背景
tree diff
在页面的每一层节点,都需要进行对比,整颗DOM树从上倒下,对比一遍以后,所有需要被替换,需要更新的元素 必然会被找出来!
component diff
在对比DOM树的每一层的时候,对每个组件,进行比较:
1、如果对比前后,组件的类型相同,则暂时认为组件不需要去被更新
2、如果对比前后,组件的类型不同,则移除旧组件,创建新组件,并把组件替换到原来的位置;
element diff
组件中,主机元素级别的对比
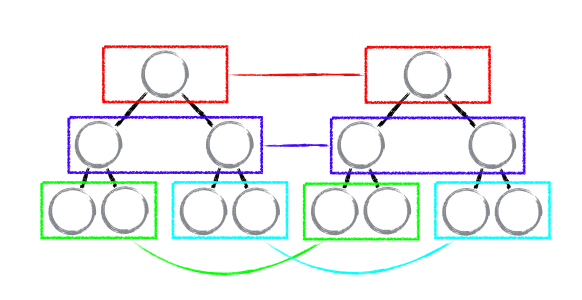
传统Diff和React Diff对比
传统 diff 算法的复杂度为 O(n^3),显然这是无法满足性能要求的。React 通过制定大胆的策略,将 O(n^3) 复杂度的问题转换成 O(n) 复杂度的问题。
原理概述
1、找到相同的前置元素和后置元素
A: -> [a b c d] B: -> [a b d]
A 和 B 的不同就是多了一个 c 元素,把 c 元素移除这一步可以完成 diff,相反地,如果这步操作 A 为空,B 有多余元素,那么我们就将多余元素插入即可。
更为复杂的一种情况:
A: -> [b c d e f] 旧数组 B: -> [c b h f e] 新数组
这个时候我们需要去创建一个位置数组P去记录新数组应该被插入的位置
P: [. . . . .] // . 代表 -1
当数组足够小时,直接去遍历数组,如果数组太大,需要去建个索引
I: {
c: 0,
b: 1,
h: 2,
f: 3,
e: 4,
}
在这过程中,也需要去维护一个变量 last,它代表访问过的节点在新集合中最右的位置(即最大的位置)。如果新集合中当前访问的节点比 last 大,说明当前访问节点在旧集合中就比上一个节点位置靠后,则该节点不会影响其他节点的位置,因此不必执行移动操作。只有当访问的节点比 last 小时,才需要进行移动操作
>>
>> A: [b c d e f]
>> ^
>> B: [c b h f e]
>> P: [1 0 . . .] // . == -1
>> I: {
>> c: 0, <-
>> b: 1,
>> h: 2,
>> f: 3,
>> e: 4,
>> }
>> last = 1 // last > 0; moved = true
>> 当c在新数组的位置比last小,这个时候我们需要进行移动操作
stack reconciler的核心方案:
当type是class or func
在思考react首次装载的过程中,ReactDOM.render(<App />, root),ReactDOM会将<App />传递给协调器,<App />可以是一个react元素,其实也是一个普通的原型对象(type: App, props: {} ),协调器(reconciler)会检查 App是类还是函数。如果 App 是函数,协调器会调用App(props)来获取所渲染的元素。如果App是类,协调器则会使用new App(props)创建一个App实例,调用 componentWillMount() 生命周期方法,进而调用 render() 方法来获取所渲染的元素。无论如何,协调器都会学习App元素的渲染方式.
在这个渲染的过程中,不断通过递归的方式向下钻取去查找,<App /> 可能被渲染成<List />,进而 渲染成<Item /> ... <Button />等.
