一、准备
该准备工作在三台机器上都需要进行,首先使用 vmvare 创建 1 个虚拟机,这台虚拟机是 master,一会需要把 master 克隆出两台 slave

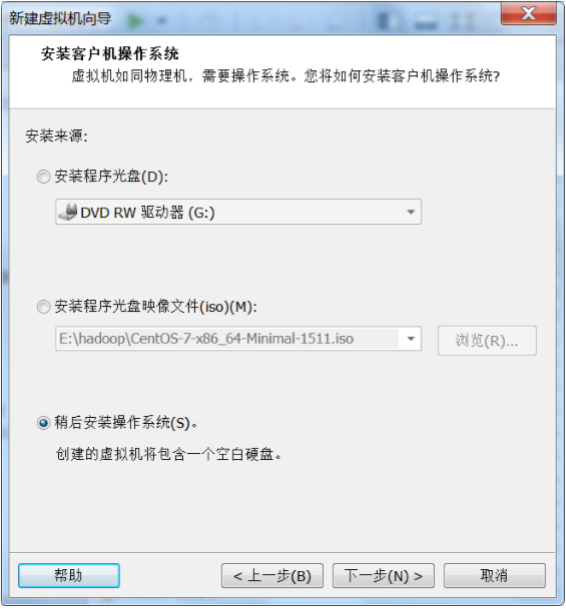
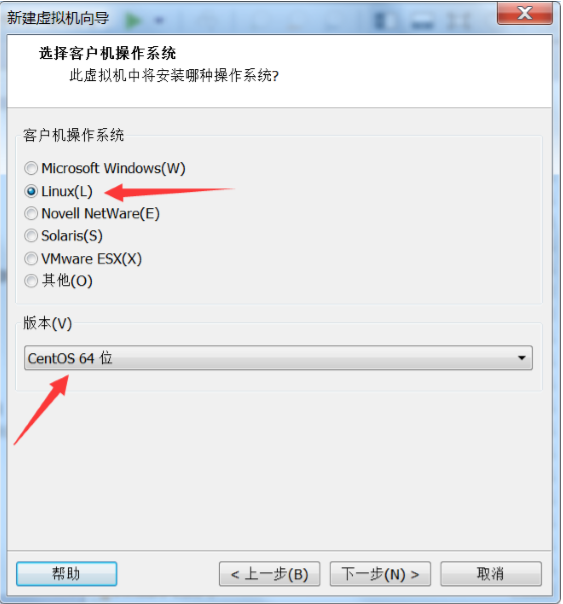

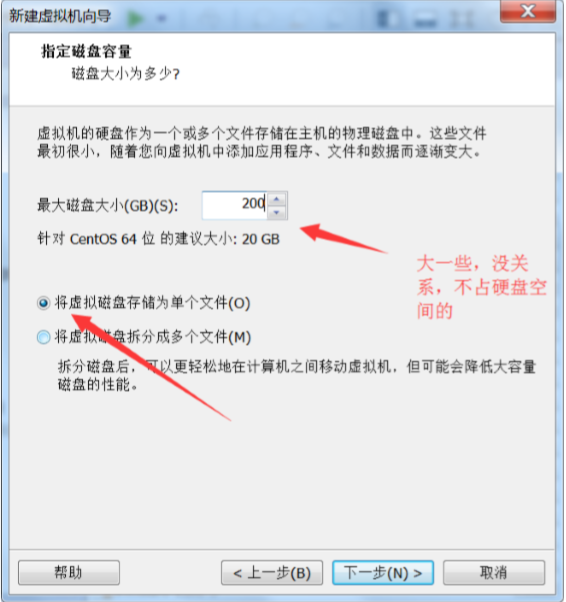
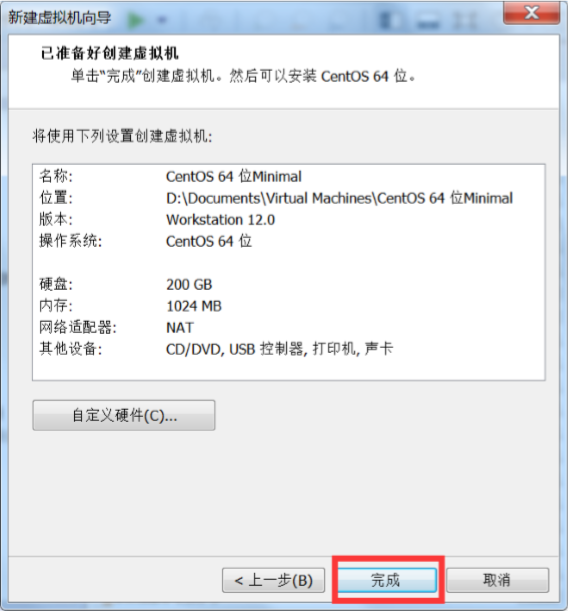
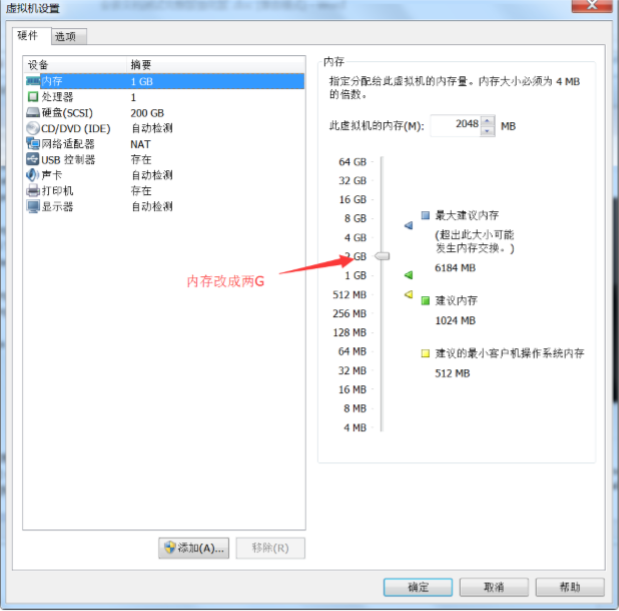
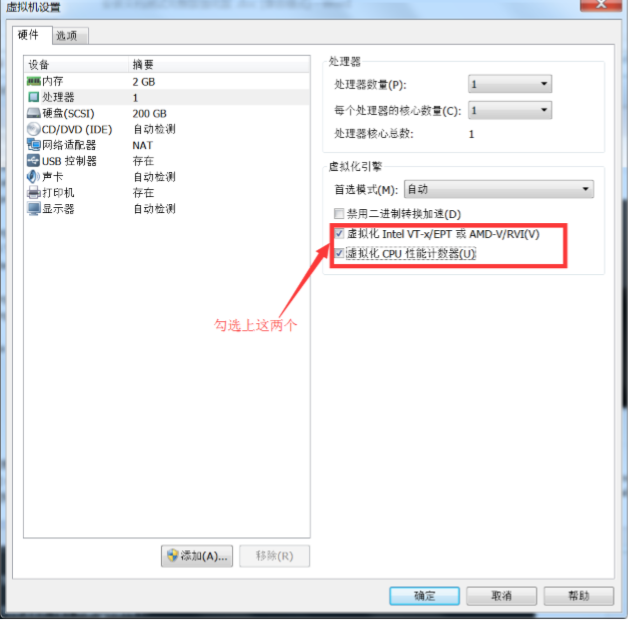

点确定然后开启此虚拟机

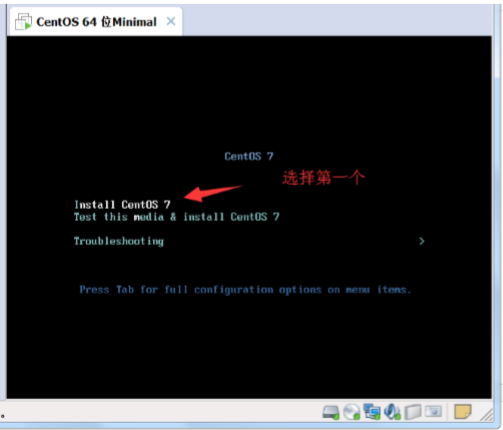

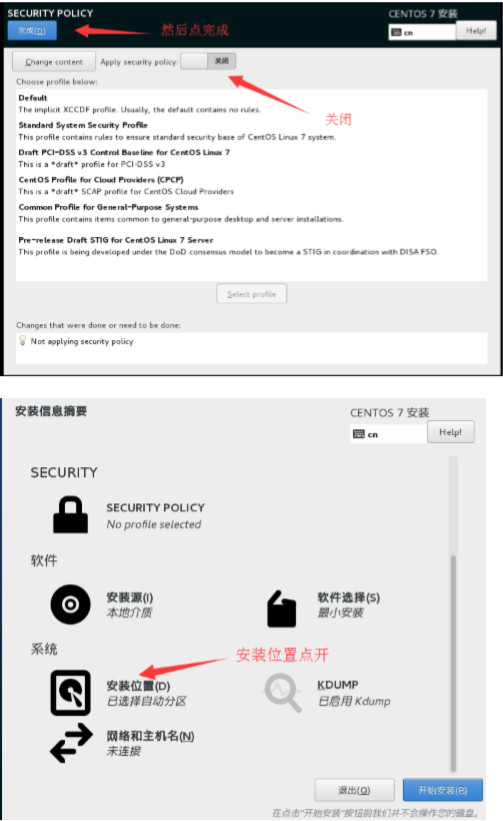
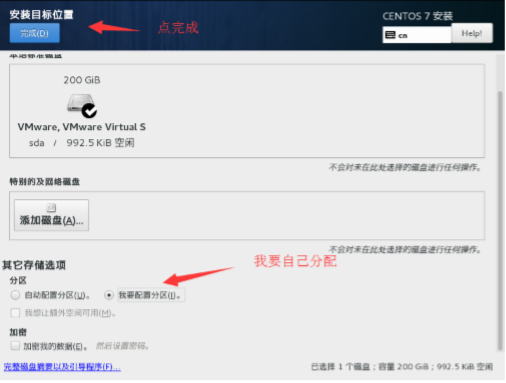
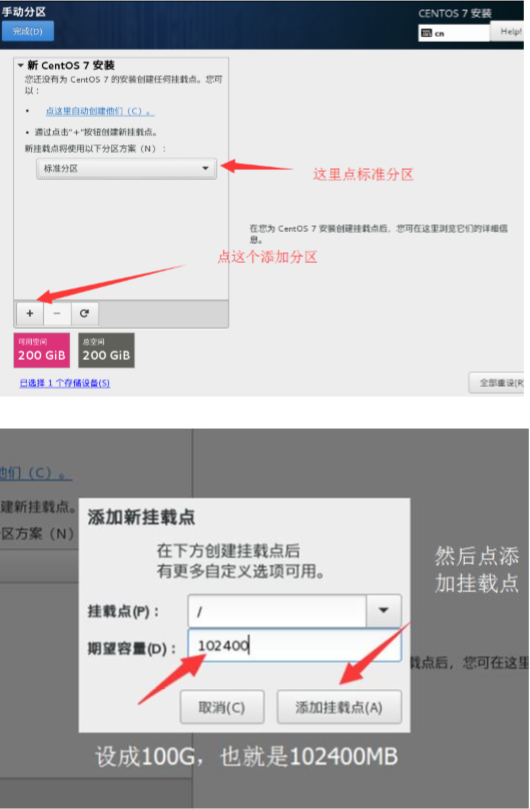
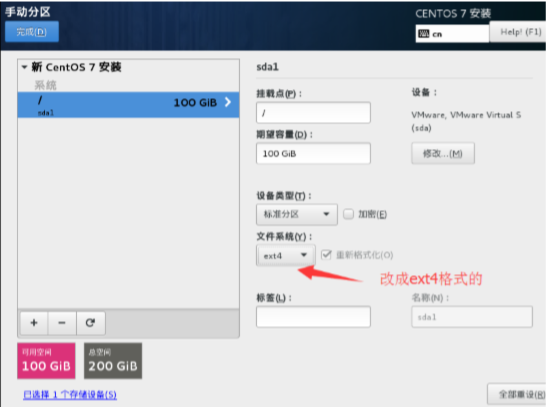
然后添加/boot 分区,大小为 1G,文件系统选 ext4

然后添加 swap 分区,注意,swap 分区为内存的 2 倍,文件系统则选择为 swap
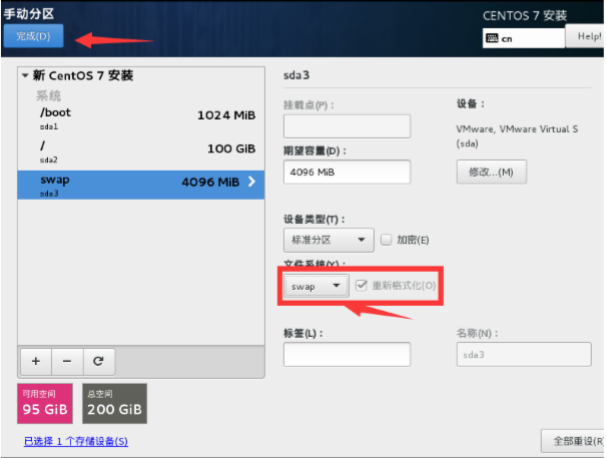
然后点完成
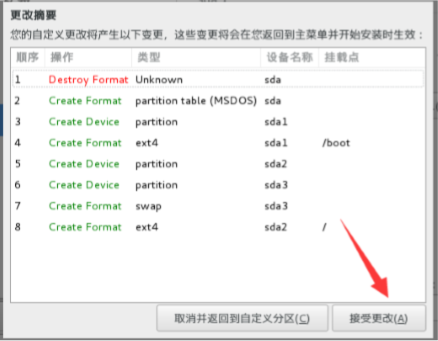




然后等待安装完成,然后点重启
到此系统安装就完成了,然后设置网络


点完确定后,然后再进去查看下网关
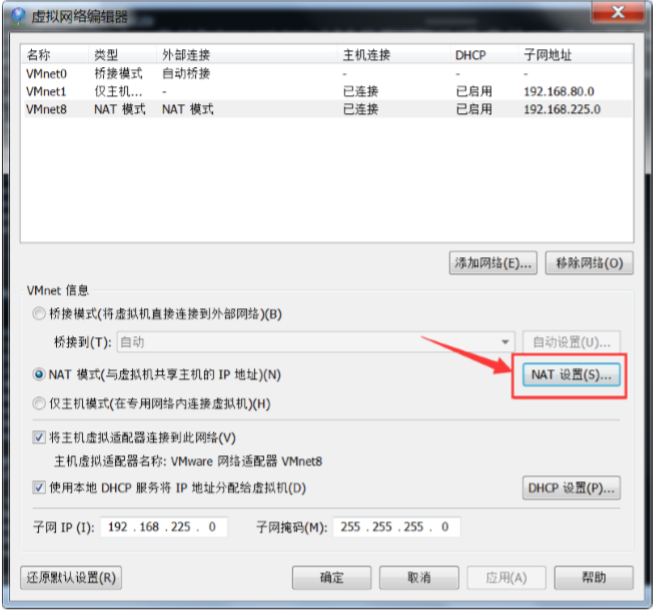
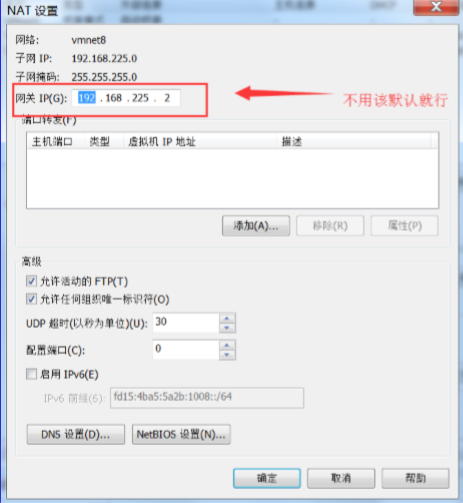
点取消,记住这个网关
1、我先换下主机名
[root@localhost ~]# hostnamectl set-hostname wangmaster [root@localhost ~]# hostname wangmaster [root@localhost ~]# exit
2、重新登录,然后设置网卡
[root@wangmaster ~]# vi /etc/sysconfig/network-scripts/ifcfg-eno16777736 TYPE=Ethernet BOOTPROTO=static DEFROUTE=yes PEERDNS=yes PEERROUTES=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_PEERDNS=yes IPV6_PEERROUTES=yes IPV6_FAILURE_FATAL=no NAME=eno16777736 DEVICE=eno16777736 ONBOOT=yes //启用网卡 IPADDR=192.168.225.100 //设置 IP NETMASK=255.255.255.0 //设置掩码 GATEWAY=192.168.225.2 //设置网关,就是记住的网关 DNS1=114.114.114.114 //设置 DNS DNS2=114.114.114.115 //设置备用 DNS [root@wangmaster ~]# systemctl restart network.service //重启网络
