HashMap
HashMap1.8结构图
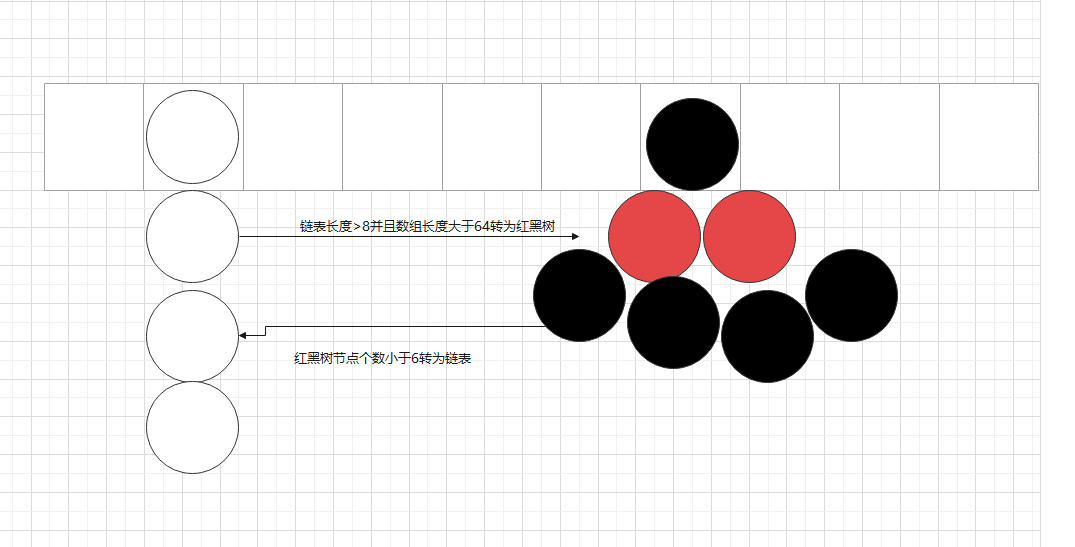
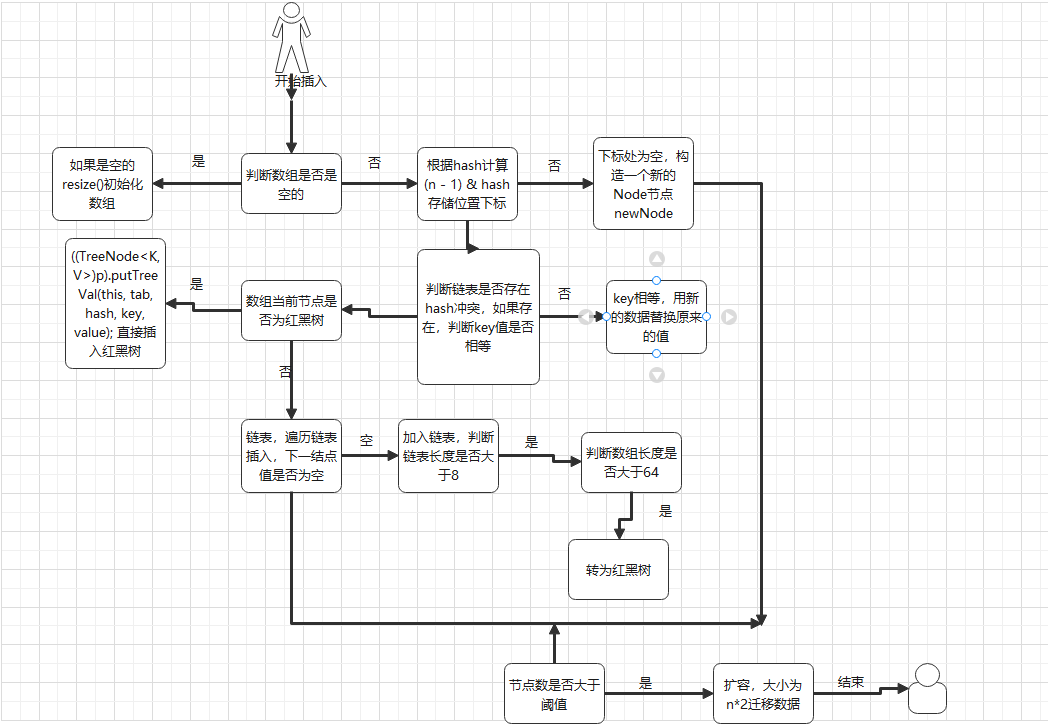
put过程结构图
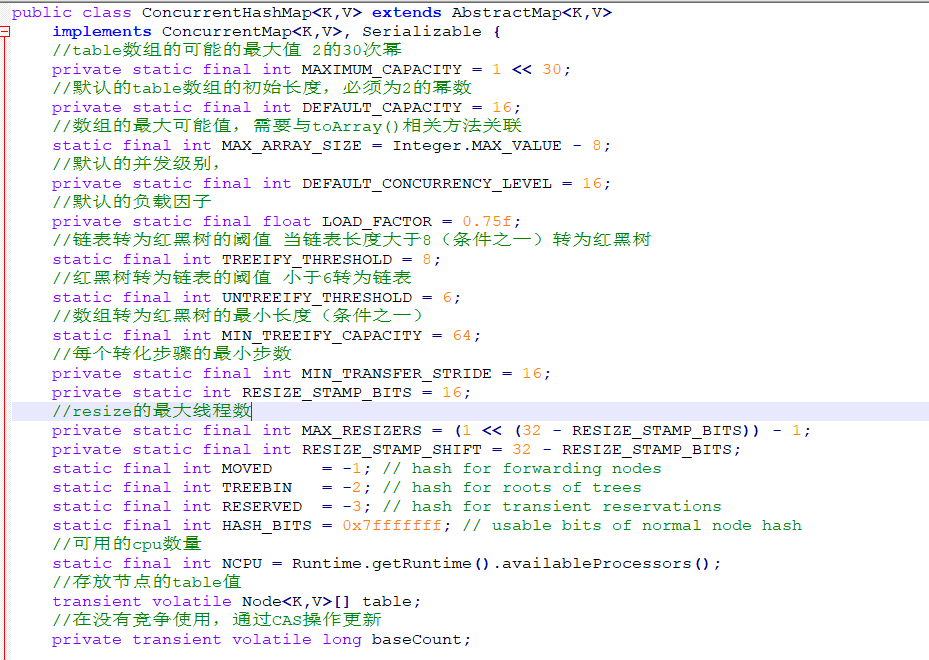
重要的属性

重要的方法put

1.7与1.8的区别
1.7数组+链表 1.8 数组+链表或红黑树
1.7 采用头插法 插入时,如果数组位置上已经有元素,将新元素放到数组中,原始节点作为新节点的后继节点 1.8尾插法 遍历链表,将元素放置到链表的最后
1.7 先判断是否需要扩容,再插入 1.8先进行插入,插入完成再判断是否需要扩容
1.7 扩容的时候需要对原数组中的元素进行重新hash定位在新数组的位置,1.8 采用更简单的判断逻辑,位置不变或索引+旧容量大小
好处是
-
防止发生hash冲突,链表长度过长,将时间复杂度由
O(n)降为O(logn); -
因为1.7头插法扩容时,头插法会使链表发生反转,多线程环境下会产生环;
