这种情况多发生在6.1x版本的海蜘蛛。主页明明不是搜狗,点击后却跳出搜狗页面。许多人在网上提出了这个问题,一直没有好的解决办法。问题就出在这些破解的海蜘蛛上。
解决方法的思路是将流氓搜狗地址重定向到你想要的网址。经测试基本完美解决。下面是截图。
首先打开“服务管理”中web代理缓存。启用web缓存代理√,运行为透明代理模式√。自动跳转到指定页面√,延时填0,跳转目标网址根据自己的需要填写。

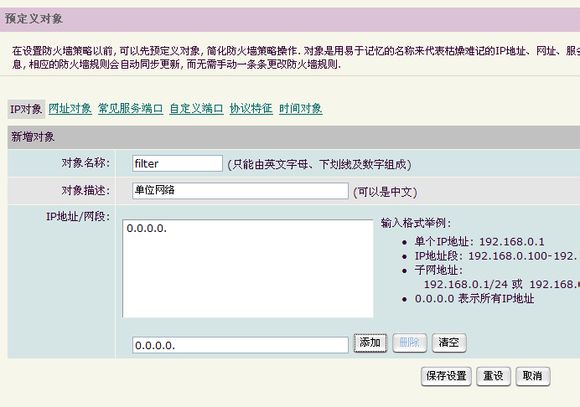
打开“上网行为管理”—“预定义对象”—“ip对象”,点新增对象,填上对象名称,对象描述,(参考格式举例)填上ip或ip段。我填的是0.0.0.0,表示对网络内的所有电脑都起作用。
填写完成后保存设置,这点不要忘记。
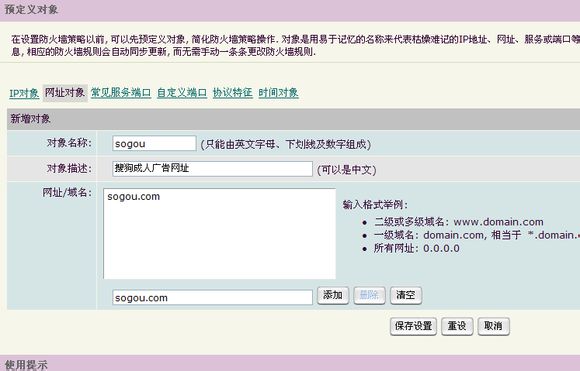
接着点“网址对象”,点新增对象,填上对象名称,对象描述,(参考格式举例)添加上域名。我填写的如下图,表示要kill掉含有如图字段的域名。不要忘记保存设置。
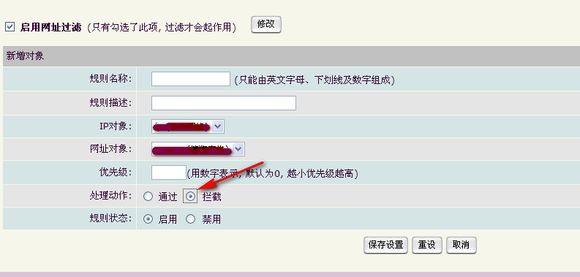
点开防火墙—过滤设置—网址过滤。再点“新增规则”,勾选网址过滤。动作处理选“拦截”,规则状态选“启用”。点保存设置。
最后不要忘记点“应用规则”。。。。。。。。。。。。。。。。。。。

应该ok了吧,如果不行重启一下。
这样做可能遇到的问题:
1.就是可能要跳转几次,才能跳转到我们希望的页面
2.经常出现无缘故网页打不开,dns服务重新载入就好