一内置函数
1 数学函数
|
Return Type |
Name (Signature) |
Description |
|---|---|---|
|
DOUBLE |
round(DOUBLE a) |
Returns the rounded 返回对a四舍五入的BIGINT值 |
|
DOUBLE |
round(DOUBLE a, INT d) |
Returns 返回DOUBLE型d的保留n位小数的DOUBLW型的近似值 |
| DOUBLE | bround(DOUBLE a) | Returns the rounded BIGINT value of a using HALF_EVEN rounding mode (as of Hive 1.3.0, 2.0.0). Also known as Gaussian rounding or bankers' rounding. Example: bround(2.5) = 2, bround(3.5) = 4.银行家舍入法(1~4:舍,6~9:进,5->前位数是偶:舍,5->前位数是奇:进) |
| DOUBLE | bround(DOUBLE a, INT d) | Returns a rounded to d decimal places using HALF_EVEN rounding mode (as of Hive 1.3.0, 2.0.0). Example: bround(8.25, 1) = 8.2, bround(8.35, 1) = 8.4.银行家舍入法,保留d位小数 |
|
BIGINT |
floor(DOUBLE a) |
Returns the maximum 向下取整,最数轴上最接近要求的值的左边的值 如:6.10->6 -3.4->-4 |
|
BIGINT |
ceil(DOUBLE a), ceiling(DOUBLE a) |
Returns the minimum BIGINT value that is equal to or greater than 求其不小于小给定实数的最小整数如:ceil(6) = ceil(6.1)= ceil(6.9) = 6 |
|
DOUBLE |
rand(), rand(INT seed) |
Returns a random number (that changes from row to row) that is distributed uniformly from 0 to 1. Specifying the seed will make sure the generated random number sequence is deterministic. 每行返回一个DOUBLE型随机数seed是随机因子 |
|
DOUBLE |
exp(DOUBLE a), exp(DECIMAL a) |
Returns 返回e的a幂次方, a可为小数 |
|
DOUBLE |
ln(DOUBLE a), ln(DECIMAL a) |
Returns the natural logarithm of the argument 以自然数为底d的对数,a可为小数 |
|
DOUBLE |
log10(DOUBLE a), log10(DECIMAL a) |
Returns the base-10 logarithm of the argument 以10为底d的对数,a可为小数 |
|
DOUBLE |
log2(DOUBLE a), log2(DECIMAL a) |
Returns the base-2 logarithm of the argument 以2为底数d的对数,a可为小数 |
|
DOUBLE |
log(DOUBLE base, DOUBLE a) log(DECIMAL base, DECIMAL a) |
Returns the base- 以base为底的对数,base 与 a都是DOUBLE类型 |
|
DOUBLE |
pow(DOUBLE a, DOUBLE p), power(DOUBLE a, DOUBLE p) |
Returns 计算a的p次幂 |
|
DOUBLE |
sqrt(DOUBLE a), sqrt(DECIMAL a) |
Returns the square root of 计算a的平方根 |
|
STRING |
bin(BIGINT a) |
Returns the number in binary format (see http://dev.mysql.com/doc/refman/5.0/en/string-functions.html#function_bin). 计算二进制a的STRING类型,a为BIGINT类型 |
|
STRING |
hex(BIGINT a) hex(STRING a) hex(BINARY a) |
If the argument is an 计算十六进制a的STRING类型,如果a为STRING类型就转换成字符相对应的十六进制 |
|
BINARY |
unhex(STRING a) |
Inverse of hex. Interprets each pair of characters as a hexadecimal number and converts to the byte representation of the number. ( hex的逆方法 |
|
STRING |
conv(BIGINT num, INT from_base, INT to_base), conv(STRING num, INT from_base, INT to_base) |
Converts a number from a given base to another (see http://dev.mysql.com/doc/refman/5.0/en/mathematical-functions.html#function_conv). 将GIGINT/STRING类型的num从from_base进制转换成to_base进制 |
|
DOUBLE |
abs(DOUBLE a) |
Returns the absolute value. 计算a的绝对值 |
|
INT or DOUBLE |
pmod(INT a, INT b), pmod(DOUBLE a, DOUBLE b) |
Returns the positive value of a对b取模 |
|
DOUBLE |
sin(DOUBLE a), sin(DECIMAL a) |
Returns the sine of 求a的正弦值 |
|
DOUBLE |
asin(DOUBLE a), asin(DECIMAL a) |
Returns the arc sin of 求d的反正弦值 |
|
DOUBLE |
cos(DOUBLE a), cos(DECIMAL a) |
Returns the cosine of 求余弦值 |
|
DOUBLE |
acos(DOUBLE a), acos(DECIMAL a) |
Returns the arccosine of 求反余弦值 |
|
DOUBLE |
tan(DOUBLE a), tan(DECIMAL a) |
Returns the tangent of 求正切值 |
|
DOUBLE |
atan(DOUBLE a), atan(DECIMAL a) |
Returns the arctangent of 求反正切值 |
|
DOUBLE |
degrees(DOUBLE a), degrees(DECIMAL a) |
Converts value of 奖弧度值转换角度值 |
|
DOUBLE |
radians(DOUBLE a), radians(DOUBLE a) |
Converts value of 将角度值转换成弧度值 |
|
INT or DOUBLE |
positive(INT a), positive(DOUBLE a) |
Returns 返回a |
|
INT or DOUBLE |
negative(INT a), negative(DOUBLE a) |
Returns 返回a的相反数 |
|
DOUBLE or INT |
sign(DOUBLE a), sign(DECIMAL a) |
Returns the sign of 如果a是正数则返回1.0,是负数则返回-1.0,否则返回0.0 |
|
DOUBLE |
e() |
Returns the value of 数学常数e |
|
DOUBLE |
pi() |
Returns the value of 数学常数pi |
| BIGINT | factorial(INT a) | Returns the factorial of a (as of Hive 1.2.0). Valid a is [0..20].求a的阶乘 |
| DOUBLE | cbrt(DOUBLE a) | Returns the cube root of a double value (as of Hive 1.2.0).求a的立方根 |
|
INT BIGINT |
shiftleft(TINYINT|SMALLINT|INT a, INT b) shiftleft(BIGINT a, INT b) |
Bitwise left shift (as of Hive 1.2.0). Shifts Returns int for tinyint, smallint and int 按位左移 |
|
INT BIGINT |
shiftright(TINYINT|SMALLINT|INT a, INTb) shiftright(BIGINT a, INT b) |
Bitwise right shift (as of Hive 1.2.0). Shifts Returns int for tinyint, smallint and int 按拉右移 |
|
INT BIGINT |
shiftrightunsigned(TINYINT|SMALLINT|INTa, INT b), shiftrightunsigned(BIGINT a, INT b) |
Bitwise unsigned right shift (as of Hive 1.2.0). Shifts Returns int for tinyint, smallint and int 无符号按位右移(<<<) |
| T | greatest(T v1, T v2, ...) | Returns the greatest value of the list of values (as of Hive 1.1.0). Fixed to return NULL when one or more arguments are NULL, and strict type restriction relaxed, consistent with ">" operator (as of Hive 2.0.0). 求最大值 |
| T | least(T v1, T v2, ...) | Returns the least value of the list of values (as of Hive 1.1.0). Fixed to return NULL when one or more arguments are NULL, and strict type restriction relaxed, consistent with "<" operator (as of Hive 2.0.0). 求最小值 |
2 集合函数
|
Return Type |
Name(Signature) |
Description |
|---|---|---|
|
int |
size(Map<K.V>) |
Returns the number of elements in the map type. 求map的长度 |
|
