主导的学习组件,是query-based,workload-driven,以一堆有代表性的queryset去实际运行,产生训练集。
The predominant「占主导的」 approach for learned DBMS components is that they capture the behavior of a component by running a representative set of queries over a given database and use the observations to train the model.
For example, for learned cost models such as [16, 42] different query plans need to be executed to collect the training data, which captures the runtime (or cardinalities), to then learn a model that can estimate costs for new query plans.
This observation also holds for the other approaches such as learned query optimizers or the learned query processing schemes, which are also based on collected training data that requires the execution of a representative workload.
这种方式的问题,在于训练成本很高,并且需要不断迭代,当workload变化时
A major obstacle「障碍」 of this workload-driven approach is that collecting the training data is typically very expensive since many queries need to be executed to gather enough training data.
For example, approaches like [16, 42] have shown that the runtime of hundreds of thousands of query plans is needed for the model to provide a high accuracy.
Still, the training corpora often only cover a limited set of query patterns to avoid even higher training costs.
For example, in [16] the training data covers only queries up to two joins (three tables) and filter predicates with a limited number of attributes.
Moreover, the training data collection is not a one-time effort since the same procedure needs to be repeated over and over
if the workload changes or if the current database is not static and the data is constantly being updated as it is typical for OLTP.
Otherwise, without collecting new training data and retraining the models for the characteristics of the changing workload or data, the accuracies of these models degrade with time.
本文是采用另一种思路,data-driven,就是直接对于数据建模,并且模型可以同态的变化,接受insert,update,delete
data-driven好处,和workload无关,你workload,查询变了,不会有影响,适用面也比较广,但是问题在于数据如果很大这个成本也是非常的高。
In this paper, we take a different route.
Instead of learning a model over the workload, we propose to learn a purely data-driven model that captures the joint probability distribution of the data
and reflects important characteristics such as correlations across attributes but also the data distribution of single attributes.
Another important difference to existing approaches is that our data-driven approach supports direct updates;
i.e., inserts, updates, and deletes on the underlying database can be absorbed by the model without the need to retrain the model.
As a result, since our model captures information of the data it can not only be used for one particular task
but supports many different tasks ranging from query answering, over cardinality estimation to potential other more sophisticated tasks such as in-DBMS machine learning inference.
One could now think that this all comes at a price and that the accuracy of our approach must be lower since the workload-driven approaches get more information than a pure data-driven approach.
However, as we demonstrate in our experiments, this is not the case. Our approach actually outperforms many state-of-the-art workload-driven approaches and even generalizes better.
However, we do not argue that data-driven models are a silver bullet to solve all possible tasks in a DBMS.
Instead, we think that data-driven models should be combined with workload-driven models when it makes sense.
For example, a workload-driven model for a learned query optimizer might use the cardinally estimates of our model as input features.
This combination of data-driven and workload-driven models provides an interesting avenue for future work but is beyond the scope of this paper.
其实本文的关键就是提出RSPN来表示数据
To summarize, the main contributions of this paper are:
(1) We developed a new class of deep probabilistic models over databases: Relational Sum Product Networks (RSPNs), that can capture important characteristics of a database.
(2) To support different tasks, we devise a probabilistic query compilation approach that translates incoming database queries into probabilities and expectations for RSPNs.
(3) We implemented our data-driven approach in a prototypical DBMS architecture, called DeepDB, and evaluated it against state-of-the-art learned and non-learned approaches.
什么是PSPN?先看什么是SPN
SPN是network,但是出于简单的考虑,先看tree的结构
有两种节点,
一种是sum node,把数据进行聚类并进行划分,对于数据库就是把rows分成几块
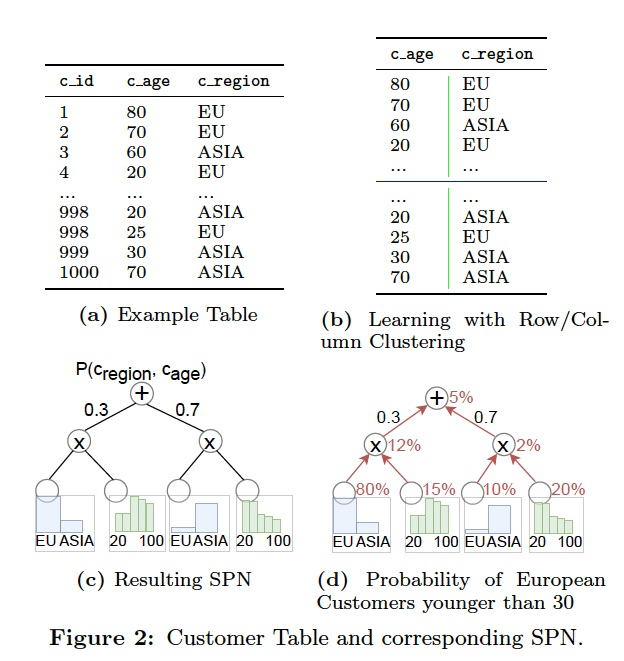
拿下面的例子看,就是把example table分成两部分,一块是30%,欧洲的老年人,一块是70%,亚洲的年轻人,但是这种划分不是绝对的,只是比例上
一种是product node,把数据在独立的维度上进行投影,对于数据库就是独立的列
拿下面的例子看, 分成age和region两个维度
叶子节点存放的是,每个维度的数据分布,可以用Histogram,linear function来表示
For the sake of simplicity, we restrict our attention to Tree-SPNs, i.e., trees with sum and product nodes as internal nodes and leaves.