ConcurrentHashMaP和HashMap put不同的地方(本质上1.8他们之间很像了)
并发控制使用了synchronized和CAS操作(使用了CAS加synchronized ,并非加在整个ConcurrentHashMap,而是对每个头节点分别加锁,即并发度,就是 Node数组的长度,初始长度为16。)。整体就像是线程安全的HashMap
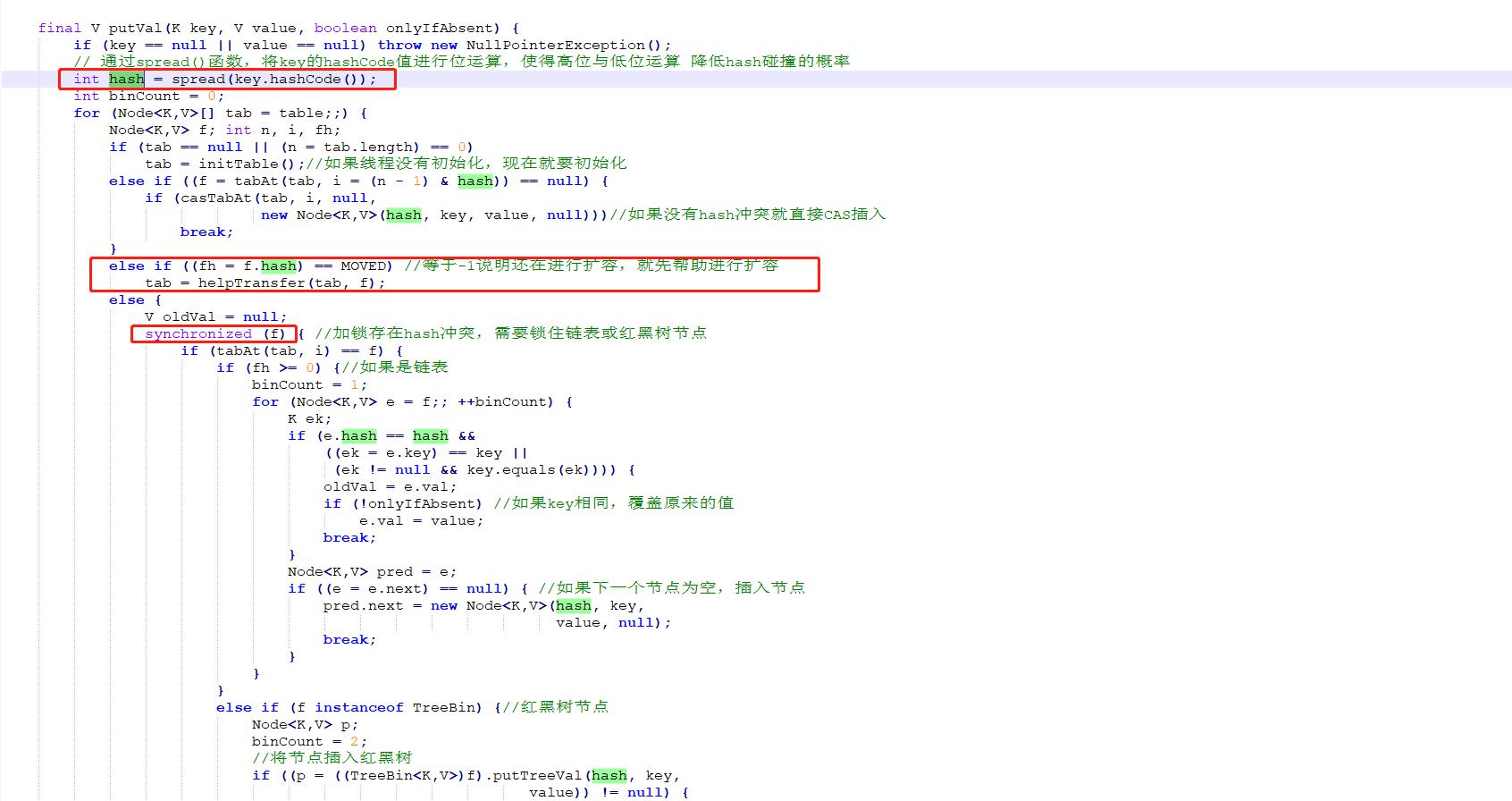
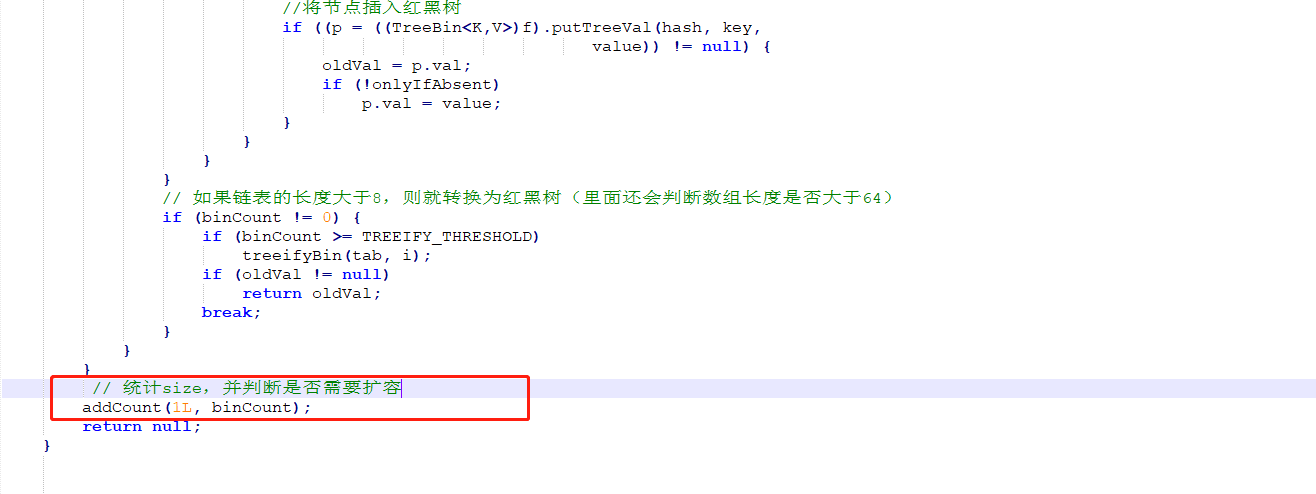
上面的for循环有4个大的分支:
第1个分支,是整个数组的初始化,
第2个分支,是所在的槽为空,说明该元素是该槽的第一个元素,直接新建一个头节点,然后返回;
第3个分支,说明该槽正在进行扩容,帮助其扩容;
第4个分支,就是把元素放入槽内。槽内可能是一个链表,也可能是一棵红黑树,通过头节点的类型 可以判断是哪一种。
第4个分支是包裹在synchronized (f)里面的,f对应的数组下标位置的头节点, 意味着每个数组元素有一把锁,并发度等于数组的长度。
重要的属性
构造方法

