并发控制是数据库理论里面最难的课题之一
并发控制首先了解一下事务,transaction
定义如下,


其实transaction关键是,要满足ACID属性,
左边的正式的定义,由于的intuitive的理解
其中可能Consistency比较难理解一下,其他都比较直观,对于单机数据库而言consistency其实不是个显著的问题,但对于分布式数据库这就是个主要问题


那么问题就是如何设计让Transaction满足ACID?
一种简单的方法就是,Strawman System
串行执行保障consistency和isolate,整个库的copy保障atomicity,这个方法早期用在SQLlite中,它主要是用在嵌入式场景,访问量和数据量都很小
但这个方法的性能太低

下面就看看对ACID的各个属性,一般是如何设计来满足的
Atomicity
原子性问题,
最常用的方法是Log,Undo&Redo,这样如果事务abort,可以根据undo日志来回滚,达到原子性保证
还有种方法是Shadow Paging,也是MVCC,我修改的时候,把要修改的page复制一份去改,典型的使用是CouchDB


Consistency
首先Consistency是逻辑的,什么意思?
就是和实现无关,做一笔转账,两边的数据在逻辑上应该是对的,无论你底层是如何实现的,用何种数据结构
所以database consistency是指,做过的更新,在更新后,无论从什么地方角度去看,他都应该是一样的,比如在不同的transaction中,不同的client,不同的。。。
对于单机数据库,这其实是比较容易达成的
transaction consistency,是指应用层面的,外部的一致性,不光是数据库内部的,这种一致性需要应用自己去保障



Isolation
隔离性,每个transaction执行的时候,不会受到其他的transaction的干扰
因为我们要提高数据库的性能,所以不可能让transaction串行执行,所以transaction一定是并发执行的,这样一定会存在interleave的问题
因为把transaction在物理上去做隔离一定是比较低效的,所以实际的做法都是让各个transaction interleave的执行,但其中要注意避免冲突,conflict
避免冲突一般都是要加锁,所以自然会有悲观和乐观锁的分别

这里先不谈怎么避免冲突
我们先看下interleave执行会带来哪些问题?
对于这个例子,两个transaction,一个是转账,一个是加利息
T1,T2,如果顺序执行的结果是一样的
这里注意,T1,T2本身谁先执行,这个是要应用控制的,对于数据库而言,无论谁先执行都是对的