int |
size(Array<T>) |
Returns the number of elements in the array type. 求数组的长度 |
|
array<K> |
map_keys(Map<K.V>) |
Returns an unordered array containing the keys of the input map. 返回map中的所有key |
|
array<V> |
map_values(Map<K.V>) |
Returns an unordered array containing the values of the input map. 返回map中的所有value |
|
boolean |
array_contains(Array<T>, value) |
Returns TRUE if the array contains value. 如该数组Array<T>包含value返回true。,否则返回false |
|
array |
sort_array(Array<T>) |
Sorts the input array in ascending order according to the natural ordering of the array elements and returns it (as of version 0.9.0). 按自然顺序对数组进行排序并返回 |
3 类型转换函数
|
Return Type |
Name(Signature) |
Description |
|---|---|---|
|
binary |
binary(string|binary) |
Casts the parameter into a binary. 将输入的值转换成二进制 |
|
Expected "=" to follow "type" |
cast(expr as <type>) |
Converts the results of the expression expr to <type>. For example, cast('1' as BIGINT) will convert the string '1' to its integral representation. A null is returned if the conversion does not succeed. If cast(expr as boolean) Hive returns true for a non-empty string. 将expr转换成type类型 如:cast("1" as BIGINT) 将字符串1转换成了BIGINT类型,如果转换失败将返回NULL |
4 日期函数
|
Return Type |
Name(Signature) |
Description |
|---|---|---|
|
string |
from_unixtime(bigint unixtime[, string format]) |
Converts the number of seconds from unix epoch (1970-01-01 00:00:00 UTC) to a string representing the timestamp of that moment in the current system time zone in the format of "1970-01-01 00:00:00". 将时间的秒值转换成format格式(format可为“yyyy-MM-dd hh:mm:ss”,“yyyy-MM-dd hh”,“yyyy-MM-dd hh:mm”等等)如from_unixtime(1250111000,"yyyy-MM-dd") 得到2009-03-12 |
|
bigint |
unix_timestamp() |
Gets current Unix timestamp in seconds. 获取本地时区下的时间戳 |
|
bigint |
unix_timestamp(string date) |
Converts time string in format 将格式为yyyy-MM-dd HH:mm:ss的时间字符串转换成时间戳 如unix_timestamp('2009-03-20 11:30:01') = 1237573801 |
|
bigint |
unix_timestamp(string date, string pattern) |
Convert time string with given pattern (see [http://docs.oracle.com/javase/tutorial/i18n/format/simpleDateFormat.html]) to Unix time stamp (in seconds), return 0 if fail: unix_timestamp('2009-03-20', 'yyyy-MM-dd') = 1237532400. 将指定时间字符串格式字符串转换成Unix时间戳,如果格式不对返回0 如:unix_timestamp('2009-03-20', 'yyyy-MM-dd') = 1237532400 |
|
string |
to_date(string timestamp) |
Returns the date part of a timestamp string: to_date("1970-01-01 00:00:00") = "1970-01-01". 返回时间字符串的日期部分 |
|
int |
year(string date) |
Returns the year part of a date or a timestamp string: year("1970-01-01 00:00:00") = 1970, year("1970-01-01") = 1970. 返回时间字符串的年份部分 |
| int | quarter(date/timestamp/string) | Returns the quarter of the year for a date, timestamp, or string in the range 1 to 4 (as of Hive 1.3.0). Example: quarter('2015-04-08') = 2.
返回当前时间属性哪个季度 如quarter('2015-04-08') = 2 |
|
int |
month(string date) |
Returns the month part of a date or a timestamp string: month("1970-11-01 00:00:00") = 11, month("1970-11-01") = 11. 返回时间字符串的月份部分 |
|
int |
day(string date) dayofmonth(date) |
Returns the day part of a date or a timestamp string: day("1970-11-01 00:00:00") = 1, day("1970-11-01") = 1. 返回时间字符串的天 |
|
int |
hour(string date) |
Returns the hour of the timestamp: hour('2009-07-30 12:58:59') = 12, hour('12:58:59') = 12. 返回时间字符串的小时 |
|
int |
minute(string date) |
Returns the minute of the timestamp. 返回时间字符串的分钟 |
|
int |
second(string date) |
Returns the second of the timestamp. 返回时间字符串的秒 |
|
int |
weekofyear(string date) |
Returns the week number of a timestamp string: weekofyear("1970-11-01 00:00:00") = 44, weekofyear("1970-11-01") = 44. 返回时间字符串位于一年中的第几个周内 如weekofyear("1970-11-01 00:00:00") = 44, weekofyear("1970-11-01") = 44 |
|
int |
datediff(string enddate, string startdate) |
Returns the number of days from startdate to enddate: datediff('2009-03-01', '2009-02-27') = 2. 计算开始时间startdate到结束时间enddate相差的天数 |
|
string |
date_add(string startdate, int days) |
Adds a number of days to startdate: date_add('2008-12-31', 1) = '2009-01-01'. 从开始时间startdate加上days |
|
string |
date_sub(string startdate, int days) |
Subtracts a number of days to startdate: date_sub('2008-12-31', 1) = '2008-12-30'. 从开始时间startdate减去days |
|
timestamp |
from_utc_timestamp(timestamp, string timezone) |
Assumes given timestamp is UTC and converts to given timezone (as of Hive 0.8.0). For example, from_utc_timestamp('1970-01-01 08:00:00','PST') returns 1970-01-01 00:00:00. 如果给定的时间戳并非UTC,则将其转化成指定的时区下时间戳 |
|
timestamp |
to_utc_timestamp(timestamp, string timezone) |
Assumes given timestamp is in given timezone and converts to UTC (as of Hive 0.8.0). For example, to_utc_timestamp('1970-01-01 00:00:00','PST') returns 1970-01-01 08:00:00. 如果给定的时间戳指定的时区下时间戳,则将其转化成UTC下的时间戳 |
| date | current_date |
Returns the current date at the start of query evaluation (as of Hive 1.2.0). All calls of current_date within the same query return the same value. 返回当前时间日期 |
| timestamp | current_timestamp |
Returns the current timestamp at the start of query evaluation (as of Hive 1.2.0). All calls of current_timestamp within the same query return the same value. 返回当前时间戳 |
| string | add_months(string start_date, int num_months) |