3、设置网络 YUM 源
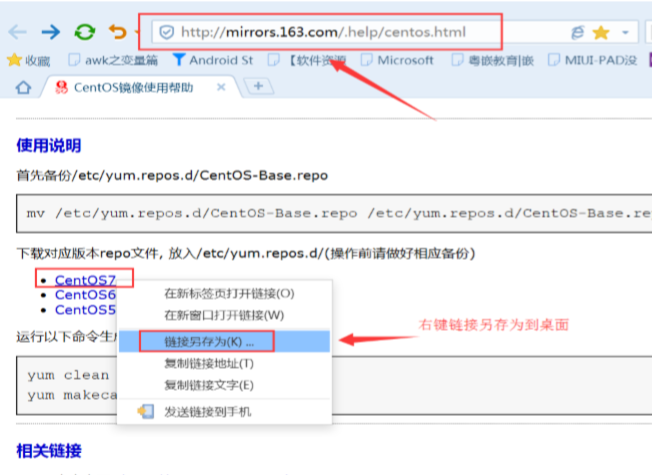
选择远程登录工具登录操作 (可以用Xshell)
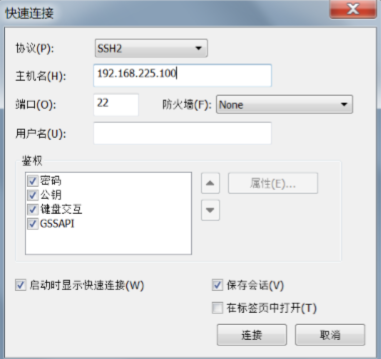
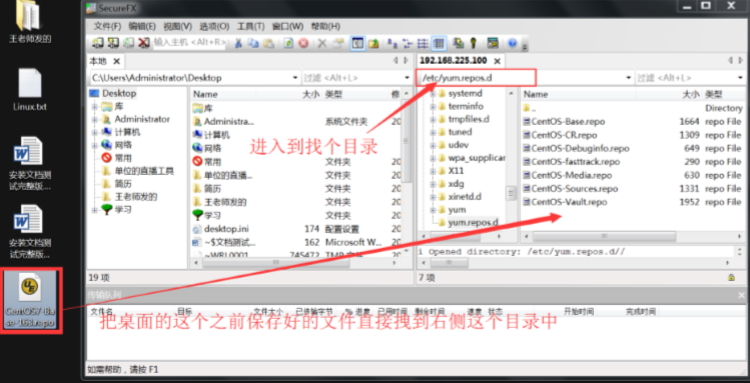
点击文件传输按钮,进入Xftp软件,进行传输文件。

将上面保存的文件传入/etc/yum.repos.d文件夹下。
[root@wangmaster ~]# cd /etc/yum.repos.d/ [root@wangmaster yum.repos.d]# ls CentOS7-Base-163.repo CentOS-Debuginfo.repo CentOS-Sources.repo CentOS-Base.repo CentOS-fasttrack.repo CentOS-Vault.repo CentOS-CR.repo CentOS-Media.repo [root@wangmaster yum.repos.d]# mv CentOS-Base.repo CentOS-Base.repo.bak //使原来的 yum 失效 [root@wangmaster yum.repos.d]# yum clean all //清除 yum 缓存 已加载插件:fastestmirror 正在清理软件源: base extras updates Cleaning up everything [root@wangmaster yum.repos.d]# yum repolist //更新 yum 库 已加载插件:fastestmirror base | 3.6 kB 00:00 extras | 3.4 kB 00:00 updates | 3.4 kB 00:00 (1/4): base/7/x86_64/group_gz | 155 kB 00:00 (2/4): extras/7/x86_64/primary_db | 139 kB 00:00 (3/4): base/7/x86_64/primary_db | 5.6 MB 00:09 (4/4): updates/7/x86_64/primary_db | 3.9 MB 00:11 Determining fastest mirrors 源标识 源名称 状态 base/7/x86_64 CentOS-7 - Base - 163.com 9,363 extras/7/x86_64 CentOS-7 - Extras - 163.com 311 updates/7/x86_64 CentOS-7 - Updates - 163.com 1,126 repolist: 10,800 [root@wangmaster yum.repos.d]# [root@wangmaster yum.repos.d]# yum install -y vim //安装 VIM 工具