那么可以看到interleave执行的结果可能是good,也可能是bad
如果判断是好是坏?这个很直觉,和串行执行结果一样就是好的,否则就是坏的



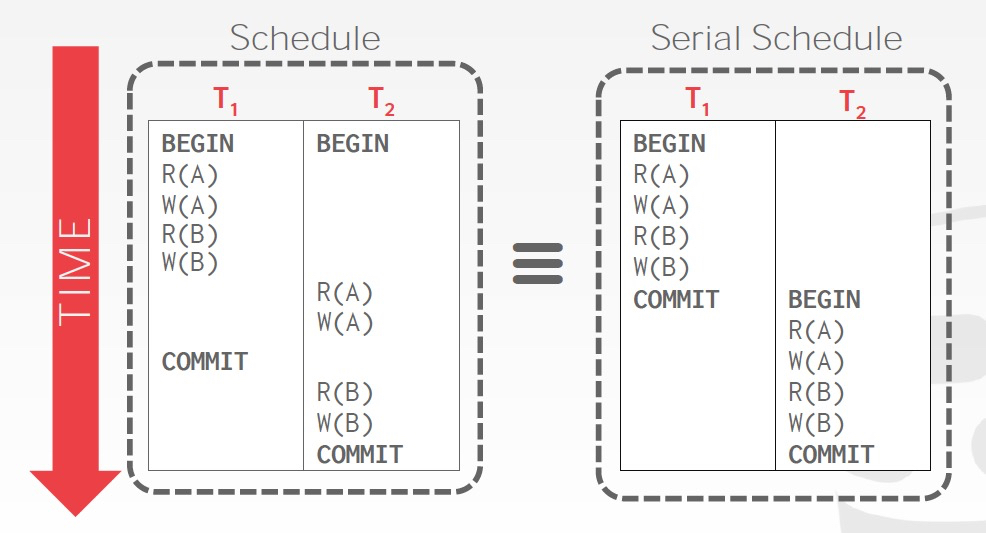
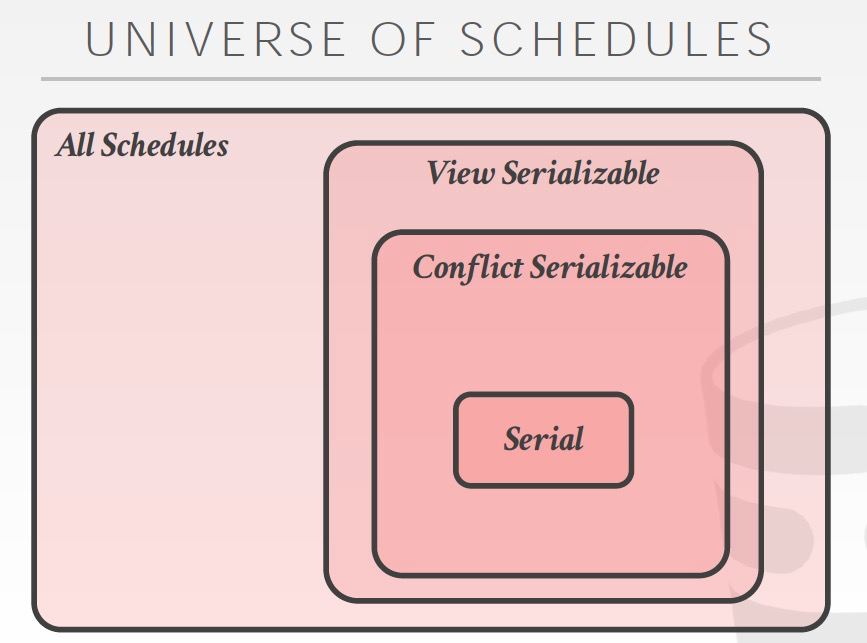
所以这里给出一堆概念,只是就是想说明,你interleave执行的结果一定要和串行执行一样
这样给transaction调度带来很大的flexible,因为只要满足serializable schedule,就可以任意的并发调度
Serializable Schedule的定义,一个Schedule和任意一个Serial Schedule是Equivalent的,即执行结果相同


