
论文源址:https://arxiv.org/abs/1505.04366
tensorflow代码:https://github.com/fabianbormann/Tensorflow-DeconvNet-Segmentation
基于DenconvNet的钢铁分割实验:https://github.com/fourmi1995/IronSegExperiment-DeconvNet
摘要
通过学习一个反卷积网络来实现分割算法, 本文卷积部分基于改进的VGG-16,反卷积网络部分由反卷积层和上采样层组成。测试时,用训练好的模型测试一张图片上的许多proosal,最后以一种简单的方式将所有预测的proposals进行拼接。该文通过引入反卷积和proposal级别的预测分割改进了传统基于FCN网络的部分不足,可以识别出细小及自然场景中不同尺寸的物体。
介绍
目前,分割主要解决结构类型的像素级预测分类,经过图片中局部区域的分类会从网络中得到大致的label,通过双线性插值的反卷积,进行像素级的标记。CRF作为后处理优化分割效果。FCN的优势在于可以将整幅图片送入网络,计算速度较快。
基于FCN网络的几个限制:(1)网络的感受野尺寸是预先定死的。因此,对于输入图片中比感受野大或者小的物体可能会被忽略。换言之,对于较大的物体,只有局部的细节信息能够被正确标记,或者标记的结果是不连续的,而对于小物体会被忽略。由于分割的边界细节和语义信息之间的权衡,通过跳跃结构来改善效果这一做法也无法从根本上解决问题。
(2)由于,卷积后送入反卷积层的feature map十分稀疏,而且,反卷积的过程又十分的粗糙,输入图片中的结构细节信息会有所损失。
该文主要贡献:
(1)学习一个带有反卷积层,上采样层,ReLU层的深层反卷积网络。
(2)将训练好的模型,应用到图片的proposals中,得到实例级分割结果,最终将这些结合组成最终的分割结果,解决了原始FCN网络中的尺寸问题,同时,物体的细节信息更详尽。
相关工作
(1)基于多尺寸超像素分类,将分类后的结果进行组合得到像素级的标记。(2)将reginon proposal进行分类,对像素级的分割map进行增强处理。(3)将传统CNN中的全连接层转变为具有较大感受野的卷积层得到的FCN网络取得较好的效果。输入图片进行前向操作得到的粗略的类别 score map。FCN基于插值操作进行反卷积,而且只通过微调网络的CNN部分来间接的学习反卷积,网络得到的分割结果后通过CRF进行增强。(4)基于弱监督的分割方法,输入的图片只有bounding box形式的标签类别,通过重复的迭代操作输出准确的分割结果。该文是基于全监督的学习。
分割网络包含反卷积部分,但对于反卷积网络的学习还没有较成熟的方法。反卷积用于对特征表示的重构,通过保存最大池化操作值的位置来实现上采样操作,反卷积也可以用于可视化训练过程中的激活特征。
系统结构
该网络包括两个部分,卷积网络和反卷积网络两部分。卷积网络部分将输入图片转变为多维度的特征表示,用作提取特征,反卷积用于从提取的特征生成分割物体的形状。网络的最后一层输出是一张概率map,与输入图片的大小相同,表示每个像素代表属于某个类别的概率。网络结构如下。
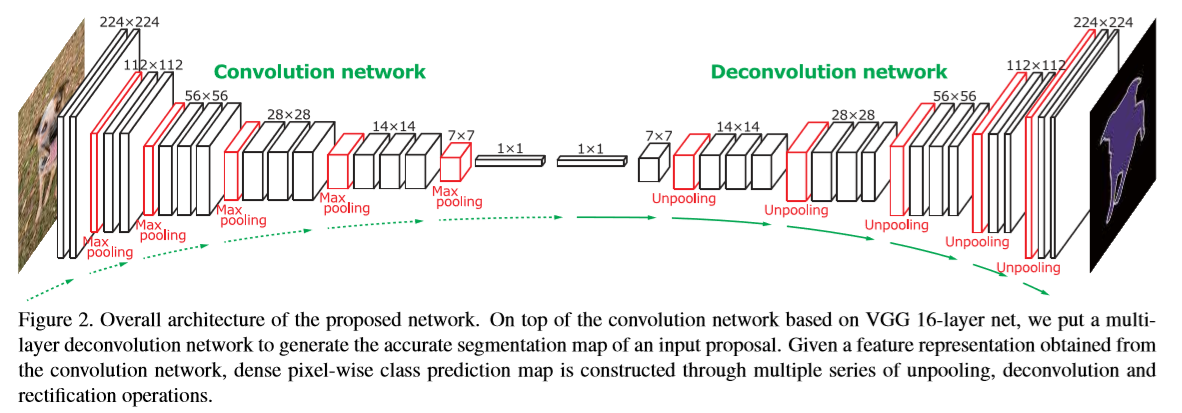
该网络基于VGG16网络中卷积部分,有13层卷积,非线性,池化等操作参杂在卷积层中,卷积网络部分后面接着两层全连接层用于增强类别的分类,反卷积部分是卷积部分的镜像,反卷积网络结合反卷积,反池化,及非线性处理层等几个部分,通过反卷积与上采样操作扩大响应区域。
反卷积部分:
反池化模块:卷积网络中的池化操作用于在较低层网络张,通过抽象一定感受野范围的特征值来过滤部分噪声,虽然,池化操作得到的抽象信息对上层网络中有助于提高分类效果,但赤化操作后,图像的位置信息会有所损失,不利于分割这种对位置信息要求高的任务。针对池化操作中位置信息的损失,反池化将池化操作中最大值变量的位置保存,在反池化的过程中进行恢复其在原图中的对应位置。
反卷积模块:反池化输出结果的尺寸虽然变大了,但特征值仍比较稀疏,通过引入反卷积来是特征变得密集。反卷积引入类似于卷积的卷积核,卷积是将多个输入通过一个滤波器输出一个值,反卷积层的作用是捕捉不同层的形状信息。较低层的filter捕捉整体的形状,而对于物体类别细节信息在较高层的网络中进行编码,反卷积网络将类别细节信息->形状信息都考虑其中,在只有卷积层的网络中这种操作是没有的。

