F1相关的论文两篇,
F1: A Distributed SQL Database That Scales
F1 Query: Declarative Querying at Scale
F1: A Distributed SQL Database That Scales
F1是一个Globally-distributed的数据库系统,用于替换传统的Sharded Mysql,用于Google的广告系统

目标,
可以简单scaleup,传统的sharded mysql,扩容是很麻烦的,因为要重新分shard
高可用
并且保证ACID

这篇文章的主要贡献,为了达到这些目标,做的trade-off和sacrifices
F1是架构在Spanner上,所以可扩展存储,同步副本,强一致性,全局有序这些事由spanner保证的,那么其实对于F1而言设计就可以比较轻了


F1做了存储分离,分布式的设计,自然和传统Sharded Mysql比,latency会增加并难以控制,
F1解决延迟的方法,主要是两个,一个是hierarchical关系表,一个是大量使用batch,并行和异步


基本架构,
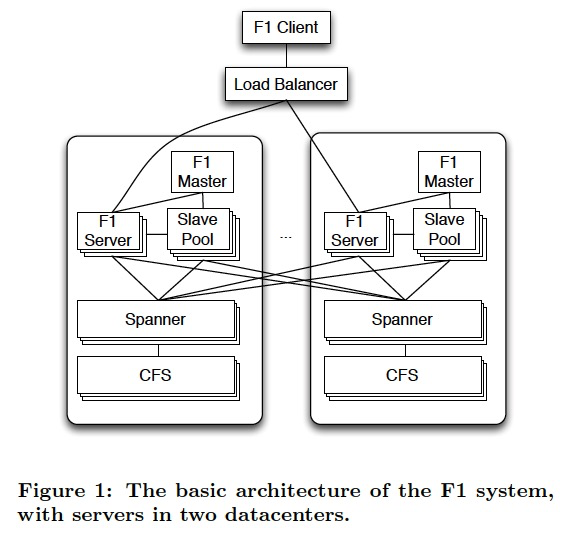
F1 server作为查询引擎,和Spanner和CFS是分离的,但为了就近查询,部署的时候这些系统是co-located
最关键的,F1 server是无状态的,这样就可以随意scale up


F1,有一个slave pool,由master管理,普通的查询用不到,但是如果需要使用分布式查询的时候,那么就需要用slave pool里面的F1 processes扩大并行度

Data Model
前面说了,F1为了避免延迟不稳定的问题,提出的解决方案
Hierarchical Schema,看右边的图,其实很容易理解,就用冗余,去范式化
这样的好处,避免join;数据会clustered,这对分布式数据库很关键;update成本低,因为数据都clustered在一起

