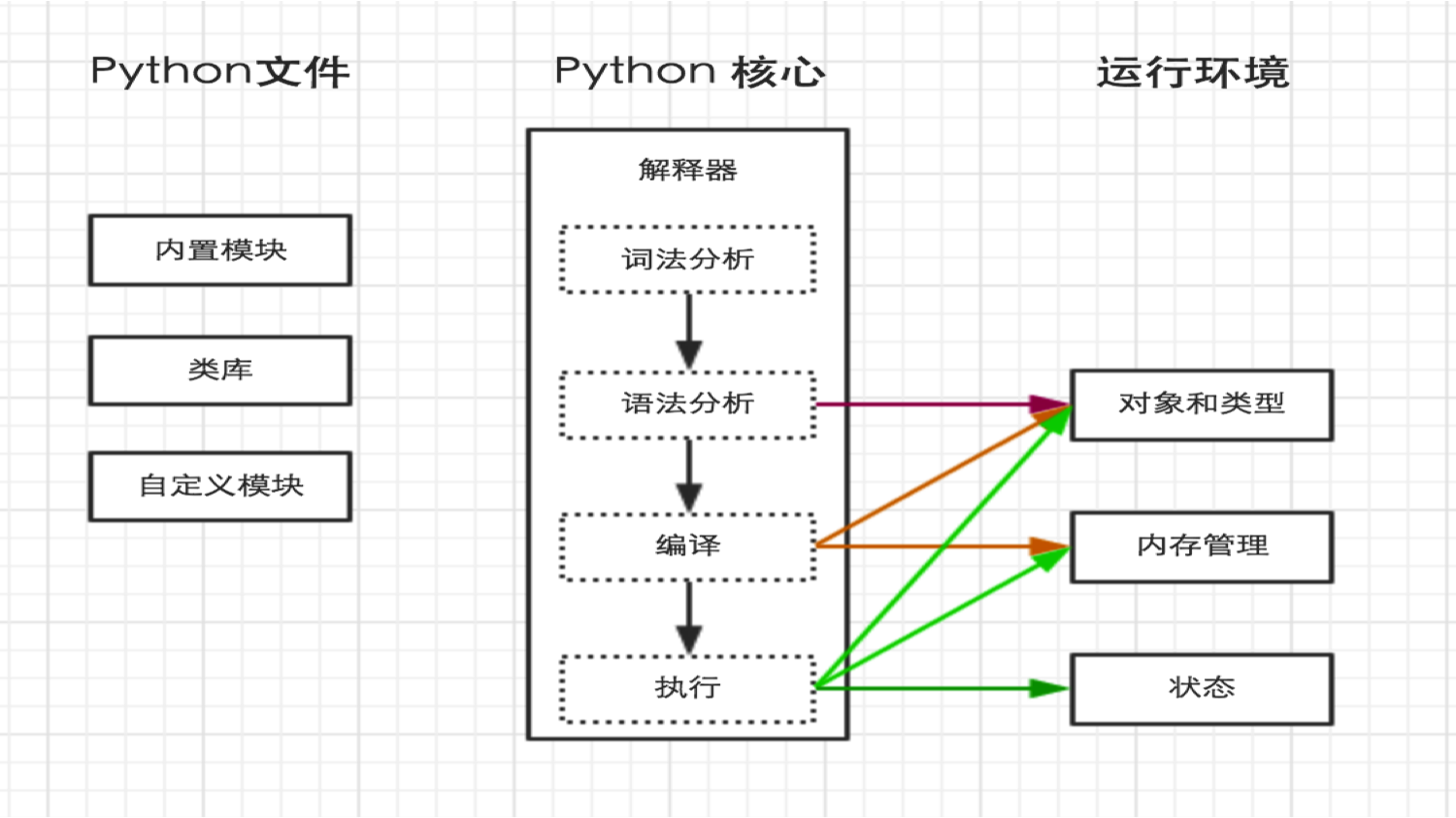
python内部执行流程
编码
默认情况下,Python3源码文件以UTF-8编码,所有字符串都是Unicode字符串。当然也可以为源码文件指定不同的编码:
# -*- coding: cp-1252 –*-
1. ASCII
python2的解释器在加载.py文件中的代码时,会对内容进行编码(默认ASCII)
ASCII是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用8位来表示(1个字节),即:2**8=256.所有ASCII码最多只能表示256个符号


2. Unicode
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode规定所有的字符和符号最少由16位来表示(2个字节),即:2**16=65536
3.UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到4个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。它不在使用最少两个字节,而是对所有的字符和符号进行分类:ASCII码中的内容使用1个字节、欧洲字符使用2个字节、东亚字符使用3个字节……
标识符
在编程语言中,标识符就是程序员自己规定的具有特殊含义的词,比如:类名、函数名、属性名、变量名等。
- 第一个字符必须是字母表中的字符或者下划线“_”
- 标识符的其他部分可以由字母、数字和下滑线组成
- 标识符区分大小写
- python3中,非ASCII标识符也是允许的
以下划线开头的标识符具有特殊意义。以单下划线开头(_foo)的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用“from *** import ***”而导入;以双下划线开头的(__foo)代表类的私有成员;以双下划线开头和结尾的(__foo__)代表python里的特殊方法专用的标识,如__int__()代表类的构造函数。
python保留字
保留字即关键字,不能把保留字用作任何标识符名称。Python的标准库提供了一个keyword module,可以输出当前版本的所有关键字:
>>> import keyword >>> keyword.kwlist ['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
注释
Python中的单行注释以#开头
#!/usr/bin/env python # coding=utf-8 # 第一行注释 print("hello world!") # 第一行注释 """ 多行 注释 """ ''' 多行 注释 '''