4、关闭 selinux
[root@wangmaster yum.repos.d]# vim /etc/selinux/config # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of three two values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are pro tected. # mls - Multi Level Security protection. SELINUXTYPE=targeted
5、停止防火墙功能
[root@wangmaster ~]# systemctl stop firewalld.service 停止防火墙 [root@wangmaster ~]# systemctl disable firewalld.service 停止防火墙开机自启动 [root@wangmaster ~]# systemctl status firewalld 查看防火墙状态
6、规划为 3 个虚拟机,分别为 master,slave1,slave2,在/etx/hosts 文件中修改
[root@wangmaster ~]# vim /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.225.100 wangmaster 192.168.225.101 wangslave1 192.168.225.102 wangslave2
然后重启虚拟机(一定要重启,因为 selinux 设置重启才生效)
(注意:在所有三台虚拟机中都进行这样的修改,ip 地址根据实际情况进行修改)
7、使用如下命令在线安装
[root@wangmaster ~]$ yum install –y wget [root@wangmaster ~]$ yum install –y net-tools
8、创建目录
[root@wangmaster ~]# mkdir /opt/bigdata
9、将 jdk 拷贝到 192.168.225.100 的 opt 的 bigdata 目录
[root@wangmaster bigdata]# ls hadoop-2.7.3.tar.gz jdk1.8.tar.gz 这里我提前在 bigdata 中传入了所需要的软件
10、在 master 中创建用户 hadoop
[root@wangmaster bigdata]# useradd hadoop [root@wangmaster bigdata]# id hadoop uid=1000(hadoop) gid=1000(hadoop) 组=1000(hadoop) [root@wangmaster ~]# passwd hadoop 更改用户 hadoop 的密码 。我设置的密码是 123456,需要打两遍 新的 密码: 无效的密码: 密码少于 8 个字符 重新输入新的 密码: passwd:所有的身份验证令牌已经成功更新。 [root@wangmaster ~]#
11、使用户成为 sudoers,以 root 用户修改文件/etc/sudoers,修改方式如下:
[root@wangmaster bigdata]# vim /etc/sudoers ## Allow root to run any commands anywhere root ALL=(ALL) ALL hadoop ALL=(ALL) ALL
12、修改/opt/bigdata 文件夹的权限
[root@wangmaster ~]# chmod -R 777 /opt/bigdata [root@wangmaster ~]# chown -R hadoop.hadoop /opt/bigdata [root@wangmaster ~]# ll /opt 总用量 4 drwxrwxrwx. 2 hadoop hadoop 4096 4 月 9 05:28 bigdata
13、安装 JDK 运行环境
[hadoop@wangmaster bigdata]# tar -zxvf jdk1.8.tar.gz [hadoop@wangmaster bigdata]# mv /opt/bigdata/jdk1.8 /opt/bigdata/ hadoop@wangmaster bigdata]# ls hadoop-2.7.3.tar.gz jdk1.8 jdk1.8.tar.gz opt
14、在修改/etc/profile 文件,配置 java 环境:
[root@wangmaster ~]$ vim /etc/profile #java configuration JAVA_HOME=/opt/bigdata/jdk1.8 JAVA_BIN=/opt/bigdata/jdk1.8/bin PATH=$PATH:$JAVA_HOME/bin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar export JAVA_HOME export JAVA_BIN export PATH export CLASSPATH [hadoop@wangmaster ~]# source /etc/profile [hadoop@wangmaster bigdata]$ java -version java version "1.8.0_111" Java(TM) SE Runtime Environment (build 1.8.0_111-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode) [hadoop@wangmaster bigdata]$ javac -version javac 1.8.0_111
(注:上图中,JAVA_HOME 为你安装的 JDK 路径)
15、安装 hadoop
[hadoop@wangmaster bigdata]$ tar -zxvf hadoop-2.7.3.tar.gz [hadoop@wangmaster bigdata]$ ll 总用量 386500 drwxr-xr-x. 9 hadoop hadoop 4096 8 月 18 2016 hadoop-2.7.3 -rwxrwxrwx. 1 hadoop hadoop 214092195 3 月 13 19:16 hadoop-2.7.3.tar.gz drwxrwxrwx. 8 hadoop hadoop 4096 3 月 13 00:14 jdk1.8 -rwxrwxrwx. 1 hadoop hadoop 181668321 3 月 22 23:31 jdk1.8.tar.gz
