本文的主要目的是,引入DataBlocks,解决hybrid数据库的问题

Hybrid系统难点,在于AP和TP在很多方面,优化思路是矛盾的
比如compression,对于ap可以提升查询性能因为降低带宽使用,但是对于TP反而降低了查询性能,因为查询的时候需要解压,而且影响索引

所以大部分Hybrid系统的策略,都是提供read-optimized和write-optimized两部分
但是这样明显不是很优雅,而且merge过程是个很重的操作
所以这里提出的方案是,
将关系表切分成固定大小的chunks,带轻量的压缩,不可变的datablocks

并且为了提升查询速度引入轻量的PSAM索引,

最后再看下,如果使用向量化和JIT来提升hybrid查询的能力,
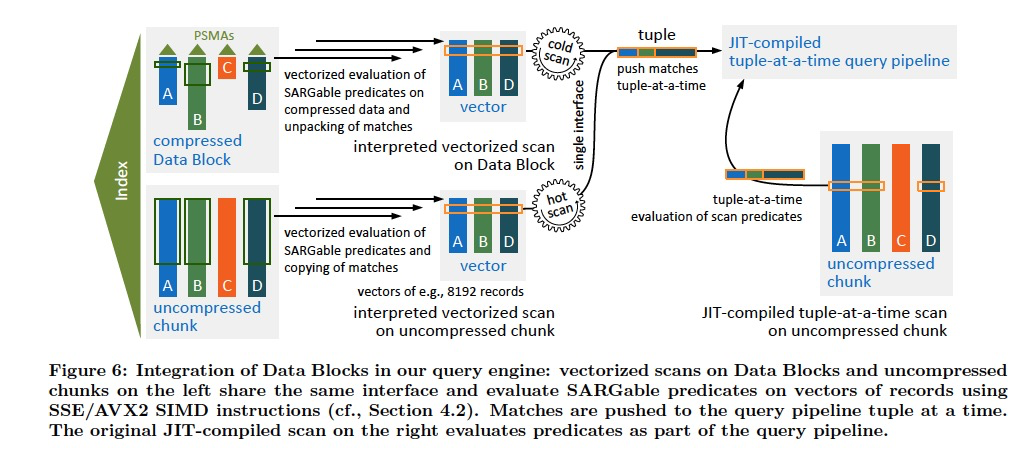
上面描述了JIT和向量化的区别,两者虽然都是降低tuple处理的Cpu指令数,但是JIT通过寄存器传数据,而向量化要通过主存
并且向量化对于TP作用不大,是因为TP往往不会scan数据,touch很少数据时,向量化就没有作用了
所以本文提出一直,fuse向量化和JIT的优化方式,
用基于解释的向量化的scan子系统,把数据feeds给JIT编译的tuple-at-a-time执行pipeline

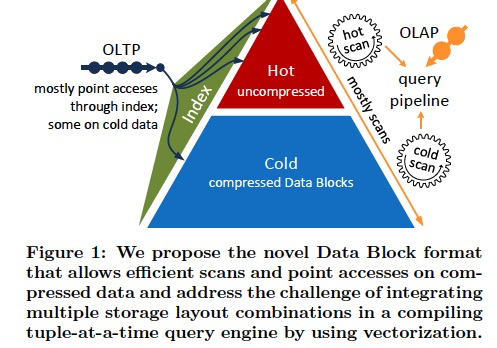
DataBlocks
Hyper是内存数据库,内存是有限的,所以通过压缩就可以节省内存
但是压缩后会影响TP和AP的性能,这里提出的DataBlocks的方案,在使用压缩的情况下,还可以保证TP和AP的性能不降低
首先对于hot数据是不压缩的,也是没有SMA索引的,这样保证TP写入的性能不会受影响,
当数据变成cold的时候,才会把data chunk转化为data block,那么如何在压缩的情况下,还可以快速检索
可以看到DataBlocks主要包含下面几个特性,
1. 优化的压缩方式,保证比较好的压缩率
2. 仅仅使用支持byte-addressable的压缩方式,只有这样才能快速的跳数据块,快速检索
3. 支持SARGable scan,就是简单的条件过滤,可以直接在压缩数据上match,不需要解压缩
4. 包含SMA和PSMA索引

