个人觉得akka提供的cluster工具中,sharding是最吸引人的。当我们需要把actor分布在不同的节点上时,Cluster sharding非常有用。我们可以使用actor的逻辑标识符与actor进行通信,而不用关心其物理位置。简单来说就是把actor的actorPath或actorRef进一步抽象,用一个字符串表示。
sharding可以表示为DDD领域中的聚合根,此时actor叫做“实体”。这些actor一般都具有持久化的状态。每个实体actor只运行在某个节点,我们可以在不知道actor位置的情况下,给对应的actor发送消息。当然了,这需要通过ShardRegion这个actor来发送,它知道如何路由消息。
介绍到这里,你是不是也有自己写一个sharding的冲动呢?不过我劝你不要这样做,虽然基于akka实现这个功能的核心功能很简单,但需要考虑很多场景,比如实体漂移。但还是要大胆想一想的,怎么屏蔽actor的位置呢?当然是创建一个proxy喽,这是akka的很多组件中经常出现的一种技术。proxy保存各个实体的具体位置(ActorRef或者ActorPath),然后通过proxy发送消息。其实sharding比较难的是实体要尽量分散,还要支持重新均衡,而且还要考虑实体actor漂移之后状态重建的功能。
在进一步分析源码之前,我有必要啰嗦几句akka中分片的相关概念。
首先我们要区分分片和分区的区别。其实我个人理解,分区是对一组数据的划分,即符合某类特征的数据进行聚合作为一个分区;而分片则是将数据分散到节点上的机制,即分片是尽可能的将数据“均匀”的分散到不同节点来达到均衡的目的,当然了还有其他好处。
akka分片是针对actor的,不是传统的对数据进行分片,可以理解成对计算的分片。每个actor都有一个实体ID,该ID在集群中唯一。akka需要提供从消息中提取实体ID的方法,和用于接收消息并计算actor所属分片ID的函数。
集群中分布的分片所在的区域成为分片区域,这些区域作为分片的proxy,参与分片的每个节点将每种类型的分片actor承载一个单独的分片区域。每个区域可以托管多个分片,分片区域内的所有实体由相同类型的actor表示。每个分片可以托管多个实体,实体根据ID的结果,分布在不同的分片上。分片协调器用于管理分片所在的位置,它是作为一个集群单例实现的。分片区域可以与分片协调器进行通信以定位分片,然后这个位置信息会被缓存。
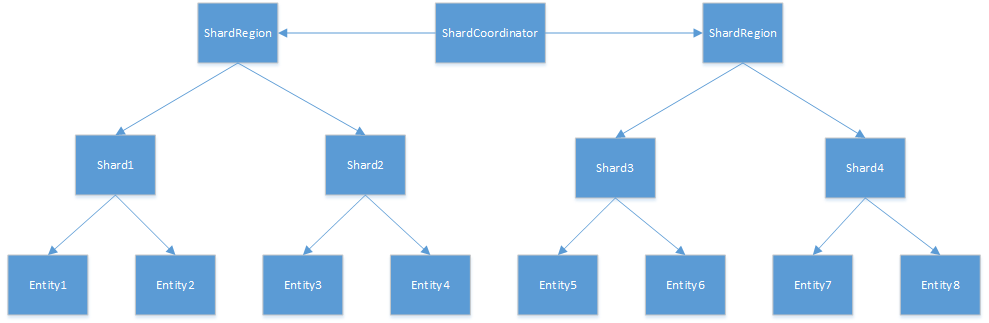
akka的分片还引入了钝化的机制。很显然如果在系统内长时间保持所有的actor是不合理的,而持久性的存在则可以允许我们对actor进行加载和卸载。如果在指定的时间内,actor没有收到消息,则我们可以钝化actor。简单来说就是给实体actor发送特定的消息关闭自己。如果某个消息ID对应的actor不存在,我们还可以重新加载这个actor。
好了,下面开始分析源码,上官网demo。
class Counter extends PersistentActor {
import ShardRegion.Passivate
context.setReceiveTimeout(120.seconds)
// self.path.name is the entity identifier (utf-8 URL-encoded)
override def persistenceId: String = "Counter-" + self.path.name
var count = 0
def updateState(event: CounterChanged): Unit =
count += event.delta
override def receiveRecover: Receive = {
case evt: CounterChanged ⇒ updateState(evt)
}
override def receiveCommand: Receive = {
case Increment ⇒ persist(CounterChanged(+1))(updateState)
case Decrement ⇒ persist(CounterChanged(-1))(updateState)
case Get(_) ⇒ sender() ! count
case ReceiveTimeout ⇒ context.parent ! Passivate(stopMessage = Stop)
case Stop ⇒ context.stop(self)
}
}
首先Counter是一个需要分散在各个节点的实体actor。很显然这是个PersistentActor。那如何创建一个对Counter的proxyActor呢?在akka中这叫做ShardRegion。
val counterRegion: ActorRef = ClusterSharding(system).start(
typeName = "Counter",
entityProps = Props[Counter],
settings = ClusterShardingSettings(system),
extractEntityId = extractEntityId,
extractShardId = extractShardId)
上面代码启动了一个ShardRegion,请注意start方法的最后两个参数。它分别定义了实体ID提取器和分片ID提取器。