16、在 hadoop 目录下建立 tmp 目录,并将权限设定为 777
[hadoop@wangmaster bigdata]$ cd hadoop-2.7.3 [hadoop@wangmaster hadoop-2.7.3]$ mkdir tmp [hadoop@wangmaster hadoop-2.7.3]$ chmod 777 tmp [hadoop@wangmaster hadoop-2.7.3]$ mkdir dfs [hadoop@wangmaster hadoop-2.7.3]$ mkdir dfs/name [hadoop@wangmaster hadoop-2.7.3]$ mkdir dfs/data
二、 Hadoop 安装与配置
Hadoop 是大数据生态圈的基石,下面首先以 Hadoop 的安装与配置开始。
1、进入安装目录
[hadoop@wangmaster ~]$ cd /opt/bigdata/hadoop-2.7.3
2、环境配置
[hadoop@wangmaster hadoop-2.7.3]$ cd etc/hadoop [hadoop@wangmaster hadoop]$ vim yarn-env.sh # some Java parameters export JAVA_HOME=/opt/bigdata/jdk1.8
3、core 配置
[hadoop@wangmaster hadoop]$ vim core-site.xml <property> <name>hadoop.tmp.dir</name> <value>/opt/bigdata/hadoop-2.7.3/tmp</value> </property> <property> <name>fs.default.name</name> <value>hdfs://wangmaster:9000</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property>
4、hdfs 配置
[hadoop@wangmaster hadoop]$ vim hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property>
<name>dfs.namenode.name.dir</name> <value>/opt/bigdata/hadoop-2.7.3/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/bigdata/hadoop-2.7.3/dfs/data</value>
</property> <property> <name>dfs.web.ugi</name> <value>hdfs,hadoop</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
5、yarn 配置