那么我们怎么判断一个sechdule是否是serializable?
我们先看看,如果不满足serializable schedule,会发生什么?Conflict
冲突的双方一定是在不同的transaction中,并且其中至少有一个是write操作
所以Conflict分为3种,read-read是不会冲突的
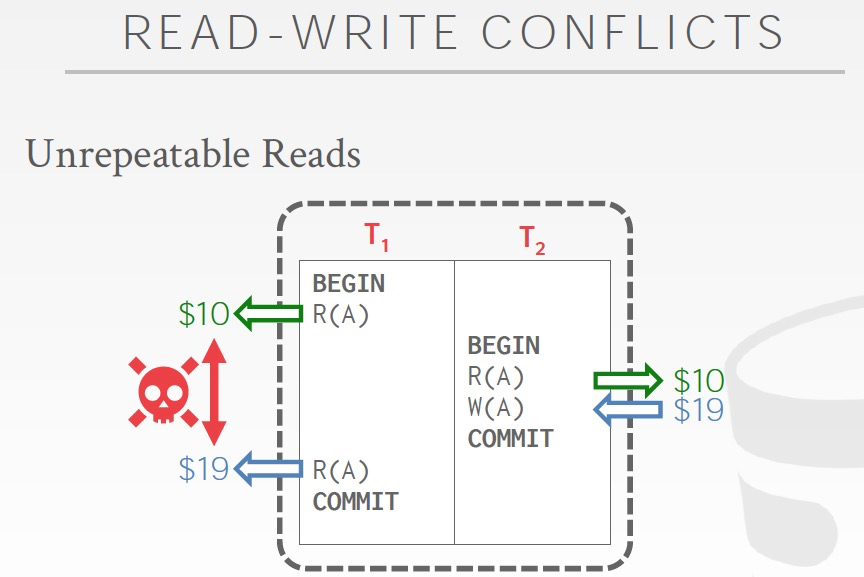
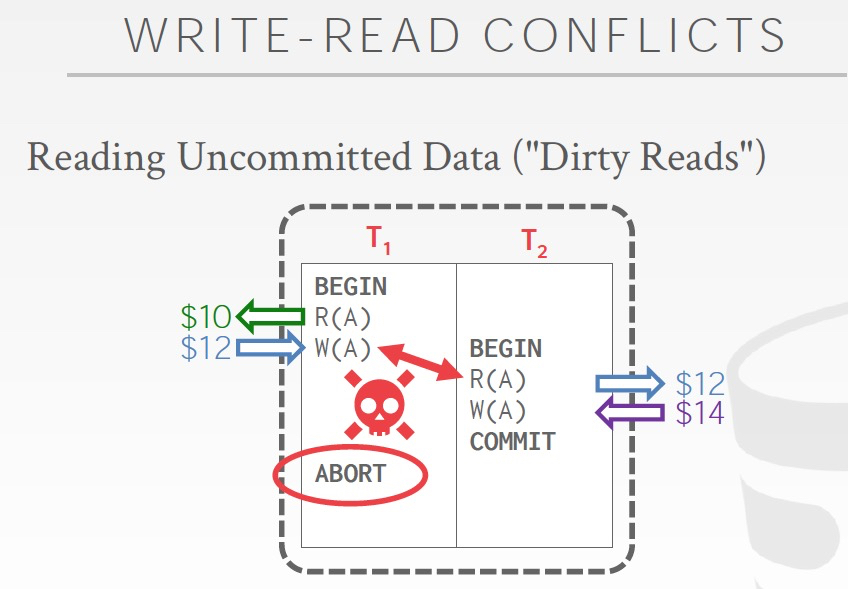

那么现在的思路,我们只要去看看sechdule中是否存在这些conflict,如果不存在,我们就可以认为这个sechdule是serializable
形式化的表达就是,如果S是和任意一个serial schedule冲突等价的,那么S就是conflict serializable;因为如果存在上面的冲突就不可能和serial schedule冲突等价
这里需要注意,我们判断冲突的时候,一般只会看是否同时对一个object有读写,比如对于Unrepeatable Read,我们不会看后面还是不是有那个read,或者对于dirty reads,如果后面没有abort,也不会有问题;
所以这里是充分但不必要条件,不满足conflict serializable,也不一定就得到错误的结果,但是满足,得到的结果一定是正确的

下面就要找一种方法,可以判断S是否是conflict serializable
我们可以把任意不冲突的operation进行swap,看看最终能不能变成一个serial schedule