// 判断react元素是否是一个class
function isClass(type) {
return (
Boolean(type.prototype) && Boolean(type.prototype.isReactComponent)
);
}
// 定义一个func mounting 不断地去递归装载
function mount(element) {
let type = element.type;
let props = element.props;
let renderEle;
if(isClass(type)) {
let instance =new type(props);
instance.props = props;
// 调用react 的lift 周期,如果存在这个周期中
if(instance.componentWillMount) {
instance.componentWillMount();
}
//进而调用render函数去渲染
renderEle = instance.render();
}else{
// 当然这是一个组件函数
renderEle=type(props);
}
return mount(renderEle); //注这里不断通过递归去返回相应的ele,当然这里只是通过伪代码,没有处理到div和p这一层级的元素,同时这里会不断循环
}
“装载”(Mounting)是一个递归过程
当type是string 时
说明该元素是一个主机元素
function mountHost(element) {
var type = element.type;
var props = element.props;
var children = props.children || [];
if (!Array.isArray(children)) {
children = [children];
}
children = children.filter(Boolean);
// 该代码块不可出现在协调器(reconciler)中。
// 不同渲染器(renderers)可能会以不同方式初始化节点。
// 例如,React Native会生成iOS或Android视图。
var node = document.createElement(type);
Object.keys(props).forEach(propName => {
if (propName !== 'children') {
node.setAttribute(propName, props[propName]);
}
});
// 装载子节点
children.forEach(childElement => {
// 子节点有可能是主机元素(如<div />)或复合元素(如<Button />).
// 所以我们应该递归的装载
var childNode = mount(childElement);
// 此行代码仍是特定于渲染器的。不同的渲染器则会使用不同的方法
node.appendChild(childNode);
});
// 返回DOM节点作为装载结果
// 此处即为递归结束.
return node;
}
function mount(element) {
var type = element.type;
if (typeof type === 'function') {
// 用户定义的组件
return mountComposite(element);
} else if (typeof type === 'string') {
// 平台相关的组件,比如说浏览器中的div,ios和安卓中的视图
return mountHost(element);
}
}
var rootEl = document.getElementById('root');
var node = mount(<App />);
rootEl.appendChild(node);
class CompositeComponent {
卸载组件
unmount() {
// Call the lifecycle hook if necessary
var publicInstance = this.publicInstance;
if (publicInstance) {
if (publicInstance.componentWillUnmount) {
publicInstance.componentWillUnmount();
}
}
// Unmount the single rendered component
var renderedComponent = this.renderedComponent;
renderedComponent.unmount();
}
}
在这过程中会涉及到一些事件侦听器,同时会清除旧树上的钩子,例如componentWillUnmount
更新组件
在更新组件的时候,会去判断element type是否一样,如果一样则适当更新,否则销毁后重建,也就是卸载现有的内部实例并挂载对应于渲染的元素类型的新实例
if (prevRenderedElement.type === nextRenderedElement.type) {
prevRenderedComponent.receive(nextRenderedElement);
return;
}
当旧的组件和新的组件的type不一致时,对旧的组件销毁然后插入
//模拟
//模拟
var prevNode = prevRenderedComponent.getHostNode();
// 之前的旧组件进行销毁
prevRenderedComponent.unmount();
//创建新的组件
var nextRenderedComponent = instantiateComponent(nextRenderedElement);
var nextNode = nextRenderedComponent.mount();
// Replace the reference to the child
this.renderedComponent = nextRenderedComponent;
// 组件替换
prevNode.parentNode.replaceChild(nextNode, prevNode);
}
}
组件对于内部实例的数组相关操作
// // 这些是React元素(element)数组:
var prevChildren = prevProps.children || [];
if (!Array.isArray(prevChildren)) {
prevChildren = [prevChildren];
}
var nextChildren = nextProps.children || [];
if (!Array.isArray(nextChildren)) {
nextChildren = [nextChildren];
}
// 这些是内部实例(internal instances)数组:
var prevRenderedChildren = this.renderedChildren;
var nextRenderedChildren = [];
// 当我们遍历children时,我们将向数组中添加操作。
var operationQueue = [];
// 注意:以下章节大大减化!
// 它不处理reorders,空children,或者keys。
// 它只是用来解释整个流程,而不是具体的细节。
for (var i = 0; i < nextChildren.length; i++) {
// 尝试为这个子级获取现存内部实例。
var prevChild = prevRenderedChildren[i];
// 如果在这个索引下没有内部实例,那说明是一个child被添加了末尾。
// 这时应该去创建一个内部实例,挂载它,并使用它的节点。
if (!prevChild) {
var nextChild = instantiateComponent(nextChildren[i]);
var node = nextChild.mount();
// 记录一下我们将来需要append一个节点(node)
operationQueue.push({type: 'ADD', node});
nextRenderedChildren.push(nextChild);
continue;
}
// 如果它的元素类型匹配,我们只需要更新该实例即可
// 例如, <Button size="small" /> 可以更新为
// <Button size="large" /> 但是不能被更新为 <App />.