Returns the date that is num_months after start_date (as of Hive 1.1.0). start_date is a string, date or timestamp. num_months is an integer. The time part of start_date is ignored. If start_date is the last day of the month or if the resulting month has fewer days than the day component of start_date, then the result is the last day of the resulting month. Otherwise, the result has the same day component as start_date. 返回当前时间下再增加num_months个月的日期 |
| string | last_day(string date) | Returns the last day of the month which the date belongs to (as of Hive 1.1.0). date is a string in the format 'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'. The time part of date is ignored.
返回这个月的最后一天的日期,忽略时分秒部分(HH:mm:ss) |
| string | next_day(string start_date, string day_of_week) | Returns the first date which is later than start_date and named as day_of_week (as of Hive1.2.0). start_date is a string/date/timestamp. day_of_week is 2 letters, 3 letters or full name of the day of the week (e.g. Mo, tue, FRIDAY). The time part of start_date is ignored. Example: next_day('2015-01-14', 'TU') = 2015-01-20.
返回当前时间的下一个星期X所对应的日期 如:next_day('2015-01-14', 'TU') = 2015-01-20 以2015-01-14为开始时间,其下一个星期二所对应的日期为2015-01-20 |
| string | trunc(string date, string format) | Returns date truncated to the unit specified by the format (as of Hive 1.2.0). Supported formats: MONTH/MON/MM, YEAR/YYYY/YY. Example: trunc('2015-03-17', 'MM') = 2015-03-01.
返回时间的最开始年份或月份 如trunc("2016-06-26",“MM”)=2016-06-01 trunc("2016-06-26",“YY”)=2016-01-01 注意所支持的格式为MONTH/MON/MM, YEAR/YYYY/YY |
| double | months_between(date1, date2) | Returns number of months between dates date1 and date2 (as of Hive 1.2.0). If date1 is later than date2, then the result is positive. If date1 is earlier than date2, then the result is negative. If date1 and date2 are either the same days of the month or both last days of months, then the result is always an integer. Otherwise the UDF calculates the fractional portion of the result based on a 31-day month and considers the difference in time components date1 and date2. date1 and date2 type can be date, timestamp or string in the format 'yyyy-MM-dd' or 'yyyy-MM-dd HH:mm:ss'. The result is rounded to 8 decimal places. Example: months_between('1997-02-28 10:30:00', '1996-10-30') = 3.94959677
返回date1与date2之间相差的月份,如date1>date2,则返回正,如果date1<date2,则返回负,否则返回0.0 如:months_between('1997-02-28 10:30:00', '1996-10-30') = 3.94959677 1997-02-28 10:30:00与1996-10-30相差3.94959677个月 |
| string | date_format(date/timestamp/string ts, string fmt) |
Converts a date/timestamp/string to a value of string in the format specified by the date format fmt (as of Hive 1.2.0). Supported formats are Java SimpleDateFormat formats –https://docs.oracle.com/javase/7/docs/api/java/text/SimpleDateFormat.html. The second argument fmt should be constant. Example: date_format('2015-04-08', 'y') = '2015'. date_format can be used to implement other UDFs, e.g.:
|
5 条件函数
|
Return Type |
Name(Signature) |
Description |
|---|---|---|
|
T |
if(boolean testCondition, T valueTrue, T valueFalseOrNull) |
Returns valueTrue when testCondition is true, returns valueFalseOrNull otherwise. 如果testCondition 为true就返回valueTrue,否则返回valueFalseOrNull ,(valueTrue,valueFalseOrNull为泛型) |
| T | nvl(T value, T default_value) | Returns default value if value is null else returns value (as of HIve 0.11).
如果value值为NULL就返回default_value,否则返回value |
|
T |
COALESCE(T v1, T v2, ...) |
Returns the first v that is not NULL, or NULL if all v's are NULL. 返回第一非null的值,如果全部都为NULL就返回NULL 如:COALESCE (NULL,44,55)=44/strong> |
|
T |
CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END |
When a = b, returns c; when a = d, returns e; else returns f. 如果a=b就返回c,a=d就返回e,否则返回f 如CASE 4 WHEN 5 THEN 5 WHEN 4 THEN 4 ELSE 3 END 将返回4 |
|
T |
CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END |
When a = true, returns b; when c = true, returns d; else returns e. 如果a=ture就返回b,c= ture就返回d,否则返回e 如:CASE WHEN 5>0 THEN 5 WHEN 4>0 THEN 4 ELSE 0 END 将返回5;CASE WHEN 5<0 THEN 5 WHEN 4<0 THEN 4 ELSE 0 END 将返回0 |
| boolean | isnull( a ) | Returns true if a is NULL and false otherwise.
如果a为null就返回true,否则返回false |
| boolean | isnotnull ( a ) | Returns true if a is not NULL and false otherwise.
如果a为非null就返回true,否则返回false |
6 字符函数
|
Return Type |
Name(Signature) |
Description |
|---|---|---|
|
int |
ascii(string str) |
Returns the numeric value of the first character of str. 返回str中首个ASCII字符串的整数值 |
|
string |
base64(binary bin) |
Converts the argument from binary to a base 64 string (as of Hive 0.12.0).. 将二进制bin转换成64位的字符串 |
|
string |
concat(string|binary A, string|binary B...) |
Returns the string or bytes resulting from concatenating the strings or bytes passed in as parameters in order. For example, concat('foo', 'bar') results in 'foobar'. Note that this function can take any number of input strings.. 对二进制字节码或字符串按次序进行拼接 |
|
array<struct<string,double>> |
context_ngrams(array<array<string>>, array<string>, int K, int pf) |
Returns the top-k contextual N-grams from a set of tokenized sentences, given a string of "context". See StatisticsAndDataMining for more information.. 与ngram类似,但context_ngram()允许你预算指定上下文(数组)来去查找子序列,具体看StatisticsAndDataMining(这里的解释更易懂) |
|
string |
