正anchor为128,负anchor为128.RPN anchors设置5种尺寸及3个尺寸比例。正样例的IOU设置为0.7,负样例的IOU为0.3。分类分支中,ROI大于0.5的被标记为正样本,基于Faster R-CNN每张图提取128个RoIs,基于FPN,每张图提取512个RoIs。正负比例为1:3。RoIAlign应用至每个实验。分类分支中池化大小为7,网格分支中为14x14。网格预测分支每张图最多为96个RoIs,只有正类RoIs用于采样训练。
优化: 使用SGD优化训练,动量为0.9,权重衰减为0.0001。backbone参数使用ImageNet分类任务进行初始化。其他参数量使用He(MSRA)初始化。使用水平翻转进行数据增强。
推理: 在推理阶段,每张图中生成300/1000(Faster R-CNN/FPN),RoI的特征使用RoIAlign进行处理。分类分支用于生成类别score。后接阈值为0.5的NMS处理。然后,挑出125个最高的score RoIs,然后,将ROIAlign处理的features 送入网格分支,用于更准确的定位操作。最后,使用阈值为0.5的NMS处理重复的检测框。
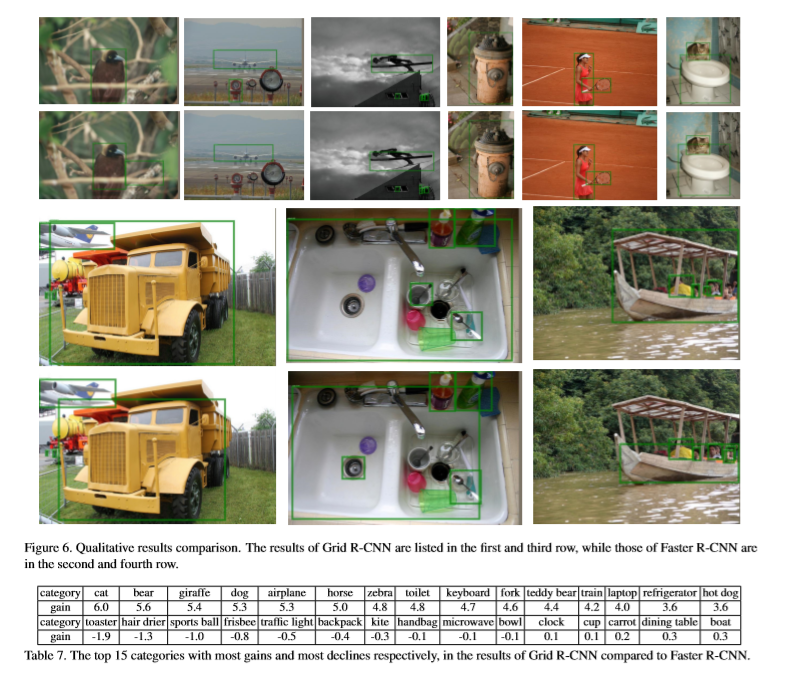
实验


Reference
[1] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014. 1, 2, 3
[2] R. Girshick. Fast R-CNN. In ICCV, 2015. 1, 2, 3
[3] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015. 1, 2, 3, 5
[4] T.-Y. Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In CVPR, 2017. 1, 2, 3, 5, 6, 7
[5] K. He, G. Gkioxari, P. Doll´ar, and R. Girshick. Mask r-cnn. In ICCV, 2017. 1, 2, 3, 5, 7
[6] Cai, Z., Vasconcelos, N.: Cascade r-cnn: Delving into high quality object detection. arXiv preprint arXiv:1712.00726 (2017) 1, 3, 6