初始化table方法
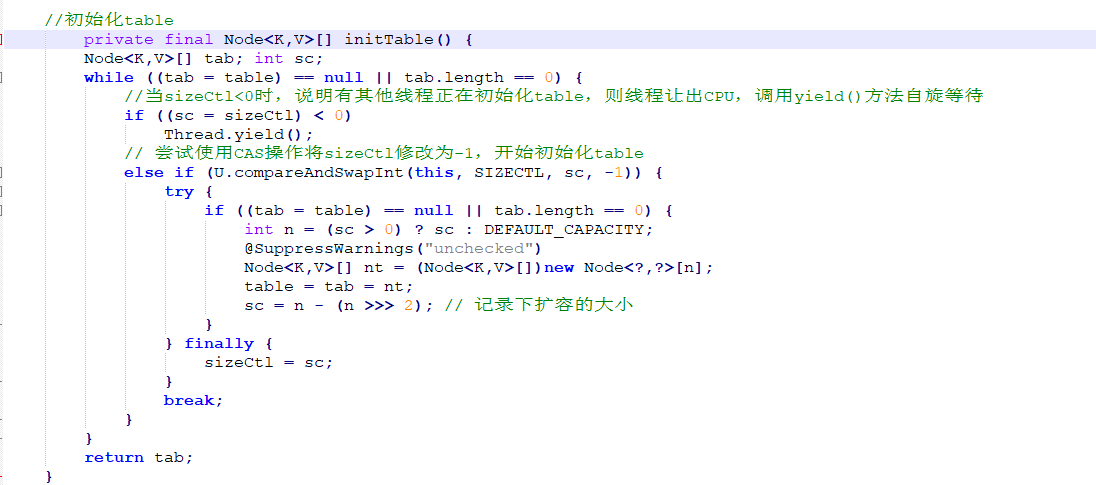
通过上面的代码可以看到,多个线程的竞争是通过对sizeCtl进行CAS操作实现的。如果某个线程成
功地把 sizeCtl 设置为-1,它就拥有了初始化的权利,进入初始化的代码模块,等到初始化完成,再把
sizeCtl设置回去;其他线程则一直执行while循环,自旋等待,直到数组不为null,即当初始化结束时,
退出整个方法。
因为初始化的工作量很小,所以此处选择的策略是让其他线程一直等待,而没有帮助其初始化。
红黑树转换
在这个方法内部,不一定需要进行红黑树转换,可能只做 扩容操作,所以接下来从扩容讲起。

在上面的代码中,MIN_TREEIFY_CAPACITY=64,意味着当数组的长度没有超过64的时候,数组的
每个节点里都是链表,只会扩容,不会转换成红黑树。只有当数组长度大于或等于64时,才考虑把链表
转换成红黑树。
//扩容方法
并发扩容,这是难度最大的。当一个线程要扩容Node数组的时候,其他线程还要读写
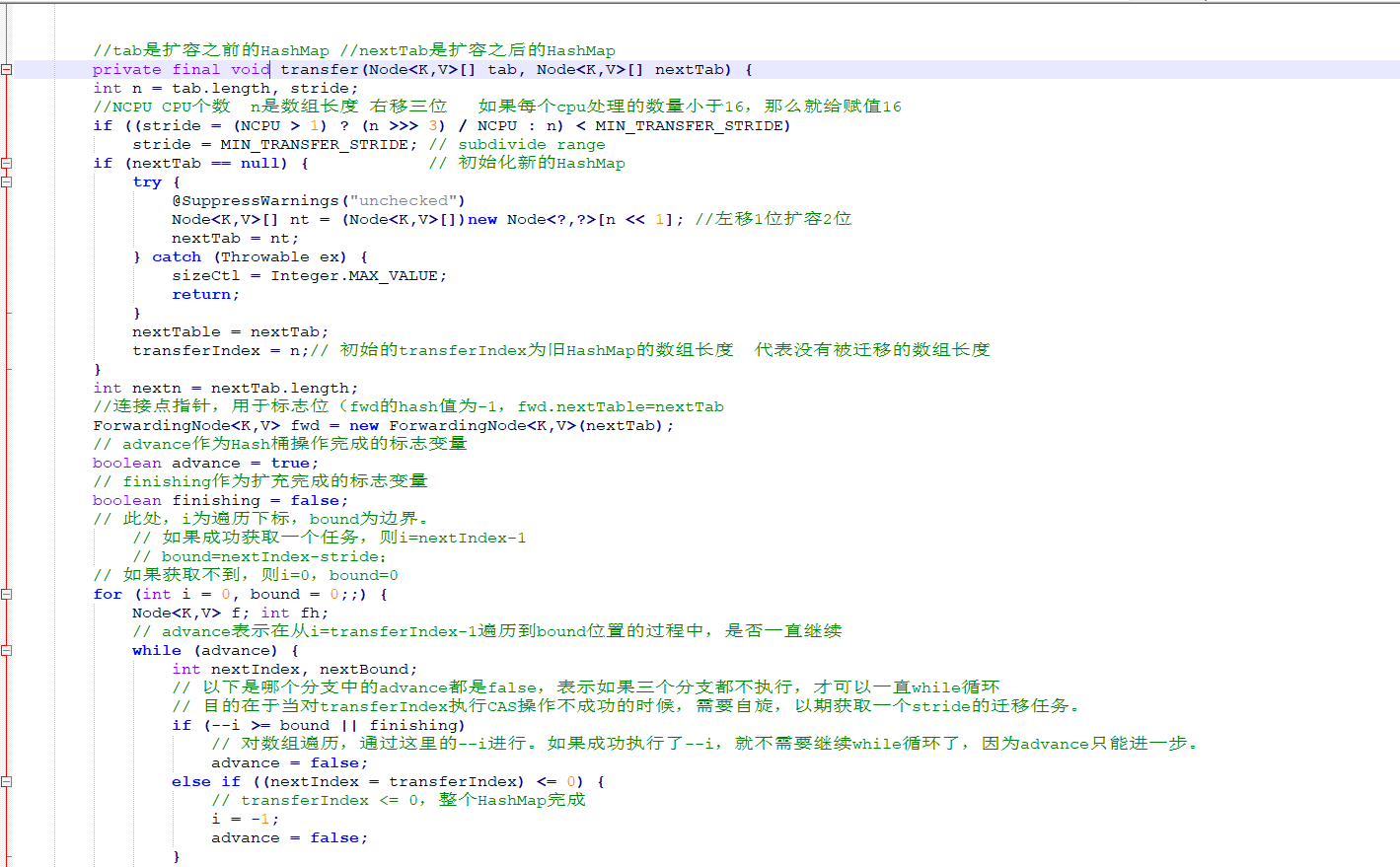