concat_ws(string SEP, string A, string B...) |
Like concat() above, but with custom separator SEP.. 与concat()类似,但使用指定的分隔符喜进行分隔 |
|
string |
concat_ws(string SEP, array<string>) |
Like concat_ws() above, but taking an array of strings. (as of Hive 0.9.0). 拼接Array中的元素并用指定分隔符进行分隔 |
|
string |
decode(binary bin, string charset) |
Decodes the first argument into a String using the provided character set (one of 'US-ASCII', 'ISO-8859-1', 'UTF-8', 'UTF-16BE', 'UTF-16LE', 'UTF-16'). If either argument is null, the result will also be null. (As of Hive 0.12.0.). 使用指定的字符集charset将二进制值bin解码成字符串,支持的字符集有:'US-ASCII', 'ISO-8859-1', 'UTF-8', 'UTF-16BE', 'UTF-16LE', 'UTF-16',如果任意输入参数为NULL都将返回NULL |
|
binary |
encode(string src, string charset) |
Encodes the first argument into a BINARY using the provided character set (one of 'US-ASCII', 'ISO-8859-1', 'UTF-8', 'UTF-16BE', 'UTF-16LE', 'UTF-16'). If either argument is null, the result will also be null. (As of Hive 0.12.0.). 使用指定的字符集charset将字符串编码成二进制值,支持的字符集有:'US-ASCII', 'ISO-8859-1', 'UTF-8', 'UTF-16BE', 'UTF-16LE', 'UTF-16',如果任一输入参数为NULL都将返回NULL |
|
int |
find_in_set(string str, string strList) |
Returns the first occurance of str in strList where strList is a comma-delimited string. Returns null if either argument is null. Returns 0 if the first argument contains any commas. For example, find_in_set('ab', 'abc,b,ab,c,def') returns 3.. 返回以逗号分隔的字符串中str出现的位置,如果参数str为逗号或查找失败将返回0,如果任一参数为NULL将返回NULL回 |
|
string |
format_number(number x, int d) |
Formats the number X to a format like '#,###,###.##', rounded to D decimal places, and returns the result as a string. If D is 0, the result has no decimal point or fractional part. (As of Hive 0.10.0; bug with float types fixed in Hive 0.14.0, decimal type support added in Hive 0.14.0). 将数值X转换成"#,###,###.##"格式字符串,并保留d位小数,如果d为0,将进行四舍五入且不保留小数 |
|
string |
get_json_object(string json_string, string path) |
Extracts json object from a json string based on json path specified, and returns json string of the extracted json object. It will return null if the input json string is invalid. NOTE: The json path can only have the characters [0-9a-z_], i.e., no upper-case or special characters. Also, the keys *cannot start with numbers.* This is due to restrictions on Hive column names.. 从指定路径上的JSON字符串抽取出JSON对象,并返回这个对象的JSON格式,如果输入的JSON是非法的将返回NULL,注意此路径上JSON字符串只能由数字 字母 下划线组成且不能有大写字母和特殊字符,且key不能由数字开头,这是由于Hive对列名的限制 |
|
boolean |
in_file(string str, string filename) |
Returns true if the string str appears as an entire line in filename.. 如果文件名为filename的文件中有一行数据与字符串str匹配成功就返回true |
|
int |
instr(string str, string substr) |
Returns the position of the first occurrence of 查找字符串str中子字符串substr出现的位置,如果查找失败将返回0,如果任一参数为Null将返回null,注意位置为从1开始的 |
|
int |
length(string A) |
Returns the length of the string.. 返回字符串的长度 |
|
int |
locate(string substr, string str[, int pos]) |
Returns the position of the first occurrence of substr in str after position pos.. 查找字符串str中的pos位置后字符串substr第一次出现的位置 |
|
string |
lower(string A) lcase(string A) |
Returns the string resulting from converting all characters of B to lower case. For example, lower('fOoBaR') results in 'foobar'.. 将字符串A的所有字母转换成小写字母 |
|
string |
lpad(string str, int len, string pad) |
Returns str, left-padded with pad to a length of len.. 从左边开始对字符串str使用字符串pad填充,最终len长度为止,如果字符串str本身长度比len大的话,将去掉多余的部分 |
|
string |
ltrim(string A) |
Returns the string resulting from trimming spaces from the beginning(left hand side) of A. For example, ltrim(' foobar ') results in 'foobar '.. 去掉字符串A前面的空格 |
|
array<struct<string,double>> |
ngrams(array<array<string>>, int N, int K, int pf) |
Returns the top-k N-grams from a set of tokenized sentences, such as those returned by the sentences() UDAF. See StatisticsAndDataMining for more information.. 返回出现次数TOP K的的子序列,n表示子序列的长度,具体看StatisticsAndDataMining (这里的解释更易懂) |
|
string |
parse_url(string urlString, string partToExtract [, string keyToExtract]) |
Returns the specified part from the URL. Valid values for partToExtract include HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO. For example, parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST') returns 'facebook.com'. Also a value of a particular key in QUERY can be extracted by providing the key as the third argument, for example, parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'QUERY', 'k1') returns 'v1'.. 返回从URL中抽取指定部分的内容,参数url是URL字符串,而参数partToExtract是要抽取的部分,这个参数包含(HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO,例如:parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST') ='facebook.com',如果参数partToExtract值为QUERY则必须指定第三个参数key 如:parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'QUERY', 'k1') =‘v1’ |
|
string |
printf(String format, Obj... args) |
Returns the input formatted according do printf-style format strings (as of Hive0.9.0).. 按照printf风格格式输出字符串 |
|
string |
regexp_extract(string subject, string pattern, int index) |