例子,
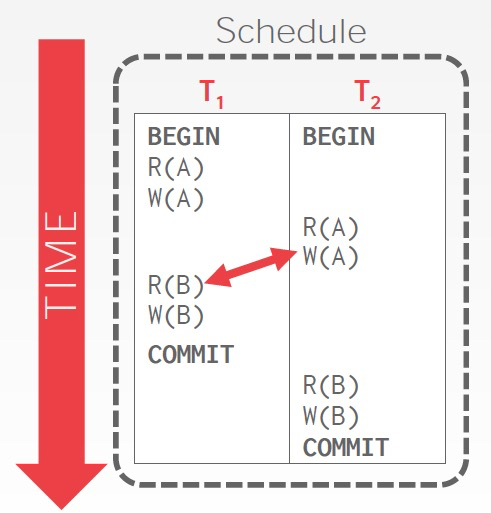
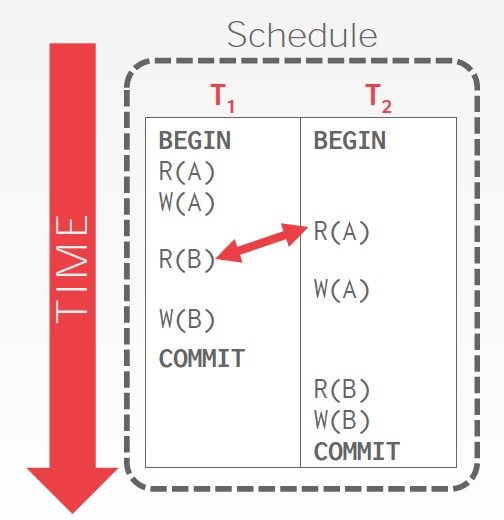
这个方法看着比较简单,但如果transaction比较多的话,会很难操作
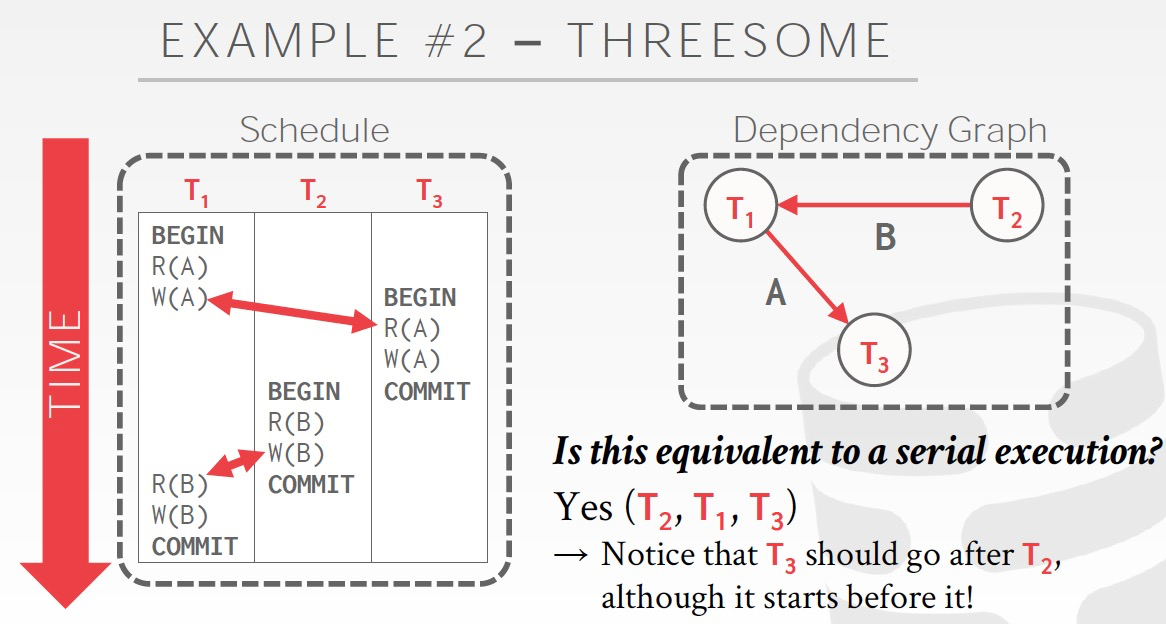
所以需要一个更形式化的方法,称为依赖图
其实就是把冲突的依赖用线连起来,如果有环,说明是无法conflict serializable的