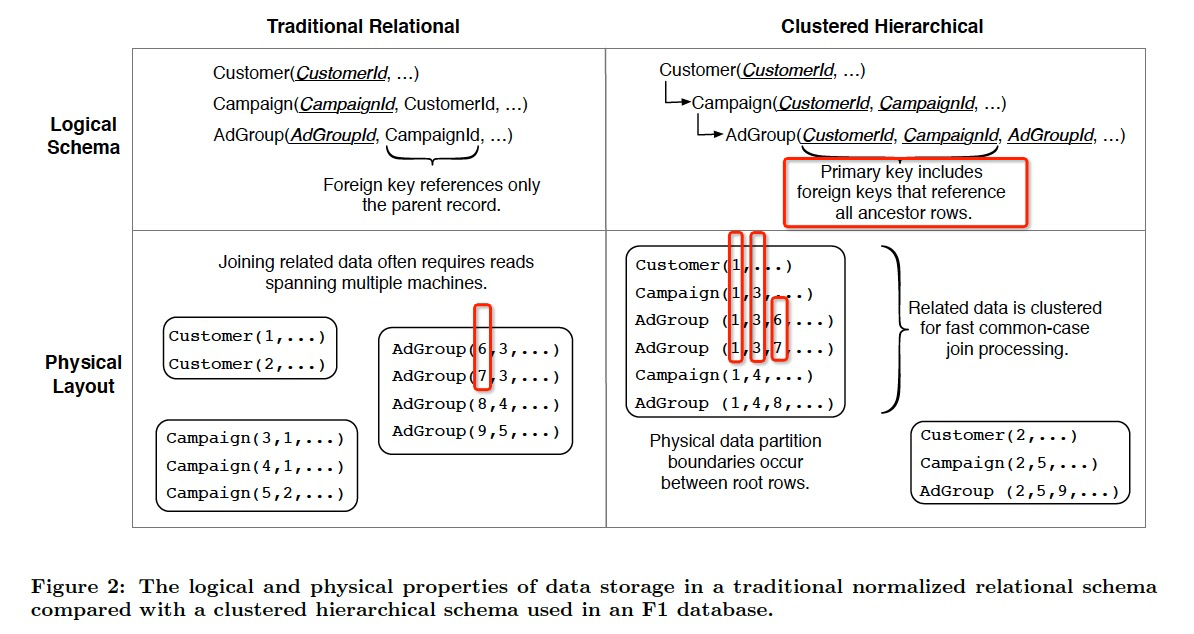
使用Protocol Buffer

索引,
独立的索引表,事务性的,强一致性
index分为local和global,全局索引和row无关,如果大的事务需要更新大量的全局索引,一定会影响查询性能,因为也要保证索引的事务性
这里的建议,少用global索引,尽量用小事务

Schema Change
SchemaChange的难点主要是因为,对于分布式数据库,如何保证原子性和同步;如何保证change的过程中,不影响读写和可用性

F1说为了避免影响可用性,一定要异步,但是异步就会导致不一致,同时不同的F1server会用不同的shema更新数据库
怎么解决?
schema change算法,
首先,保证同时最多只有两个schema active,并且没有schema都有lease,哪怕网络不通,过期后无法使用
再者,把schema change切分成multiple phase,保证phase之间是没有冲突的
这里没有太详细说,参考reference

Transaction
这里提出,最终一致性,对于应用的开发者的负担是很重的,因为需要很多逻辑去处理各种错误,乱序,迟到的数据
所以F1要求保证强一致性

F1支持如下几种事务,
Snapshot用于只读事务
悲观事务,直接用Spanner就可以
乐观事务,F1默认使用,每一行都有一个隐藏column存最新的commit更新时间,每次返回row的时候会带上,
这样client再次commit的时候,会开一个小事务去check更新时间是否发生变化


乐观锁的好处不言而喻,坏处,

并且这里的行锁,也可以变成column级别,更细粒度的锁

本篇最关键的是,F1是构建在Spanner之上的,存储和计算分离,所以把复杂的部分放到存储,F1是无状态的,所以他说的,Scaleup,可用性,一致性就都已经解决了;
然后再分享一些经验,包含data model,schema change,事务等
F1 Query: Declarative Querying at Scale
F1 Query提出了数据库系统的理想形式,cover大家对于数据库的所有需求,太牛逼了,如果不是google提的,一定会被人骂

F1 query是上一篇F1的进化版本,
区别在于,更彻底的,federated query引擎,兼容更多的data source;而F1只是读,Spanner和Mesa的数据

F1的需求有哪些,
比较核心的,
数据是碎片化的,存在很多存储系统里面
云原生架构,存储和计算分离,带来的问题是,latency的high variance

架构
其实这篇论文的主要内容在overview就已经讲完了
他不是发明了一种引擎来解决所有的问题,而是把之前所有的方案集成到一个db里面
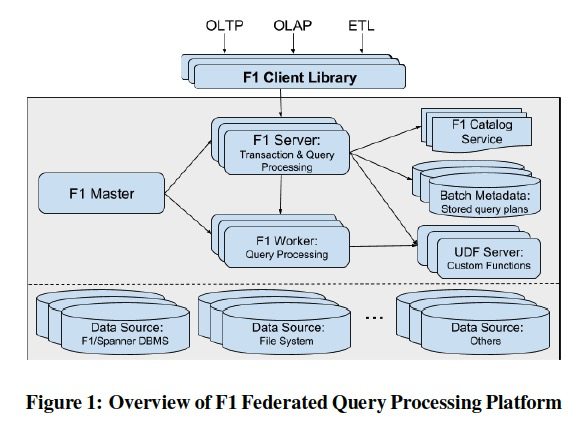

查询执行
查询的执行考虑到就近原则,哪怕google的网络很牛逼,近些还是快的

执行的过程如下,
SQL parse,优化,生成物理执行计划后,
和普通的执行不一样,这里先要区分是Interactive执行,还是Batch执行
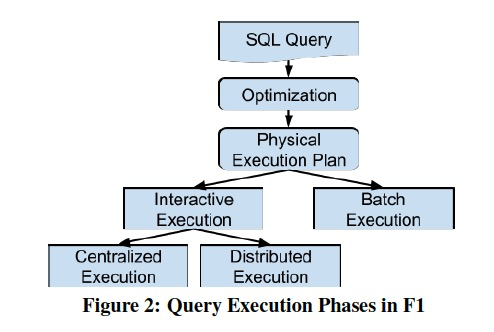
DataSources
对于多种datasources,需要提供一种关系型的抽象,像Hive一样,右边是例子,


论文后面还讲了一些细节,但没有太多特别的东西,有兴趣的可以看看