简单研究一下一直播视频爬取。
原理非常的简单,代码也比较容易。
我所研究的是视频,也就是直播的回放,并不是实时的直播,但我简单看了一下,实时直播虽然要复杂一些但工作原理也差不多,由于没有需求我就没有写代码了。
1.视频是ts格式的视频文件流,比如0.ts 1.ts 2.ts 一直到视频结束的xxx.ts
2.所有视频文件的列表在index.m3u8的GET请求中
3.请求的URL在html中有给出,视频流是由CDN节点分发的。
4.弹幕的话在get_playback_event的GET请求中,其请求的的方法是每隔3个ts请求一次(我没有仔细看他是每隔3个ts请求一次还是以计时的方式请求),这样一来也导致了这个网站的一个bug,视频快进后,弹幕却不变仍然按之前的速度走。弹幕请求返回的是json格式的数据
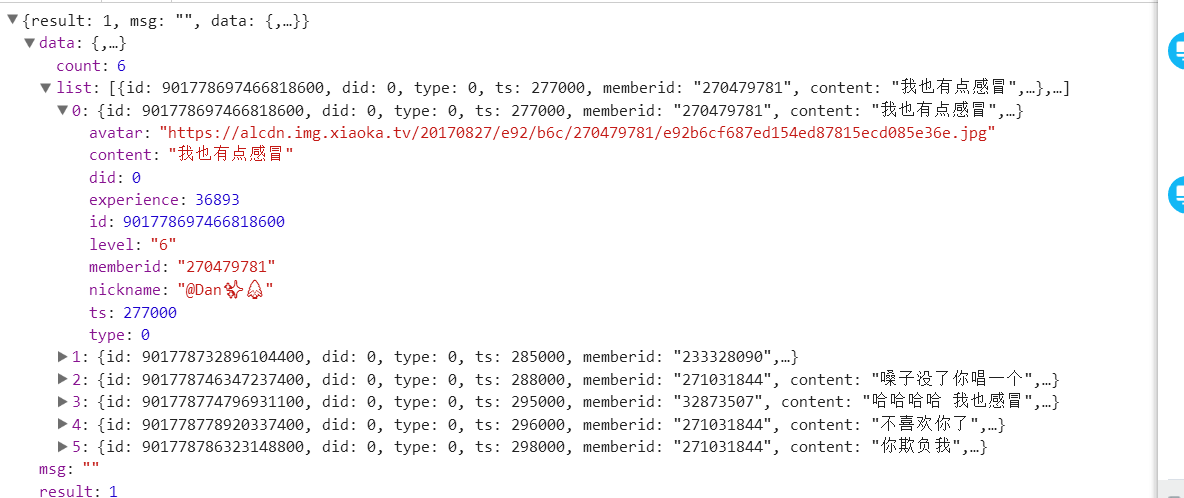
由于我并不需要弹幕,所以没有写弹幕的代码,其他代码如下。我们只需要输入视频的播放地址,运行程序即可以自动下载。
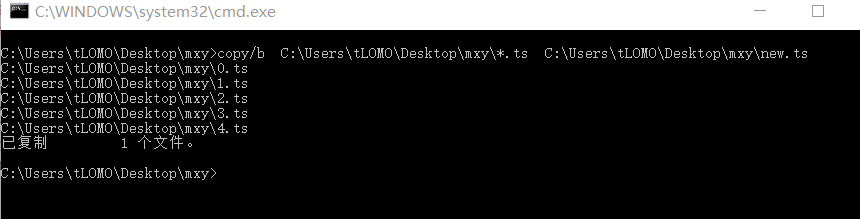
最后我们会得到众多的ts文件,其可以直接在播放器中播放,将这些文件合并为一个,我们只需要在cmd中运行以下程序即可,当然我们可以直接用python来运行cmd命令。
程序代码:
#-*- coding:utf-8 -*-
import requests,re,urllib2,chardet,os
from multiprocessing.dummy import Pool
def urllink(link): #网页HTML获取以及编码转换
while 1:
try:
print '正在打开',link
html_1 = urllib2.urlopen(link, timeout=15).read()
print '打开成功',link
break
except:
print '失败重试',link
encoding_dict = chardet.detect(html_1)
web_encoding = encoding_dict['encoding']
if web_encoding == 'utf-8' or web_encoding == 'UTF-8':
html = html_1
else :
html = html_1.decode('gbk','ignore').encode('utf-8')
return html
def download(j):
url='https://%s%s'%(link,str(j))+'.ts'
for l in range(20):
try:
retu = requests.get(url, stream=True)
print str(j).zfill(5)+' 下载完成'
break
except:
print u'%s文件,正在重试第%d次' % (str(j).zfill(5),l + 1)
picpath = unicode(r'C:Users LOMODesktopmxy\%s' % str(j).zfill(5) + '.ts', 'utf-8')
file = open(picpath, 'wb')
for chunk in retu.iter_content(chunk_size=1024 * 8):
if chunk:
file.write(chunk)
file.flush()
file.close()
if __name__=="__main__":
url=raw_input('请输入视频地址:')
html=urllink(url)
link=re.search('play_url:"http://(.*?)index.m3u8',html,re.S).group(1)
m3u8='https://'+link+'index.m3u8'
list=requests.get(m3u8).text
count=int(re.findall('(.*?).ts',list.split('
')[-2],re.S)[0])
print '共计:',count
list=[i for i in range(count+1)]
pool = Pool(4)
pool.map(download, list)
pool.close()
pool.join()
print '全部下载完成,正在合并'
os.system(r'copy/b C:Users LOMODesktopmxy*.ts C:Users LOMODesktopmxy
ew.ts')
print '合并完成'