[hadoop@wangmaster hadoop]$ vim yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>wangmaster</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>wangmaster:8088</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>wangmaster:8081</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>wangmaster:8082</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.web-proxy.address</name> <value>wangmaster:54315</value> </property> </configuration>
6、mapreduce 配置
[hadoop@wangmaster hadoop]$ vim mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tracker</name> <value>wangmaster:9001</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>wangmaster:10020</value> </property> </configuration>
7、slaves 配置(master、slave1 和 slave2 均作为 datanode)
[hadoop@wangmaster hadoop]$ vim slaves
wangmaster
wangslave1
wangslave2
master02
slave01
slave02
slave03
8、配置系统环境
[root@wangmaster bin]# vim /etc/profile 末尾添加这两句 export HADOOP_HOME=/opt/bigdata/hadoop-2.7.3 export PATH=$HADOOP_HOME/bin:$PATH
使配置生效:
[hadoop@wangmaster hadoop]$ source /etc/profile
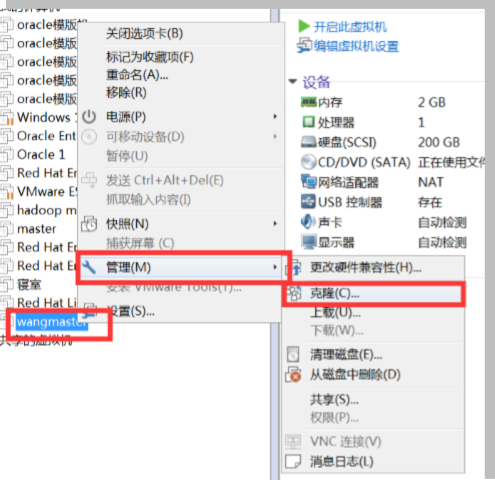
9、将虚拟机复制成 wangslave1 和 wangslave2 上。

把 CentOS 64 位 Minimal 重名为 wangmaster,克隆 wangmaster,建立 wangslave1 和 wangslave2 节点,克隆教程
首先给 wangmaster 关机
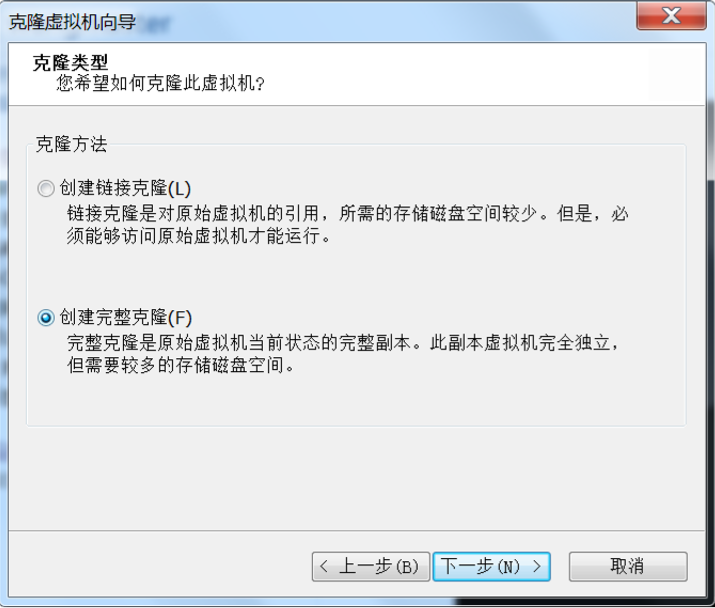
复制过后的虚拟机不能直接使用,需要进行如下操作:

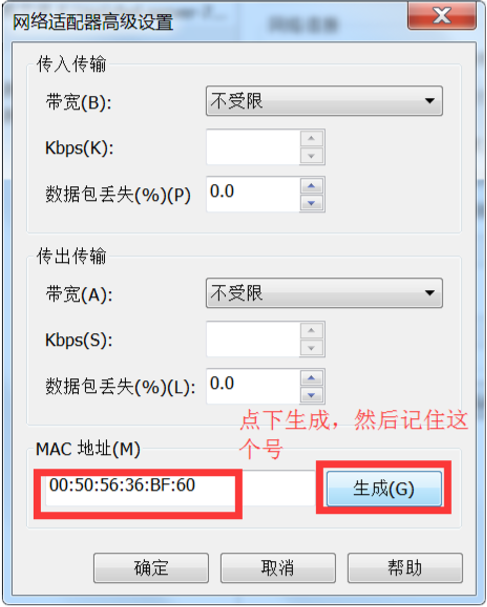