Returns the string extracted using the pattern. For example, regexp_extract('foothebar', 'foo(.*?)(bar)', 2) returns 'bar.' Note that some care is necessary in using predefined character classes: using 's' as the second argument will match the letter s; '\s' is necessary to match whitespace, etc. The 'index' parameter is the Java regex Matcher group() method index. See docs/api/java/util/regex/Matcher.html for more information on the 'index' or Java regex group() method.. 抽取字符串subject中符合正则表达式pattern的第index个部分的子字符串,注意些预定义字符的使用,如第二个参数如果使用's'将被匹配到s,'\s'才是匹配空格 |
|
string |
regexp_replace(string INITIAL_STRING, string PATTERN, string REPLACEMENT) |
Returns the string resulting from replacing all substrings in INITIAL_STRING that match the java regular expression syntax defined in PATTERN with instances of REPLACEMENT. For example, regexp_replace("foobar", "oo|ar", "") returns 'fb.' Note that some care is necessary in using predefined character classes: using 's' as the second argument will match the letter s; '\s' is necessary to match whitespace, etc.. 按照Java正则表达式PATTERN将字符串INTIAL_STRING中符合条件的部分成REPLACEMENT所指定的字符串,如里REPLACEMENT这空的话,抽符合正则的部分将被去掉 如:regexp_replace("foobar", "oo|ar", "") = 'fb.' 注意些预定义字符的使用,如第二个参数如果使用's'将被匹配到s,'\s'才是匹配空格 |
|
string |
repeat(string str, int n) |
Repeats str n times.. 重复输出n次字符串str |
|
string |
reverse(string A) |
Returns the reversed string.. 反转字符串 |
|
string |
rpad(string str, int len, string pad) |
Returns str, right-padded with pad to a length of len.. 从右边开始对字符串str使用字符串pad填充,最终len长度为止,如果字符串str本身长度比len大的话,将去掉多余的部分 |
|
string |
rtrim(string A) |
Returns the string resulting from trimming spaces from the end(right hand side) of A. For example, rtrim(' foobar ') results in ' foobar'.. 去掉字符串后面出现的空格 |
|
array<array<string>> |
sentences(string str, string lang, string locale) |
Tokenizes a string of natural language text into words and sentences, where each sentence is broken at the appropriate sentence boundary and returned as an array of words. The 'lang' and 'locale' are optional arguments. For example, sentences('Hello there! How are you?') returns ( ("Hello", "there"), ("How", "are", "you") ).. 字符串str将被转换成单词数组,如:sentences('Hello there! How are you?') =( ("Hello", "there"), ("How", "are", "you") ) |
|
string |
space(int n) |
Returns a string of n spaces.. 返回n个空格 |
|
array |
split(string str, string pat) |
Splits str around pat (pat is a regular expression).. 按照正则表达式pat来分割字符串str,并将分割后的数组字符串的形式返回 |
|
map<string,string> |
str_to_map(text[, delimiter1, delimiter2]) |
Splits text into key-value pairs using two delimiters. Delimiter1 separates text into K-V pairs, and Delimiter2 splits each K-V pair. Default delimiters are ',' for delimiter1 and '=' for delimiter2.. 将字符串str按照指定分隔符转换成Map,第一个参数是需要转换字符串,第二个参数是键值对之间的分隔符,默认为逗号;第三个参数是键值之间的分隔符,默认为"=" |
|
string |
substr(string|binary A, int start) substring(string|binary A, int start) |
Returns the substring or slice of the byte array of A starting from start position till the end of string A. For example, substr('foobar', 4) results in 'bar' (see [http://dev.mysql.com/doc/refman/5.0/en/string-functions.html#function_substr]).. 对于字符串A,从start位置开始截取字符串并返回 |
|
string |
substr(string|binary A, int start, int len) substring(string|binary A, int start, int len) |
Returns the substring or slice of the byte array of A starting from start position with length len. For example, substr('foobar', 4, 1) results in 'b' (see [http://dev.mysql.com/doc/refman/5.0/en/string-functions.html#function_substr]).. 对于二进制/字符串A,从start位置开始截取长度为length的字符串并返回 |
| string | substring_index(string A, string delim, int count) | Returns the substring from string A before count occurrences of the delimiter delim (as of Hive 1.3.0). If count is positive, everything to the left of the final delimiter (counting from the left) is returned. If count is negative, everything to the right of the final delimiter (counting from the right) is returned. Substring_index performs a case-sensitive match when searching for delim. Example: substring_index('www.apache.org', '.', 2) = 'www.apache'..
截取第count分隔符之前的字符串,如count为正则从左边开始截取,如果为负则从右边开始截取 |
|
string |
translate(string|char|varchar input, string|char|varchar from, string|char|varchar to) |
Translates the input string by replacing the characters present in the Char/varchar support added as of Hive 0.14.0.. 将input出现在from中的字符串替换成to中的字符串 如:translate("MOBIN","BIN","M")="MOM" |
|
string |
trim(string A) |
Returns the string resulting from trimming spaces from both ends of A. For example, trim(' foobar ') results in 'foobar'. 将字符串A前后出现的空格去掉 |
|
binary |
unbase64(string str) |
Converts the argument from a base 64 string to BINARY. (As of Hive 0.12.0.). 将64位的字符串转换二进制值 |
|
string |
upper(string A) ucase(string A) |
Returns the string resulting from converting all characters of A to upper case. For example, upper('fOoBaR') results in 'FOOBAR'.. 将字符串A中的字母转换成大写字母 |
| string | initcap(string A) | Returns string, with the first letter of each word in uppercase, all other letters in lowercase. Words are delimited by whitespace. (As of Hive 1.1.0.).
将字符串A转换第一个字母大写其余字母的字符串 |
| int | levenshtein(string A, string B) | Returns the Levenshtein distance between two strings (as of Hive 1.2.0). For example, levenshtein('kitten', 'sitting') results in 3..
计算两个字符串之间的差异大小 如:levenshtein('kitten', 'sitting') = 3 |
| string | soundex(string A) | Returns soundex code of the string (as of Hive 1.2.0). For example, soundex('Miller') results in M460..