扩容的基本原理如下图,首先建一个新的HashMap,其数组长度是旧数组长度的2倍,然后把 旧的元素逐个迁移过来。所以,上面的方法参数有2个,第1个参数tab是扩容之前的 HashMap,第2个参数nextTab是扩容之后的HashMap。当nextTab=null的时候,方法最初 会对nextTab进行初始化。这里有一个关键点要说明:该方法会被多个线程调用,所以每个线 程只是扩容旧的HashMap部分,这就涉及如何划分任务的问题。
上图为多个线程并行扩容-任务划分示意图。旧数组的长度是N,每个线程扩容一段,一段的长 度用变量stride(步长)来表示,transferIndex表示了整个数组扩容的进度。 stride的计算公式如上面的代码所示,即:在单核模式下直接等于n,因为在单核模式下没有办 法多个线程并行扩容,只需要1个线程来扩容整个数组;在多核模式下为 (n>>> 3)/NCPU,并且保证步长的最小值是 16。显然,需要的线程个数约为n/stride。
transferIndex是ConcurrentHashMap的一个成员变量,记录了扩容的进度。初始值为n,从大到 小扩容,每次减stride个位置,最终减至n<=0,表示整个扩容完成。因此,从[0,transferIndex-1]的 位置表示还没有分配到线程扩容的部分,从[transfexIndex,n-1]的位置表示已经分配给某个线程进行扩 容,当前正在扩容中,或者已经扩容成功。 因为transferIndex会被多个线程并发修改,每次减stride,所以需要通过CAS进行操作,如下面的代码 所示。

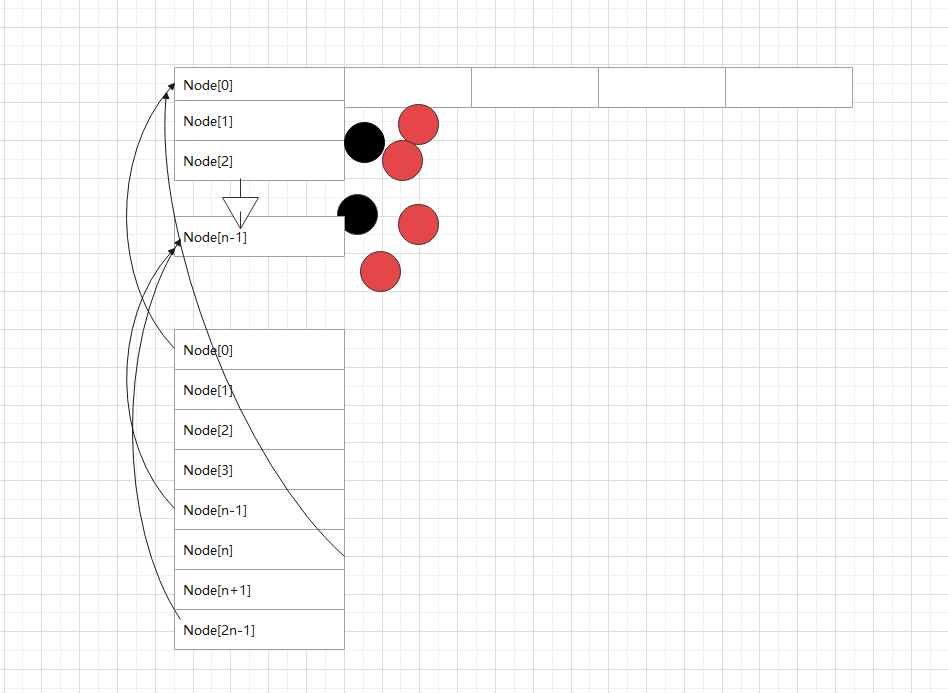
3. 在扩容未完成之前,有的数组下标对应的槽已经迁移到了新的HashMap里面,有的还在旧的 HashMap 里面。这个时候,所有调用 get(k,v)的线程还是会访问旧 HashMap,怎么处理 呢? 下图为扩容过程中的转发示意图:当Node[0]已经迁移成功,而其他Node还在迁移过程中时, 如果有线程要读取Node[0]的数据,就会访问失败。为此,新建一个ForwardingNode,即转 发节点,在这个节点里面记录的是新的 ConcurrentHashMap 的引用。