Intuitively, sum nodes split the population (i.e., the rows of dataset) into clusters and product nodes split independent variables of a population (i.e., the columns of a dataset).
Leaf nodes represent a single attribute and approximate in the present paper the distribution of that attribute either using histograms for discrete domains or piecewise linear functions for continuous domains [29].
如何生成SPN?
简单的说,对于sum node,就是聚类问题,可以用传统的KMeans
对于product node,是相关性判断问题,需要找出独立的columns,为什么只有独立才能在product node分开,因为是要product,只有独立的column相乘才是合理的
Learning SPNs [10, 29] works by recursively splitting the data in different clusters of rows (introducing a sum node) or clusters of independent columns (introducing a product node).
For the clustering of rows, a standard algorithm such as KMeans can be used or the data can be split according to a random hyperplane.
To make no strong assumptions about the underlying distribution, Randomized Dependency Coefficients (RDC) are used for testing independence of different columns [23].
Moreover, independence between all columns is assumed as soon as the number of rows in a cluster falls below a threshold nmin.
As stated in [35, 28], SPNs in general have polynomial(多项式) size and allow inference in linear time w.r.t. the number of nodes.
However, for the configurations we use in our experiments, we can even bound the size of the SPNs to linear complexity w.r.t. the number of columns in a dataset
since we set nmin = ns=100 (i.e. relative to the sample size), which turned out to be a robust configuration.
怎么用SPN?
直接看上面的例子,2d,欧洲,大于30岁的比例,这就是在算Cardinality
每个叶子节点得到相应filter的比例,然后后面在product node相乘,在sum node,加权相加,最终得到结果
With an SPN at hand, one can compute probabilities for conditions on arbitrary columns.
Intuitively, the conditions are first evaluated on every relevant leaf.
Afterwards, the SPN is evaluated bottom up.
For instance in Figure 2d, to estimate how many customers are from Europe and younger than 30,
we compute the probability of European customers in the corresponding blue region leaf nodes (80% and 10%)
and the probability of a customer being younger than 30 (15% and 20%) in the green age leaf nodes.
These probabilities are then multiplied at the product node level above, resulting in probabilities of 12% and 2%, respectively.
Finally, at the root level (sum node), we have to consider the weights of the clusters, which leads to 12% 0:3 + 2% 0:7 = 5%:
Multiplied by the number of rows in the table, we get an approximation of 50 European customers who are younger than 30.
RSPN就是对于SPN的扩展
主要体现在以下几点上,
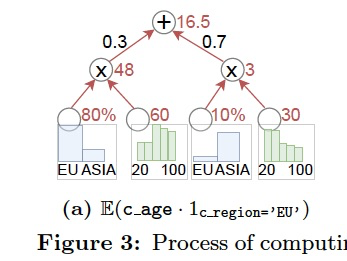
a. 支持聚合值,avg,sum
如下图中,计算欧洲客户的平均年龄
b. 支持直接更新
The key-idea to support direct updates of an existing RSPN is to traverse the RSPN tree top-down and update the value distribution of the weights of the sum-nodes during this traversal。
c. 支持多表的数据表示
In order to support ad-hoc join queries one could naively learn a single RSPN per table as we discuss in Section 4.
However, in this case potential correlations between tables might be lost and lead to inaccurate approximations.
For learning an ensemble of RSPNs for a given database with multiple tables, we thus take into account if tables of a schema are correlated.
下图的例子,我们既可以用两个独立的RSPN来学习两个表,也可以用一个RSPN学习Full Outer Join后的表。
采用哪一种方式取决于两个表的相关性,如果相关性比较高,就需要采用ensemble RSPN学习Join后的结果表
In this procedure, for every foreign key-primary key relationship we learn an RSPN over the corresponding full outer join of two tables if there is a correlation between attributes of these two tables.
