HBase是分布式、面向列式存储的开源数据库,来源于Google的论文BigTable,HBase运行于Hadoop平台之上,不同于一般的关系数据库,是一个适合非结构化数据存储的分布式数据库
安装Hbase之前首先系统应该做通用的集群环境准备工作,这些是必须的:
1、集群中主机名必须正确配置,最好有实际意义;并且主机名都在hosts文件中对应主机IP,一一对应,不可缺少
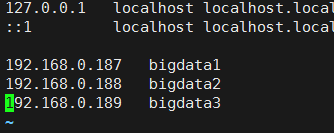
这里是3台主机,分别对应
2、JDK环境正确安装
3、集群中每台机器关闭防火墙,保证通信畅通
4、配置集群间ssh免密登录
5、集群ntp服务开启,保证时间同步
6、Hadoop HDFS服务开启
前面5步都配置好的基础上,首先配置Hadoop集群,在bigdata1上做配置操作
首先解压hadoop,并安装至指定目录:
tar -xvzf hadoop-2.6.0.tar.gz mkdir /bigdata/hadoop mv hadoop-2.6.0 /bigdata/hadoop cd /bigdata/hadoop/hadoop-2.6.0
就是简单的释放,然后为了方便可以将HADOOP_HOME添加至环境变量
配置hadoop需要编辑以下几个配置文件:
hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves
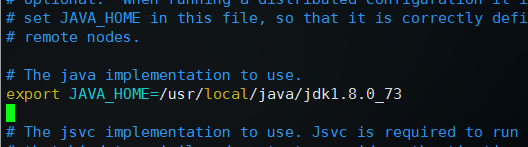
1、编辑hadoop-env.sh
修改export JAVA_HOME=${JAVA_HOME}为自己的实际安装位置
这里是export JAVA_HOME=/usr/local/java/jdk1.8.0_73
2、编辑core-site.xml,在configuration标签中间添加如下代码:
<property> <name>fs.defaultFS</name> <value>hdfs://bigdata1:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/bigdata/hadoop/tmp</value> </property>
其中bigdata1是namenode节点
3、编辑hdfs-site.xml ,添加如下代码:
<property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///bigdata/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///bigdata/hadoop/hdfs/data</value> </property> <!-- 这个地方是为Hbase的专用配置,最小为4096,表示同时处理文件的上限,不配置会报错 --> <property> <name>dfs.datanode.max.xcievers</name> <value>4096</value> </property>
关于第4组配置已经注释说明了
4、编辑mapred-site.xml,添加如下配置:
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
5、编辑yarn-site.xml,添加如下配置:
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
6、编辑slaves,添加datanode节点
bigdata2
bigdata3
这些都保存完毕,将/bigdata/下的hadoop目录整体发送至集群中其他主机,其他主机应该事先建立好bigdata目录
scp -r /bigdata/hadoop bigdata2:/bigdata scp -r /bigdata/hadoop bigdata3:/bigdata
然后在bigdata1上格式化文件系统:
bin/hdfs namenode -format
然后启动hdfs服务:
sbin/start-dfs.sh
启动完成之后,执行 jps 命令,在主节点可以看到NameNode和SecondaryNameNode进程;其他节点可以看到DataNode进程
然后启动yarn守护进程: sbin/start-yarn.sh
主节点会增加:ResourceManager进程,其他节点会增加:NodeManager进程
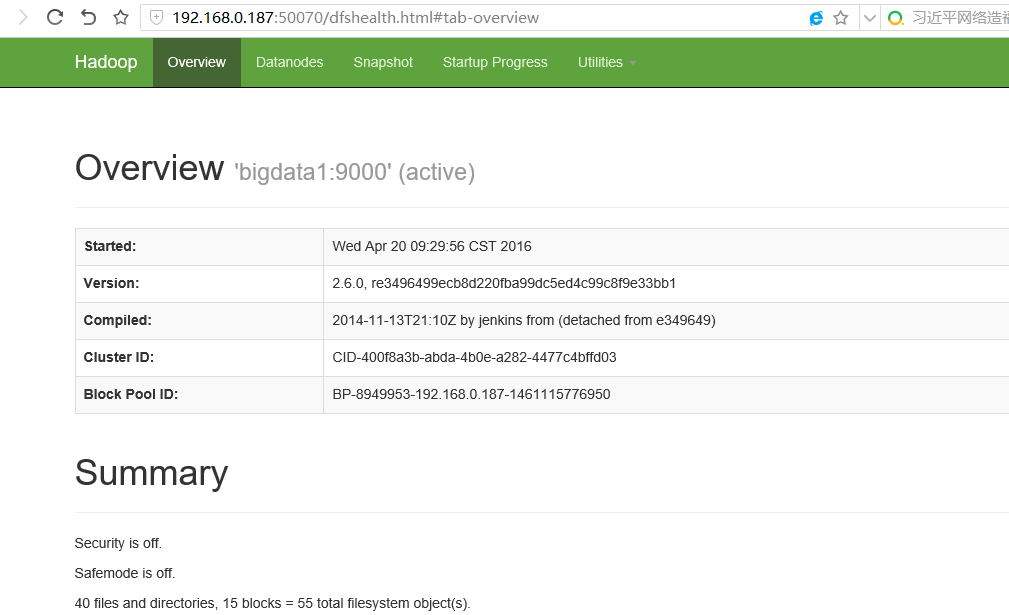
现在通过浏览器可以打开相应的管理界面,以bigdata1的IP访问:
http://192.168.0.187:50070
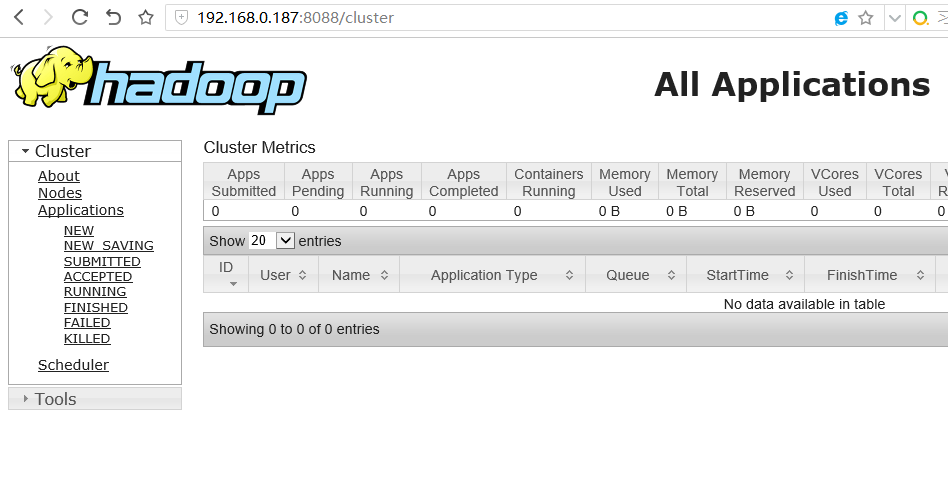
http://192.168.0.187:8088
到这里hadoop hdfs就部署完成了,然后开始部署HBase,这里使用的版本为:hbase-0.98.18-hadoop2-bin.tar.gz
和释放hadoop包一样将hbase释放到对应的目录并进入,这里是:/bigdata/hbase/hbase-0.98.18-hadoop2
首先编辑配置文件: vim conf/hbase-env.sh
去掉JAVA_HOME前面的注释,改为自己实际的JDK安装路径,和配置hadoop类似