这样,当线程访问到 ForwardingNode之后,会去查询新的ConcurrentHashMap。 4. 因为数组的长度 tab.length 是2的整数次方,每次扩容又是2倍。而 Hash 函数是 hashCode%tab.length,等价于hashCode&(tab.length-1)。这意味着:处于第i个位置的 元素,在新的Hash表的数组中一定处于第i个或者第i+n个位置,如下图所示。举个简单的例 子:假设数组长度是8,扩容之后是16: 若hashCode=5,5%8=0,扩容后,5%16=0,位置保持不变;若hashCode=24,24%8=0,扩容后,24%16=8,后移8个位置; 若hashCode=25,25%8=1,扩容后,25%16=9,后移8个位置; 若hashCode=39,39%8=7,扩容后,39%8=7,位置保持不变;也就是把tab[i]位置的链表或红黑树重新组装成两部分,一部分链接到nextTab[i]的位置,一部分链 接到nextTab[i+n]的位置,如上图所示。然后把tab[i]的位置指向一个ForwardingNode节点。 同时,当tab[i]后面是链表时,使用类似于JDK 7中在扩容时的优化方法,从lastRun往后的所有节 点,不需依次拷贝,而是直接链接到新的链表头部。从lastRun往前的所有节点,需要依次拷贝。
get方法

1. 首先通过spread方法计算hash值,定位到数组下标位置,首节点符合就返回值
2. 正在扩容,会调用ForwardingNode的find方法,查找,
3. 遍历查找,
get操作全程不需要加锁是因为Node的成员val是用volatile修饰的。
JDK 1.8的实现降低锁的颗粒度,JDK 1.7版本的锁的颗粒度是基于Segment,包含多个HashEntry;而JDK 1.8的锁的颗粒度就是HashEntry。
JDK 1.8版本的数据结构变得更加简单,使得操作也更加清晰。使用了synchronized来进行同步,不需要分段锁的概念,也就不再需要Segment这种数据结构,由于颗粒度的降低,实现的复杂度也增加了。
JDK 1,8使用红黑树来优化链表,红黑树的遍历速度是很快的,代替了一定阈值的链表。