接口
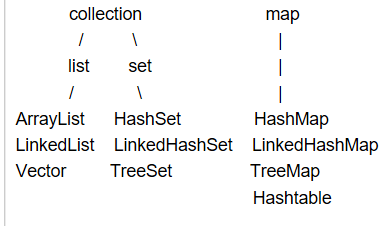
[四个接口 collection list set map 的区别]
collection 存储不唯一的无序的数据
list 存储有序的不唯一的数据
set 存储无序的唯一的数据
map 以健值对的形式存储数据 以键取值 键不能重复 值可以重复
list接口
1.常用方法
①add方法 在列表的最后添加元素
②add(index.object)在此列表中的指定位置插入指定的元素。
③size() 返回此列表中的元素个数。
④get(int index)返回下标为index的元素
如果没有泛型约束,返回object类型,需要强转,如果有泛型约束,直接返回泛型类型,无需强转,
⑤clear方法,清除列表中的所有数据
⑥contains() 传入一个对象检测列表中是否含有对象
如果传入的是string和基本数据类型,可以直接对比
如果传入的是实体对象,则默认只对比两个对象的地址
⑦indexof ,传入一个对象,返回此列表该对象的第一次出现的下标,如果此列表不包含元素,则返 回-1。
lastindexof返回最后一次
⑧ remove传入一个下标或一个对象,删除指定元素
如果传入下标,返回被删除的元素对象,如果下标大于 汇报下标越界
如果传入对象,则要求重写equals方法,返回true或者是false表示删除是否成功
⑨set 用指定的元素替换此列表中指定位置的元素。 返回被替换掉的元素对象
⑩subList 截取一个子列表,返回list类型
toArray 将列表转为数组,返回一个object[]类型的数组
ArrayList
实现了一个长度可变的数组,在内存空间中开辟一串连续的空间,与数组的区别在于长度可以随意修改。
这种存储结构,在循环遍历和随机访问元素的速度比较快。
LinkedList
使用链表结构存储数据,在插入和删除元素时速度非常快。
LinkedList的特有方法:
① addFirst(): 开头插入元素
addLast(): 结尾插入元素
② removeFirst(): 删除第一个元素,并返回被删除的元素。
removeLast(): 删除最后一个元素,并返回被删除的元素。
③ getFirst(): 返回列表第一个元素,不会删除
getLast(): 返回列表最后一个元素,不会删除
Vector 线程安全
LinkedList 线程不安全
Set接口
常用方法:与List接口基本相同。
但是,由于Set接口中的元素是无序的,因此没有与下标相关的方法。
例如: get(index) remove(index) add(index,obj) ....
Set接口的特点: 唯一、 无序;
HashSet 底层是调用HashMap的相关方法,传入数据后,根据数据的hashCode进行散列运算,
得到一个散列值后在进行运算,确定元素在序列中存储的位置。
HashSet如何确定两个对象是否相等?
① 先判断对象的hashCode( ),如果hashCode不同,那肯定不是一个对象。 如果hashCode相同,那继续判断equals( )方法;
② 重写equals( )方法。
public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Person other = (Person) obj; if (age != other.age) return false; if (id != other.id) return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; return true; }
>>>所以,使用HashSet存储实体对象时,必须重写对象的hashCode( ) 和 equals( ) 两个方法!!
LinkedHashSet: 在HashSet的基础上,新增了一个链表。
用链表来记录HashSet中元素放入的顺序,因此使用迭代器遍历时,可以按照放入的顺序依次读出元素。
TreeSet: 将存入的元素,进行排序,然后再输出。
如果存入的是实体对象,那么实体类必须实现Comparable接口,并重写compareTo()方法;
或者,也可以在实例化TreeSet的同时,通过构造函数传入一个比较器:
比较器: 一个实现了Comparator接口,并重写了compare()方法的实现类的对象。
使用匿名内部类,拿到一个比较器对象。
Set<Person> set = new TreeSet<Person> (new Comparator( ){ public int compare(Person p1, Person p2){ return p1.getId( ) - p2.getId( ); } });
自定义一个比较类,实现Comparator 接口。
Set<Person> set = new TreeSet<Person>(new Compare( )); class Compare implements Comparator( ){ 重写compare方法。 }
【Comparable接口 和 Comparator接口的区别】
1、 Comparable由实体类实现,重写compareTo()方法;
实体类实现Comparable接口以后,TreeSet使用空参构造即可。
2、 Comparator需要单独一个比较类进行实现,重写Compare()方法。
实例化TreeSet的时候,需要传入这个比较类的对象。
Map接口
Map接口特点 以健值对的形式存储数据 以及按键取值
键不能重复 值可以重复
Map接口常用方法
①put(key ,value)向map的最后添加一个键值对
②get(key) 通过键,取到一个值
③clear() 删除所有内容
④containsValue() 检测是否包含指定的值
containsKey() 检测是否包含指定的键
LinkedHashSmap
可以使用链表, 用链表来记录元素放入的顺序,可以按照放入的顺序依次读出元素。
TreeMap
根据键的顺序 进行排序后输出
如果存入的是实体对象,那么必须重写比较函数;
HashMap与Hashtable的区别
1.Hashtable是线程安全的 (线程同步) HashMap是线程不安全的(线程不同步)
2.Hashtable的键不能为null HashMap的键可以为null
3.HashMap继承了AbstractMap,HashTable继承Dictionary抽象类,两者均实现Map接口。
4.HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75。
5.HashMap扩容时是当前容量翻倍即:capacity*2,Hashtable扩容时是容量翻倍+1即:capacity*2+1。
6.两者计算hash的方法不同:
Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模:
HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸:
7.在HashMap 中不能用get()方法来判断HashMap 中是否存在某个键,而应该用containsKey()方法来判断。Hashtable 的键值都不能 为null,所以可以用get()方法来判断是否含有某个键。
遍历map的方式
第一种
Set<String> keys =map1.keySet(); Iterator<String> iter=keys.iterator(); while (iter1.hasNext()) { String key=iter.next(); System.out.println(key+"----"+map.get(key)); }
第二种
Collection<String> va=map.values(); Iterator<String> iter=va.iterator(); while (iter.hasNext()) { System.out.println(iter.next()); }
第三种
Set<Entry<String,String>> set= map.entrySet(); Iterator<Entry<String, String>> iter=set.iterator(); ① while (iter.hasNext()) { Entry<String, String> entry=iter.next(); //entry是Java给我们提供的一种特殊的数据类型 其实就是一个键值对 //键就是当前这条记录的键,使用getkey()取到 //值就是当前这条记录的值,使用getValue()取到 System.out.println(entry.getKey()+""+entry.getValue()); } ② for(Entry<String, String> y:set){ System.out.println(y.getKey()+"----"+y.getValue()); }