这里说了SMA和PSMA都是只用于cold数据,避免影响tp写入

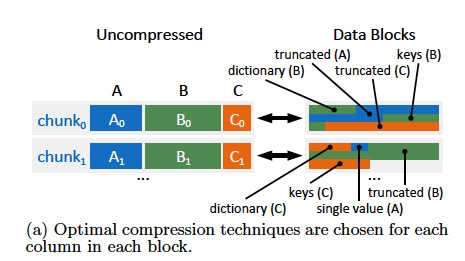
Data blocks的layout,如右图所示,
首先是tuple count,
然后是各个列的相关属性的offsets
接着就是真实的data,
列存,所以是一个列,一个列,排过去的
每一列包含,SMA,PSMA索引,字典,data,string
一列存完再存下一列


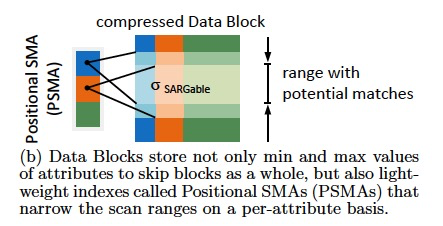
Positional SMAs
SMA,Small Materialized Aggregates,其实就是记录每个block的最大,最小值

PSMA,记录max,min可以对于predicate进行prune,但是如果落在max,min中,如果需要没有其他的索引辅助,那么只能scan
所以这里引入PSMA,用一个lookup table来记录scan range,

lookup表具体如下,
算法如右图,
由于用小值的精确性比较高,所以用delta做index,
这个原理是用index的最高非零byte来做索引,因为算法加上r*256所以低位的byte都一样的,所以最高非零位一样的value都会被index到同一个entry中
所以对于4-byte,查询表需要4*2的8次方个entry,因为每个byte里面的每个值都需要一个entry
所以如果都是比较大的值,那么会都集中在某一段entry中,所以用delta

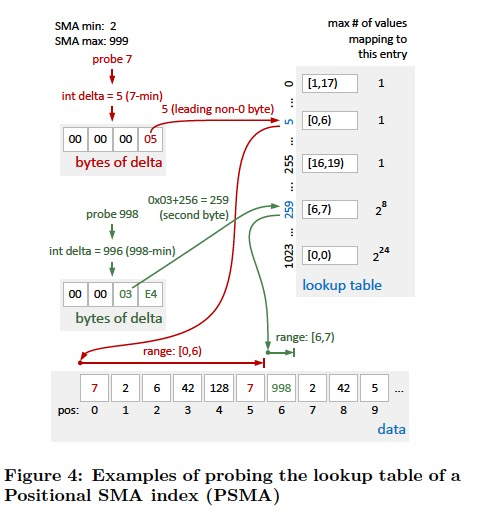

所以PSMA比传统的基于tree的索引更小,因为它不是精确索引,只是给出一个range
但如果相同的值range分的很散,那么PSMA就不是那么有效了,最好是相同值clustered的情况

Attribute Compression
这里主要说了,哪些压缩方法是可以做到byte-addressable的

VECTORIZED SCANS IN COMPILING QUERY ENGINES
如果压缩算法的选择在block和column的级别,因为这样可以针对不同的数据类型和分布提升压缩率,但是也会导致不同的物理表示
这样就可JIT带来很大的挑战,因为生成代码的时候,需要兼容所有的storage layout,分支比较多的情况下,会导致编译的代码爆炸

所以这里提出的方案是,
把Scan和处理Pipline分离开
Scan部分用解释执行,而Pipeline部分用JIT,这样可以通过解释执行得到的数据,feed给compiled的pipeline