将普通字符串转换成soundex字符串 |
7 聚合函数
|
Return Type |
Name(Signature) |
Description |
|---|---|---|
|
BIGINT |
count(*), count(expr), count(DISTINCT expr[, expr...]) |
count(*) - Returns the total number of retrieved rows, including rows containing NULL values. 统计总行数,包括含有NULL值的行 count(expr) - Returns the number of rows for which the supplied expression is non-NULL. 统计提供非NULL的expr表达式值的行数 count(DISTINCT expr[, expr]) - Returns the number of rows for which the supplied expression(s) are unique and non-NULL. Execution of this can be optimized with hive.optimize.distinct.rewrite. 统计提供非NULL且去重后的expr表达式值的行数 |
|
DOUBLE |
sum(col), sum(DISTINCT col) |
Returns the sum of the elements in the group or the sum of the distinct values of the column in the group. sum(col),表示求指定列的和,sum(DISTINCT col)表示求去重后的列的和 |
|
DOUBLE |
avg(col), avg(DISTINCT col) |
Returns the average of the elements in the group or the average of the distinct values of the column in the group. avg(col),表示求指定列的平均值,avg(DISTINCT col)表示求去重后的列的平均值 |
|
DOUBLE |
min(col) |
Returns the minimum of the column in the group. 求指定列的最小值 |
|
DOUBLE |
max(col) |
Returns the maximum value of the column in the group. 求指定列的最大值 |
|
DOUBLE |
variance(col), var_pop(col) |
Returns the variance of a numeric column in the group. 求指定列数值的方差 |
|
DOUBLE |
var_samp(col) |
Returns the unbiased sample variance of a numeric column in the group. 求指定列数值的样本方差 |
|
DOUBLE |
stddev_pop(col) |
Returns the standard deviation of a numeric column in the group. 求指定列数值的标准偏差 |
|
DOUBLE |
stddev_samp(col) |
Returns the unbiased sample standard deviation of a numeric column in the group. 求指定列数值的样本标准偏差 |
|
DOUBLE |
covar_pop(col1, col2) |
Returns the population covariance of a pair of numeric columns in the group. 求指定列数值的协方差 |
|
DOUBLE |
covar_samp(col1, col2) |
Returns the sample covariance of a pair of a numeric columns in the group. 求指定列数值的样本协方差 |
|
DOUBLE |
corr(col1, col2) |
Returns the Pearson coefficient of correlation of a pair of a numeric columns in the group. 返回两列数值的相关系数 |
|
DOUBLE |
percentile(BIGINT col, p) |
Returns the exact pth percentile of a column in the group (does not work with floating point types). p must be between 0 and 1. NOTE: A true percentile can only be computed for integer values. Use PERCENTILE_APPROX if your input is non-integral. 返回col的p%分位数 |
8 表生成函数
|
Return Type |
Name(Signature) |
Description |
|---|---|---|
|
Array Type |
explode(array<TYPE> a) |
For each element in a, generates a row containing that element. 对于a中的每个元素,将生成一行且包含该元素 |
|
N rows |
explode(ARRAY) |
Returns one row for each element from the array.. 每行对应数组中的一个元素 |
|
N rows |
explode(MAP) |
Returns one row for each key-value pair from the input map with two columns in each row: one for the key and another for the value. (As of Hive 0.8.0.). 每行对应每个map键-值,其中一个字段是map的键,另一个字段是map的值 |
|
N rows |
posexplode(ARRAY) |
Behaves like 与explode类似,不同的是还返回各元素在数组中的位置 |
|
N rows |
stack(INT n, v_1, v_2, ..., v_k) |
Breaks up v_1, ..., v_k into n rows. Each row will have k/n columns. n must be constant.. 把M列转换成N行,每行有M/N个字段,其中n必须是个常数 |
|
tuple |
json_tuple(jsonStr, k1, k2, ...) |
Takes a set of names (keys) and a JSON string, and returns a tuple of values. This is a more efficient version of the 从一个JSON字符串中获取多个键并作为一个元组返回,与get_json_object不同的是此函数能一次获取多个键值 |
|
tuple |
parse_url_tuple(url, p1, p2, ...) |
This is similar to the 返回从URL中抽取指定N部分的内容,参数url是URL字符串,而参数p1,p2,....是要抽取的部分,这个参数包含HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO, QUERY:<KEY> |
|
inline(ARRAY<STRUCT[,STRUCT]>) |
Explodes an array of structs into a table. (As of Hive 0.10.). 将结构体数组提取出来并插入到表中 |
二、复杂数据类型
1、array
现有数据如下:
1 huangbo guangzhou,xianggang,shenzhen a1:30,a2:20,a3:100 beijing,112233,13522334455,500
2 xuzheng xianggang b2:50,b3:40 tianjin,223344,13644556677,600
3 wangbaoqiang beijing,zhejinag c1:200 chongqinjg,334455,15622334455,20
建表语句
use class; create table cdt( id int, name string, work_location array<string>, piaofang map<string,bigint>, address struct<location:string,zipcode:int,phone:string,value:int>) row format delimited fields terminated by " " collection items terminated by "," map keys terminated by ":" lines terminated by " ";
导入数据
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/cdt.txt" into table cdt;
查询语句
select * from cdt;
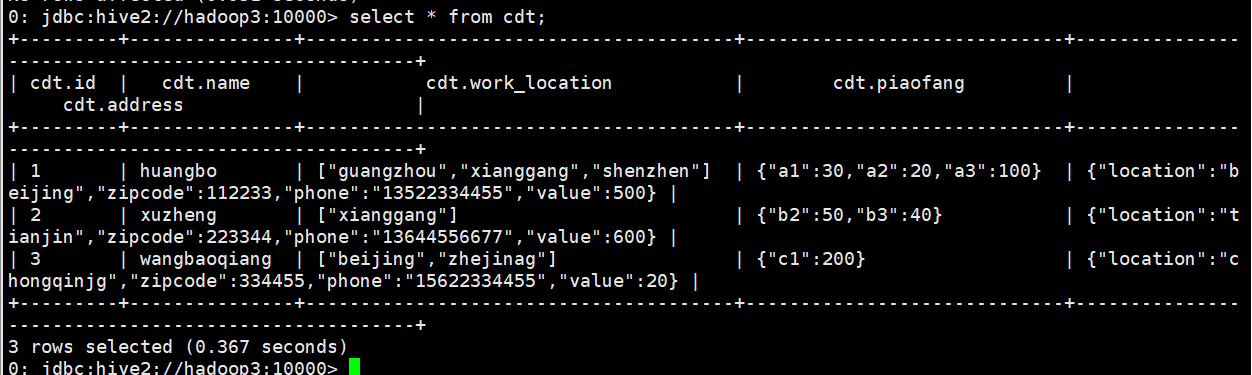
select name from cdt;
select work_location from cdt;
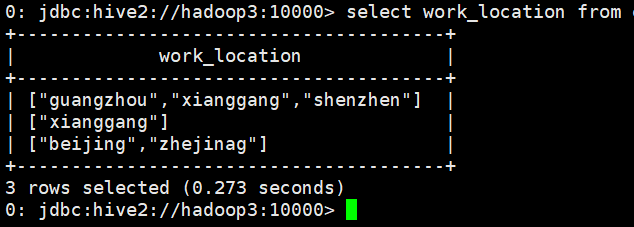
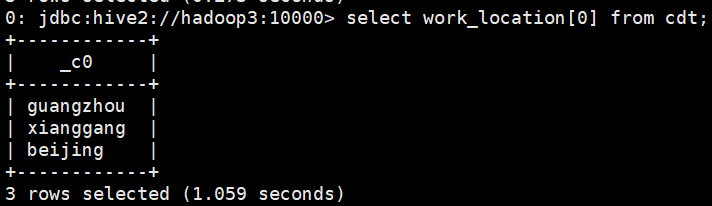
select work_location[0] from cdt;
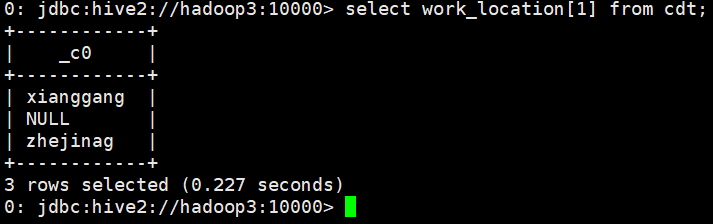
select work_location[1] from cdt;
2、map
建表语句、导入数据同1
查询语句
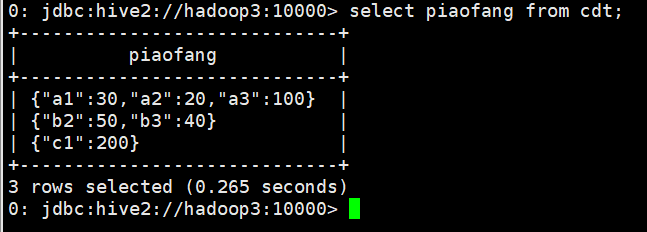
select piaofang from cdt;
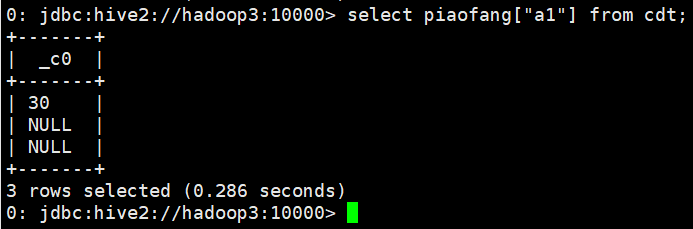
select piaofang["a1"] from cdt;
3、struct
建表语句、导入数据同1
查询语句
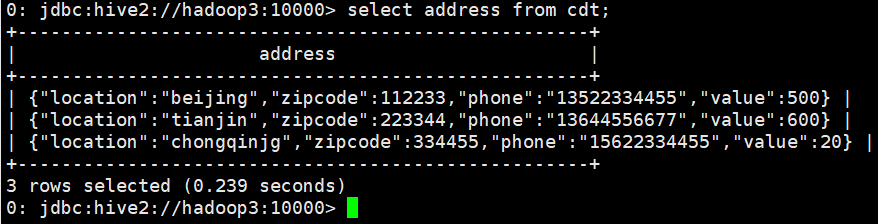
select address from cdt;
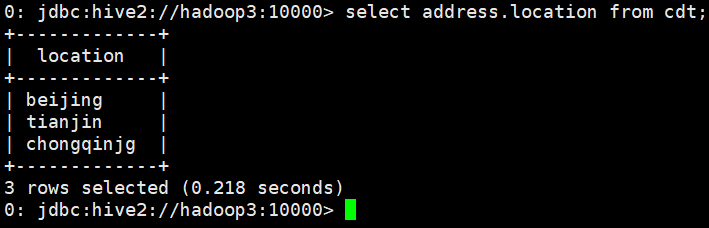
select address.location from cdt;
4、uniontype
很少使用
三、视图
1、Hive 的视图和关系型数据库的视图区别
和关系型数据库一样,Hive 也提供了视图的功能,不过请注意,Hive 的视图和关系型数据库的数据还是有很大的区别:
(1)只有逻辑视图,没有物化视图;
(2)视图只能查询,不能 Load/Insert/Update/Delete 数据;
(3)视图在创建时候,只是保存了一份元数据,当查询视图的时候,才开始执行视图对应的 那些子查询
2、Hive视图的创建语句
create view view_cdt as select * from cdt;