该文反卷积网络可视化的结果如下:

该网络中的卷积部分得到的像素级的类别概率map送入反卷积网络中,经过一系列的反池化, 反卷积,及非线性操作。由上图可观察到,物体在反卷积网络中,目标物特征由稀疏到精细。较低层网络更多捕捉物体的粗略的外形,像位置,形状,区域等,在高层网络中捕捉更加复杂的模式类别。反池化与反卷积在重构feature map时发挥着不同的作用,反池化通过原feature map中较强像素的位置信息来捕捉example-specific (个人理解为外形,位置等特征)结构,进而以一定的像素来构建目标的结构细节,反卷积中的卷积核更倾向于捕捉class-specific形状,经过反卷积,虽然会有噪声的影响,但激活值仍会与目标类别进行相关联。该网络将反卷积和反池化结合,获得较好的分割效果。
训练过程
(1)Batch Normalization :将每层的输入分布变为标准高斯分布来减少内协变量,在卷积和反卷积的每一层后添加BN层。避免进入局部最优。
(2) 两阶段训练:首先基于标签,对含有实例的图片进行裁剪得到包含目标的图片,进一步构成较简单的数据进行预训练,然后使用复杂的数据进行微调,复杂数据集基于简单数据进行构建,proposals与groundTruth的Iou大于0.5的被选作用于训练。但此做法的弊端是,目标物的位置与尺寸信息与原始数据集出现差别。
实验

Reference
[1] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected CRFs. In ICLR, 2015. 1, 2, 4, 7
[2] J. Dai, K. He, and J. Sun. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In ICCV, 2015. 2, 6, 7
[3] J. Dai, K. He, and J. Sun. Convolutional feature masking for joint object and stuff segmentation. In CVPR, 2015. 2, 7
个人实验结果