val extractEntityId: ShardRegion.ExtractEntityId = {
case EntityEnvelope(id, payload) ⇒ (id.toString, payload)
case msg @ Get(id) ⇒ (id.toString, msg)
}
val numberOfShards = 100
val extractShardId: ShardRegion.ExtractShardId = {
case EntityEnvelope(id, _) ⇒ (id % numberOfShards).toString
case Get(id) ⇒ (id % numberOfShards).toString
case ShardRegion.StartEntity(id) ⇒
// StartEntity is used by remembering entities feature
(id.toLong % numberOfShards).toString
}
ShardRegion.ExtractEntityId、ShardRegion.ExtractShardId又是什么呢?
/** * Interface of the partial function used by the [[ShardRegion]] to * extract the entity id and the message to send to the entity from an * incoming message. The implementation is application specific. * If the partial function does not match the message will be * `unhandled`, i.e. posted as `Unhandled` messages on the event stream. * Note that the extracted message does not have to be the same as the incoming * message to support wrapping in message envelope that is unwrapped before * sending to the entity actor. */ type ExtractEntityId = PartialFunction[Msg, (EntityId, Msg)]
ExtractEntityId是一个片函数,它用来从消息中提取实体ID和消息。如果这个片函数无法处理消息,那么就会把这个未处理的消息发送给event stream。注意,输入的消息和输出的消息不一定是同类型的。
/** * Interface of the function used by the [[ShardRegion]] to * extract the shard id from an incoming message. * Only messages that passed the [[ExtractEntityId]] will be used * as input to this function. */ type ExtractShardId = Msg ⇒ ShardId
ExtractShardId是用来从消息中提取分片ID的,只有通过ExtractEntityId的消息才会发送给这个函数。其实在发送消息时,首先从消息中获取实体ID,然后通过实体ID计算分片ID的。
但有一定需要注意,那就是对于相同的实体ID计算出来的分片ID一定要相同,其实就是要保持一致,否则就会同时在多个地方启动相同的实体actor了。
其实一个好的分片算法非常重要。一致性HASH就是同时对消息ID和节点ID进行HASH,把消息路由给最邻近的节点。
下面开始分析start。
/**
* Scala API: Register a named entity type by defining the [[akka.actor.Props]] of the entity actor
* and functions to extract entity and shard identifier from messages. The [[ShardRegion]] actor
* for this type can later be retrieved with the [[shardRegion]] method.
*
* This method will start a [[ShardRegion]] in proxy mode in case if there is no match between the roles of
* the current cluster node and the role specified in [[ClusterShardingSettings]] passed to this method.
*
* Some settings can be configured as described in the `akka.cluster.sharding` section
* of the `reference.conf`.