3、Hive视图的查看语句
show views; desc view_cdt;-- 查看某个具体视图的信息

4、Hive视图的使用语句
select * from view_cdt;

5、Hive视图的删除语句
drop view view_cdt;

四、函数
1、内置函数
(1)查看内置函数
show functions;

(2)显示函数的详细信息
desc function substr;

(3)显示函数的扩展信息
desc function extended substr;

2、自定义函数UDF
当 Hive 提供的内置函数无法满足业务处理需要时,此时就可以考虑使用用户自定义函数。
UDF(user-defined function)作用于单个数据行,产生一个数据行作为输出。(数学函数,字 符串函数)
UDAF(用户定义聚集函数 User- Defined Aggregation Funcation):接收多个输入数据行,并产 生一个输出数据行。(count,max)
UDTF(表格生成函数 User-Defined Table Functions):接收一行输入,输出多行(explode)
(1) 简单UDF示例
A. 导入hive需要的jar包,自定义一个java类继承UDF,重载 evaluate 方法
ToLowerCase.java
import org.apache.hadoop.hive.ql.exec.UDF;
public class ToLowerCase extends UDF{
// 必须是 public,并且 evaluate 方法可以重载
public String evaluate(String field) {
String result = field.toLowerCase();
return result;
}
}
B. 打成 jar 包上传到服务器
C. 将 jar 包添加到 hive 的 classpath
add JAR /home/hadoop/udf.jar;