var canUpdate = prevChildren[i].type === nextChildren[i].type;
// 如果我们不能更新现有的实例,我们就必须卸载它。然后装一个新的替代它。
if (!canUpdate) {
var prevNode = prevChild.getHostNode();
prevChild.unmount();
var nextChild = instantiateComponent(nextChildren[i]);
var nextNode = nextChild.mount();
// 记录一下我们将来需要替换这些nodes
operationQueue.push({type: 'REPLACE', prevNode, nextNode});
nextRenderedChildren.push(nextChild);
continue;
}
// 如果我们可以更新现存的内部实例(internal instance),
// 我们仅仅把下一个元素传入其receive即可,让其receive函数处理它的更新即可
prevChild.receive(nextChildren[i]);
nextRenderedChildren.push(prevChild);
}
// 最后,卸载(unmount)哪些不存在的children
for (var j = nextChildren.length; j < prevChildren.length; j++) {
var prevChild = prevRenderedChildren[j];
var node = prevChild.getHostNode();
prevChild.unmount();
// 记录一下我们将来需要remove这些node
operationQueue.push({type: 'REMOVE', node});
}
// Point the list of rendered children to the updated version.
this.renderedChildren = nextRenderedChildren;
// ...
当组件不是通过挂载,而是通过接收一个元素,并且这发生在元素的key变化时,当然这是一种新的情况
Key分析
针对于下面代码块
//old tree <ul> <li>first</li> <li>second</li> </ul> //new tree <ul> <li>first</li> <li>second</li> <li>third</li> </ul> React在迭代遍历<li>first</li>树和<li>second</li>树时,因为前面两项是相同的,在插入<li>third</li>树时,React表现出来的性能不会太差,如果是下面这种情况下: //old tree <ul> <li>Duke</li> <li>Villanova</li> </ul> //new tree <ul> <li>Connecticut</li> <li>Duke</li> <li>Villanova</li> </ul> React就会去不断去替换更新组件 <ul> <li key="1">Duke</li> <li key="2">Villanova</li> </ul> //new tree <ul> <li key="1">Connecticut</li> <li key="2">Duke</li> <li key="3">Villanova</li> </ul>
React在迭代遍历<li>first</li>树和<li>second</li>树时,因为前面两项是相同的,在插入<li>third</li>树时,React表现出来的性能不会太差,如果是下面这种情况下:
//old tree <ul> <li>Duke</li> <li>Villanova</li> </ul> //new tree <ul> <li>Connecticut</li> <li>Duke</li> <li>Villanova</li> </ul>
React就会去不断去替换更新组件
<ul> <li key="1">Duke</li> <li key="2">Villanova</li> </ul> //new tree <ul> <li key="1">Connecticut</li> <li key="2">Duke</li> <li key="3">Villanova</li> </ul>
通过key值React比较<li key="2">Duke</li>与<li key="1">Connecticut</li>时,会发现key值是不同,表示<li key="1">Connecticut</li>是新插入的项,因此会在开始出插入<li key="1">Connecticut</li>,随后分别比较<li key="2">Duke</li>与<li key="3">Villanova</li>,发现li项没有发生改变,仅仅只是被移动而已。这种情况下,性能的提升是非常可观的。因此,从上面看key值必须要稳定、可预测的并且是唯一的
如果是相同的key值,会出现:
[1, 1, 2, 2].map((val, index) => {
return (
<Demo
key={val}
value={val + '-' + index}
/>
)
})
}
渲染后
<ul>
{
[
<li key={1}>1</li>,
<li key={2}>2</li>
]
}
</ul>
因为React会认为key值相同的元素是同一个元素
思考:
子元素的传入以数组的形式传入第三个参数,但是在第二个场景中,子元素是以参数的形式依次传入的。在第二种场景中,每个元素出现在固定的参数位置上,React就是通过这个位置作为天然的key值去判别的,所以你就不用传入key值的,但是第一种场景下,以数组的类型将全部子元素传入,React就不能通过参数位置的方法去判别,所以就必须你手动地方式去传入key值
当然这启发式算法,使之时间复杂度由O(n3次方)降低为O(n)
下面是JSX模版编译成JS对象后的结果
//第一种情况
function App() {
return React.createElement('ul',null,[
React.createElement('li',{key: 1}, "1"),
React.createElement('li',{key: 2}, "2")
])
}
//第二种情况
function App() {
return React.createElement('ul',
null,
React.createElement('li',{key: 1}, "1"),
React.createElement('li',{key: 2}, "2")
)
}
在Inferno采用的Diff算法中,用到了经典的计算最长上升子序列(Longest Increasing Subsequence)的算法,下面将通过算法的描述更加地去理解Diff算法.为什么需要去使用呢?DOM中还有移动的操作,我们必须最大化复用当前已经存在的节点,并使尽量多的节点不被移动.