[root@wangmaster ~]# vim /etc/sysconfig/network-scripts/ifcfg-eno16777736 HWADDR=00:50:56:36:BF:60 //修改这个里 mac 地址,改成刚才生成的 TYPE="Ethernet" BOOTPROTO="static" DEFROUTE="yes" PEERDNS="yes" PEERROUTES="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_PEERDNS="yes" IPV6_PEERROUTES="yes" IPV6_FAILURE_FATAL="no" NAME="eno16777736" DEVICE="eno16777736" ONBOOT="yes" IPADDR=192.168.225.101 //这里改成 wangslave1 的 ip 192.168.225.101 NETMASK=255.255.255.0 GATEWAY=192.168.225.2 DNS1=114.114.114.114 DNS2=114.114.114.115 [root@wangmaster ~]# systemctl restart network.service //重启网络
然后修改主机名
[root@wangmaster ~]# hostnamectl set-hostname wangslave1 [root@wangmaster ~]# hostname wangslave1 [root@wangmaster ~]# exit 重新登录 测试 ping 自己 [root@wangslave1 ~]# ping wangslave1 PING wangslave1 (192.168.225.101) 56(84) bytes of data. 64 bytes from wangslave1 (192.168.225.101): icmp_seq=1 ttl=64 time=0.012ms
根据上面操作,克隆出 wangslave2
10、需要在 hadoop 用户下进行 master 和 slave 之间的免密
Master 给自己和 slave1,slave2 发证书
[hadoop@wangmaster ~]$ ssh-keygen [hadoop@wangmaster ~]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@wangslave1 [hadoop@wangmaster ~]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@wangslave2 [hadoop@wangmaster ~]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@wangmaster 这步完成后,正常情况下就可以无密码登录本机了,即 ssh localhost,无需输入密码。
然后 slave1 给 master 发证书
[hadoop@ wangslave1 ~]$ ssh-keygen [hadoop@ wangslave1 ~]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@wangmaste
然后 slave2 给 master 发证书 (略)
11、首次启动之前格式化 hdfs:
[hadoop@wangmaster ~]$ hdfs namenode -format
启动各组件
[hadoop@wangmaster ~]$ cd /opt/bigdata/hadoop-2.7.3/sbin
全部启动:
[hadoop@wangmaster sbin]$ ./start-all.sh 验证 [hadoop@wangmaster sbin]$ jps 1666 DataNode 2099 NodeManager 2377 Jps 1853 SecondaryNameNode 1998 ResourceManager 1567 NameNode [hadoop@wangslave1 ~]$ jps 1349 NodeManager 1452 Jps 1245 DataNode [hadoop@wangslave2 ~]$ jps 1907 Jps 1703 DataNode 1807 NodeManager
在浏览器里输入 http://192.168.225.100:50070 ,判断是否启动成功
12、全部停止
[hadoop@wangmaster sbin]$ ./stop-all.sh
三、实验
1、使用
[hadoop@wangmaster ~]$ hadoop fs -mkdir /wang [hadoop@wangmaster ~]$ cd /opt/bigdata/hadoop-2.7.3 [hadoop@wangmaster hadoop-2.7.3]$ hadoop fs -put LICENSE.txt /wang [hadoop@wangmaster ~]$ hadoop fs -ls /wang
2、实验,进行 wordcount 程序(可选)。一个统计文本单词个数的程序,它会统计放入文件夹内的文本的总共单词的出现个数
[hadoop@wangmaster hadoop-2.7.3]$ hadoop fs -ls /wang 查看 Found 1 items -rw-r--r-- 3 hadoop supergroup 84854 2017-04-09 07:34 /wang/LICENSE.txt [hadoop@wangmaster hadoop-2.7.3]$ cd /opt/bigdata/hadoop-2.7.3/share/hadoop/mapreduce [hadoop@wangmaster mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /wang /output 执行程序 [hadoop@wangmaster mapreduce]$ hadoop fs -ls /output 查看程序运行的输出文件 Found 2 items -rw-r--r-- 3 hadoop supergroup 0 2017-04-09 07:38 /output/_SUCCESS -rw-r--r-- 3 hadoop supergroup 22002 2017-04-09 07:38 /output/part-r-00000 [hadoop@wangmaster mapreduce]$ hadoop fs -cat /output/part-r-00000 查看结果