D. 创建临时函数与开发好的 class 关联起来
0: jdbc:hive2://hadoop3:10000> create temporary function tolowercase as 'com.study.hive.udf.ToLowerCase';
![]()
E. 至此,便可以在 hql 在使用自定义的函数
0: jdbc:hive2://hadoop3:10000> select tolowercase('HELLO');

(2) JSON数据解析UDF开发
现有原始 json 数据(rating.json)如下
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}
{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}
{"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"}
{"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"}
{"movie":"1287","rate":"5","timeStamp":"978302039","uid":"1"}
{"movie":"2804","rate":"5","timeStamp":"978300719","uid":"1"}
{"movie":"594","rate":"4","timeStamp":"978302268","uid":"1"}
现在需要将数据导入到 hive 仓库中,并且最终要得到这么一个结果:

该怎么做、???(提示:可用内置 get_json_object 或者自定义函数完成)
A. get_json_object(string json_string, string path)
返回值: string
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。 这个函数每次只能返回一个数据项。
0: jdbc:hive2://hadoop3:10000> select get_json_object('{"movie":"594","rate":"4","timeStamp":"978302268","uid":"1"}','$.movie');

创建json表并将数据导入进去
0: jdbc:hive2://hadoop3:10000> create table json(data string); No rows affected (0.983 seconds) 0: jdbc:hive2://hadoop3:10000> load data local inpath '/home/hadoop/json.txt' into table json; No rows affected (1.046 seconds) 0: jdbc:hive2://hadoop3:10000>

0: jdbc:hive2://hadoop3:10000> select . . . . . . . . . . . . . . .> get_json_object(data,'$.movie') as movie . . . . . . . . . . . . . . .> from json;

B. json_tuple(jsonStr, k1, k2, ...)
参数为一组键k1,k2……和JSON字符串,返回值的元组。该方法比 get_json_object 高效,因为可以在一次调用中输入多个键
0: jdbc:hive2://hadoop3:10000> select . . . . . . . . . . . . . . .> b.b_movie, . . . . . . . . . . . . . . .> b.b_rate, . . . . . . . . . . . . . . .> b.b_timeStamp, . . . . . . . . . . . . . . .> b.b_uid . . . . . . . . . . . . . . .> from json a . . . . . . . . . . . . . . .> lateral view json_tuple(a.data,'movie','rate','timeStamp','uid') b as b_movie,b_rate,b_timeStamp,b_uid;

(3) Transform实现
Hive 的 TRANSFORM 关键字提供了在 SQL 中调用自写脚本的功能。适合实现 Hive 中没有的 功能又不想写 UDF 的情况
具体以一个实例讲解。
Json 数据: {"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
需求:把 timestamp 的值转换成日期编号
1、先加载 rating.json 文件到 hive 的一个原始表 rate_json
create table rate_json(line string) row format delimited; load data local inpath '/home/hadoop/rating.json' into table rate_json;
2、创建 rate 这张表用来存储解析 json 出来的字段:
create table rate(movie int, rate int, unixtime int, userid int) row format delimited fields terminated by ' ';
解析 json,得到结果之后存入 rate 表:
insert into table rate select get_json_object(line,'$.movie') as moive, get_json_object(line,'$.rate') as rate, get_json_object(line,'$.timeStamp') as unixtime, get_json_object(line,'$.uid') as userid from rate_json;
3、使用 transform+python 的方式去转换 unixtime 为 weekday
先编辑一个 python 脚本文件
########python######代码
## vi weekday_mapper.py
#!/bin/python
import sys
import datetime
for line in sys.stdin:
line = line.strip()
movie,rate,unixtime,userid = line.split(' ')
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print ' '.join([movie, rate, str(weekday),userid])
保存文件 然后,将文件加入 hive 的 classpath:
hive>add file /home/hadoop/weekday_mapper.py; hive> insert into table lastjsontable select transform(movie,rate,unixtime,userid) using 'python weekday_mapper.py' as(movie,rate,weekday,userid) from rate;
创建最后的用来存储调用 python 脚本解析出来的数据的表:lastjsontable
create table lastjsontable(movie int, rate int, weekday int, userid int) row format delimited fields terminated by ' ';
最后查询看数据是否正确
select distinct(weekday) from lastjsontable;
五、特殊分隔符处理
补充:hive 读取数据的机制:
1、 首先用 InputFormat<默认是:org.apache.hadoop.mapred.TextInputFormat >的一个具体实 现类读入文件数据,返回一条一条的记录(可以是行,或者是你逻辑中的“行”)
2、 然后利用 SerDe<默认:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe>的一个具体 实现类,对上面返回的一条一条的记录进行字段切割
Hive 对文件中字段的分隔符默认情况下只支持单字节分隔符,如果数据文件中的分隔符是多 字符的,如下所示:
01||huangbo
02||xuzheng
03||wangbaoqiang
1、使用RegexSerDe正则表达式解析
创建表
create table t_bi_reg(id string,name string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)\|\|(.*)','output.format.string'='%1$s %2$s')
stored as textfile;

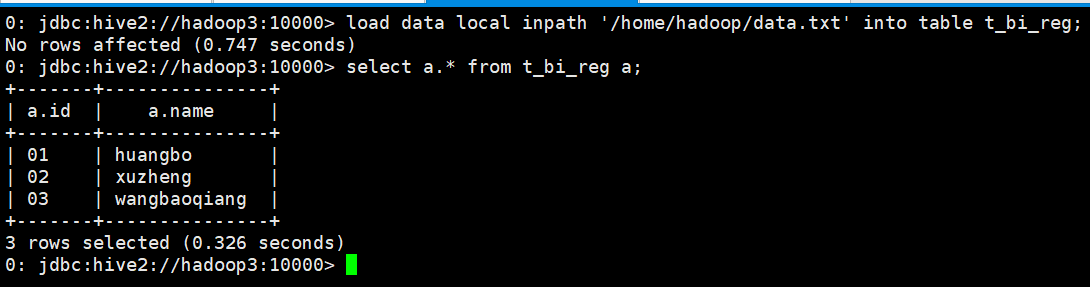
导入数据并查询
0: jdbc:hive2://hadoop3:10000> load data local inpath '/home/hadoop/data.txt' into table t_bi_reg; No rows affected (0.747 seconds) 0: jdbc:hive2://hadoop3:10000> select a.* from t_bi_reg a;