行与缩进
python中通过使用缩进来表示代码块,不需要使用大括号“{}”,缩进的空格数是可变的,但是同一个代码块语句的缩进空格数必须一致。
if True: print("True") else: print("False")如果缩进不一致,会导致运行错误
#!/usr/bin/python3 # -*- coding: UTF-8 -*- # 文件名:test.py if True: print("Answer") print("True") else: print("Answer") # 没有严格缩进,在执行时保持 print("False")le "/****/****", line10print("False") ^ IndentationError: unexpected indent
单语句多行
python通常一行写完一个语句,但如果语句很长,可以使用反斜杠“”来实现多行语句,例如:
A = "a" B = "b" C = "c" abc = A + B + C在”[]”、”{}”、”()”中的不需要使用反斜杠“”,例如:
A = {"a", "b", "c"} B = """keep live""" C = '''home work'''
数据类型
- 数字
- 布尔值
- 字符串
- 列表
- 字典
- 元组
空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数的入口之间也用一行空行分隔,以突出函数入口的开始。空行与代码缩进不同,空行并不是python语法的一部分。书写时不插入空行,python解释器也不会报错。但是空行可以分隔两段不同功能或含义的代码,便于日后的维护和重构。
注:空行也是程序代码的一部分
多语句单行
python中可以在同一行中使用多条语句,语句之间使用分号“;”分隔。
如下实例:
#!/usr/bin/python3 import sys; x = 'runoob'; sys.stdout.write(x + ' ')
多个语句构成代码组
缩进相同的一组语句构成一个代码块,我们称之为代码组。像if、while、def、class这样的复合语句,首行以关键字开始,以冒号“:”结束,该行之后的一行或多长代码构成代码组。我们将首行及后面的代码组成为一个子句(clause)。
如下实例:
if expression : suite elif expression : suite else : suite
.pyc文件
执行Python代码时,如果导入了其他的.py文件,那么在执行过程中会自动生成一个与其同名的.pyc文件,该文件就是python解释器编译之后产生的字节码
注:代码经过编译可以产生字节码,字节码通过反编译也可以得到代码