比如,你看右边的例子,是无法conflict serializable的
而example2,是可以conflict serializable,因为依赖图里面没有环
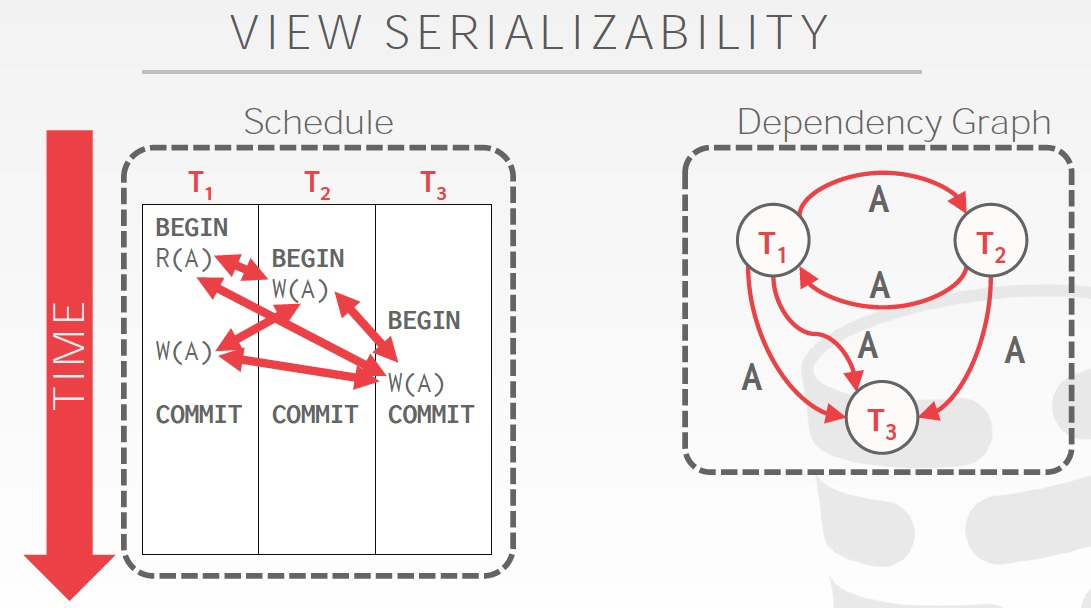
前面讲的都是Conflict Serialization
还有一种更为宽泛的叫做,View Serialization
定义很难理解,从例子上看,就是有些不符合conflict serialization的case,算出来结果也是对的,比如例子里面,因为是blind write,所以A的结果只会有最后一个write决定,所以这个schedule还是可以强行等价于一个serial schedule的

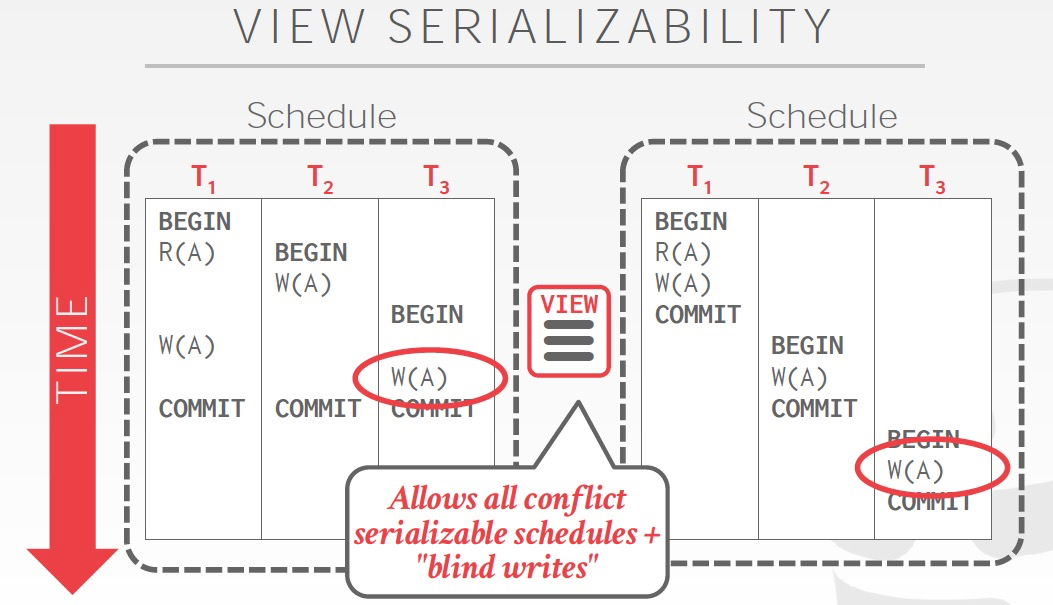
View Serialization可以比Conflict Serialization有更多,更灵活的schedule,但是这个难于判断,很难实现


所以总体来说,关系是这样的,越大调度越灵活,但是机制和判断越复杂
Durability