最长上升子序列就是求解一个序列中长度最长且升序的子序列.
暴力求解
时间复杂度o(2^n)*n
动态规划求解
例如:
3,5,7,1,2,8
那么其最长上升子序列就是:
3, 5, 7, 8
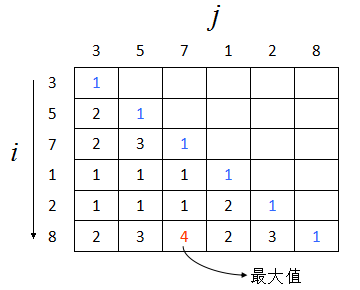
- 初始化对角线为 1;
- 对每一个 i,遍历 j(0 到 i-1):
- 若A[i] <= A[j],置 1。
- 若A[i] > A[j],取第 j 行的最大值加 1
// LIS 的动态规划方式实现
#include <iostream>
using namespace std;
function getLISLength(a, len) {
//定义一维数组并初始化为1
let lis = new int[len];
for (let i = 0; i < len; ++i)
lis[i] = 1;
// 计算每个i对应的lis最大值,即打表的过程
for (let i = 1; i < len; ++i)
for (let j = 0; j < i; ++j) // 0到i-1
if ( a[i] > a[j] && lis[i] < lis[j] + 1)
lis[i] = lis[j] + 1; // 更新
// 数组中最大的那个,就是最长递增子序列的长度
maxlis = 0;
for (let i = 0; i < len; ++i)
if ( maxlis < lis[i] )
maxlis = lis[i];
delete lis;
return maxlis;
}
时间复杂度0(n方)
上面表述是关于stack协调器,但在react 16后已经使用了fiber协调器代替stack协调器
Fiber协调器
Fiber是其最新实现。归功于它的底层架构,它提供能力去实现许多有趣的特性,比如执行非阻塞渲染,根据优先级执行更新,在后台预渲染内容.这也是时间分片.
我们可以去假设一种情况:如果React要同步遍历整个组件树并为每个组件执行任务,它可能会运行超过16毫秒,以便应用程序代码执行其逻辑。这将导致帧丢失,导致不顺畅的视觉效果.
因为有时候我们不希望JS不受控制地长时间执行(想要手动调度),那么,为什么JS长时间执行会影响交互响应、动画?
这个时我们就会去想,是否可以闲时才去渲染,在保证既能执行其逻辑,又能有很好的交互体验.
为了解决这个问题,React必须重新实现遍历树的算法,从依赖于内置堆栈的同步递归模型,变为具有链表和指针的异步模型
堆栈在自然科学中,调用堆栈是一种堆栈数据结构,每一个活动子程序在其执行完成时应该返回其自己特定的位置,使其有迹可循.
循环遍历树会打印b2, c1, d1, d2, b3, c2
这种方式非常不适合中断,它有局限性。最大的一点就是我们无法分解工作为增量单元。我们不能暂停特定组件的工作并在稍后恢复.