然后,去掉export HBASE_MANAGES_ZK=true前面的注释并改为export HBASE_MANAGES_ZK=false,配置不让HBase管理Zookeeper
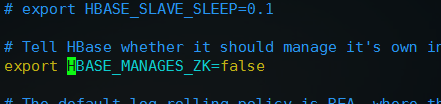
配置完这两项之后,保存退出
编辑文件 vim conf/hbase-site.xml 在configuration标签之间加入如下配置:
<!-- 指定HBase在HDFS上面创建的目录名hbase --> <property> <name>hbase.rootdir</name> <value>hdfs://bigdata1:9000/hbase</value> </property> <!-- 开启集群运行方式 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property>
分别将hadoop配置下的core-site.xml和hdfs-site.xml复制或者做软链接到hbase配置目录下:
cp /bigdata/hadoop/hadoop-2.6.0/etc/hadoop/core-site.xml conf/ cp /bigdata/hadoop/hadoop-2.6.0/etc/hadoop/hdfs-site.xml conf/
执行 vim conf/regionservers 编辑运行regionserver存储服务的Hbase节点,就相当于hadoop slaves中的DataNode节点
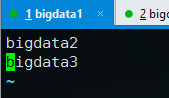
保存之后,配置完毕,将hbase发送至其他数据节点:
scp -r /bigdata/hbase/ bigdata2:/bigdata/ scp -r /bigdata/hbase/ bigdata3:/bigdata/
然后在bigdata1启动Hbase
bin/start-hbase.sh
启动成功,在bigdata1会增加进程:HMaster 在bigdata2和bigdata3会增加进程:HRegionServer
到这里HBase就部署完毕,这里没有包含Zookeeper
执行命令: /bigdata/hadoop/hadoop-2.6.0/bin/hdfs dfs -ls / 可以查看hbase是否在HDFS文件系统创建成功

看到/hbase节点表示创建成功
然后执行: bin/hbase shell 可以进入Hbase管理界面
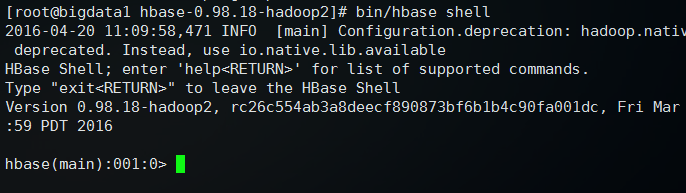
输入 status 查看状态

返回状态,表示HBase可以正常使用
输入 quit 可以退出管理,回到命令行