Fiber 是一种单链表树遍历算法
自定义child(子节点)、sibling(兄弟节点)、return
class Node {
constructor(instance) {
this.instance = instance;
this.child = null;
this.sibling = null;
this.return = null;
}
}
function link(parent, elements) {
if (elements === null) elements = [];
parent.child = elements.reduceRight((previous, current) => {
const node = new Node(current);
node.return = parent;
node.sibling = previous;
return node;
}, null);
return parent.child;
}
//打印节点名字
function doWork(node) {
console.log(node.instance.name);
const children = node.instance.render();
return link(node, children);
}
//深度优先遍历
function walk(o) {
let root = o;
let current = o;
while (true) {
// 为节点执行工作,获取并连接它的children
let child = doWork(current);
// 如果child不为空, 将它设置为当前活跃节点
if (child) {
current = child;
continue;
}
// 如果我们回到了根节点,退出函数
if (current === root) {
return;
}
// 遍历直到我们发现兄弟节点
while (!current.sibling) {
// 如果我们回到了根节点,退出函数
if (!current.return || current.return === root) {
return;
}
// 设置父节点为当前活跃节点
current = current.return;
}
// 如果发现兄弟节点,设置兄弟节点为当前活跃节点
current = current.sibling;
}
}
因此,在instance相关扩展上新增了这些实例:
DOM
真实DOM节点
-------
effect
每个workInProgress tree节点上都有一个effect list
用来存放diff结果
当前节点更新完毕会向上merge effect list(queue收集diff结果)
- - - -
workInProgress
workInProgress tree是reconcile过程中从fiber tree建立的当前进度快照,用于断点恢复
- - - -
fiber
fiber tree与vDOM tree类似,用来描述增量更新所需的上下文信息
-------
Elements
如果以组件为例:
- 1如果当前节点不需要更新,直接把子节点clone过来,跳到5;要更新的话打个tag
- 更新当前节点状态(props, state, context等)
- 调用shouldComponentUpdate(),false的话,跳到5
- 调用render()获得新的子节点,并为子节点创建fiber(创建过程会尽量复用现有fiber,子节点增删也发生在这里)
- 如果没有产生child fiber,该工作单元结束,把effect list归并到return,并把当前节点的sibling作为下一个工作单元;否 则把child作为下一个工作单元
- 如果没有剩余可用时间了,等到下一次主线程空闲时才开始下一个工作单元;否则,立即开始做
- 如果没有下一个工作单元了(回到了workInProgress tree的根节点),第1阶段结束,进入pendingCommit状态
其中current的赋值重新得到需要操作的节点,使其能够终止,值之前便可以'暂停'来执行其它逻辑.构建workInProgress tree的过程就是diff的过程,通过requestIdleCallback来调度执行一组任务,每完成一个任务后回来看看有没有插队的(更紧急的),每完成一组任务,把时间控制权交还给主线程,直到下一次requestIdleCallback回调再继续构建workInProgress tree
增量渲染其实是解决帧(在栈协调器在遍历每一个树节点都会产生相应的栈)问题,,渲染任务拆分之后,每次只做一小段,做完一段就把时间控制权交还给主线程,而不像之前长时间占用。这种策略也是一种cooperative scheduling(合作式调度)
在组件的生命周期, 主要分为两个阶段,第一个阶段由requestIdleCallback不断反复,默认设置为最低优先级
// 第1阶段 render/reconciliation componentWillMount componentWillReceiveProps shouldComponentUpdate componentWillUpdate // 第2阶段 commit componentDidMount componentDidUpdate componentWillUnmount
fiber tree与workInProgress tree
fiber tree 和workinprogress tree 共存其实就是一种双缓存的一种策略以,fiber tree为主,workInProgress tree为辅,workInProgress tree构造完后就是会得到新的fiber tree,fiber tree 的指针指向workInProgress tree,复用内部对象(fiber),减少GC的时间开销
优先级策略
每个工作单元运行时有6种优先级:
- synchronous 与之前的Stack reconciler操作一样,同步执行
- task 在next tick之前执行
- animation 下一帧之前执行
- high 在不久的将来立即执行
- low 稍微延迟(100-200ms)执行也没关系
- offscreen 下一次render时或scroll时才执行
synchronous首屏(首次渲染)用,要求尽量快,不管会不会阻塞UI线程。animation通过requestAnimationFrame来调度,这样在下一帧就能立即开始动画过程;后3个都是由requestIdleCallback回调执行的;offscreen指的是当前隐藏的、屏幕外的(看不见的)元素
高优先级的比如键盘输入(希望立即得到反馈),低优先级的比如网络请求,让评论显示出来等等。另外,紧急的事件允许插队
这样的优先级机制存在2个问题:
- 生命周期函数怎么执行(可能被频频中断):触发顺序、次数没有保证了
- starvation(低优先级饿死):如果高优先级任务很多,那么低优先级任务根本没机会执行(就饿死了)