*
* @return the actor ref of the [[ShardRegion]] that is to be responsible for the shard
*/
def start(
typeName: String,
entityProps: Props,
settings: ClusterShardingSettings,
extractEntityId: ShardRegion.ExtractEntityId,
extractShardId: ShardRegion.ExtractShardId,
allocationStrategy: ShardAllocationStrategy,
handOffStopMessage: Any): ActorRef = {
internalStart(typeName, _ ⇒ entityProps, settings, extractEntityId, extractShardId, allocationStrategy, handOffStopMessage)
}
start注册了一个命名的实体类型,也就是实体actor的Props,当然还包括从消息中提取实体ID、分片ID的函数。ShardRegion这个actor会被创建,单独负责这个类型(Props定义的类型),当然了还可以通过shardRegion方法查询获取。如果当前节点角色不属于我们定义的节点,则会创建一个ShardRegion的一个代理,即本地不会有分片actor创建,只是简单的把消息转发给其他节点上的ShardRegion。
@InternalApi private[akka] def internalStart(
typeName: String,
entityProps: String ⇒ Props,
settings: ClusterShardingSettings,
extractEntityId: ShardRegion.ExtractEntityId,
extractShardId: ShardRegion.ExtractShardId,
allocationStrategy: ShardAllocationStrategy,
handOffStopMessage: Any): ActorRef = {
if (settings.shouldHostShard(cluster)) {
implicit val timeout = system.settings.CreationTimeout
val startMsg = Start(typeName, entityProps, settings,
extractEntityId, extractShardId, allocationStrategy, handOffStopMessage)
val Started(shardRegion) = Await.result(guardian ? startMsg, timeout.duration)
regions.put(typeName, shardRegion)
shardRegion
} else {
log.debug("Starting Shard Region Proxy [{}] (no actors will be hosted on this node)...", typeName)
startProxy(
typeName,
settings.role,
dataCenter = None, // startProxy method must be used directly to start a proxy for another DC
extractEntityId,
extractShardId)
}
}
通过源码跟踪,我们找到了internalStart,这个函数只有一个if-else代码块,很显然我们刚开始需要创建ShardRegion,应该会走if代码块,也就是用ask模式给guardian发送Start消息,返回一个ActorRef,其实应该就是ShardRegion的actor的实例。并把这个ActorRef添加到了regions变量中。
private lazy val guardian: ActorRef = {
val guardianName: String =
system.settings.config.getString("akka.cluster.sharding.guardian-name")
val dispatcher = system.settings.config
.getString("akka.cluster.sharding.use-dispatcher") match {
case "" ⇒ Dispatchers.DefaultDispatcherId
case id ⇒ id
}
system.systemActorOf(Props[ClusterShardingGuardian].withDispatcher(dispatcher), guardianName)
}
guardian是一个ClusterShardingGuardian实例,它如何处理Start消息呢?
这个actor只处理两个类型的消息:Start和StartProxy。其实吧,这个就是对ShardRegion的一个监督者,这种用法之前分析过,也特意提出来了,读者自行理解吧。不过这里又叫Guardian,而不叫supervisor了,命名不统一啊,估计是多个开发者导致的。
val rep = replicator(settings)
val encName = URLEncoder.encode(typeName, ByteString.UTF_8)
val cName = coordinatorSingletonManagerName(encName)
val cPath = coordinatorPath(encName)
val shardRegion = context.child(encName).getOrElse {
if (context.child(cName).isEmpty) {
val coordinatorProps =
if (settings.stateStoreMode == ClusterShardingSettings.StateStoreModePersistence)
ShardCoordinator.props(typeName, settings, allocationStrategy)
else
ShardCoordinator.props(typeName, settings, allocationStrategy, rep, majorityMinCap)
val singletonProps = BackoffSupervisor.props(
childProps = coordinatorProps,
childName = "coordinator",
minBackoff = coordinatorFailureBackoff,
maxBackoff = coordinatorFailureBackoff * 5,
randomFactor = 0.2)
.withDeploy(Deploy.local)
val singletonSettings = settings.coordinatorSingletonSettings
.withSingletonName("singleton")
.withRole(role)
context.actorOf(
ClusterSingletonManager.props(singletonProps, terminationMessage = PoisonPill, singletonSettings)
.withDispatcher(context.props.dispatcher),
name = cName)
}
context.actorOf(
ShardRegion.props(
typeName = typeName,
entityProps = entityProps,
settings = settings,
coordinatorPath = cPath,
extractEntityId = extractEntityId,
extractShardId = extractShardId,
handOffStopMessage = handOffStopMessage,
replicator = rep,
majorityMinCap
)
.withDispatcher(context.props.dispatcher),
name = encName
)
}
sender() ! Started(shardRegion)
对Start消息的处理非常关键,所以这里把整个源码都贴出来了。很显然这里创建了三种actor:replicator、coordinator、shardRegion。replicator先略过,coordinator只需要记住它是通过ClusterSingletonManager创建的集群单例actor就行了。
StartProxy消息的处理不再分析,跟Start不同的是,它不会创建replicator、coordinator这些实例,只是简单的创建ShardRegion的代理actor。
/** * INTERNAL API * * This actor creates children entity actors on demand for the shards that it is told to be * responsible for. It delegates messages targeted to other shards to the responsible * `ShardRegion` actor on other nodes. * * @see [[ClusterSharding$ ClusterSharding extension]] */ private[akka] class ShardRegion( typeName: String, entityProps: Option[String ⇒ Props], dataCenter: Option[DataCenter], settings: ClusterShardingSettings, coordinatorPath: String, extractEntityId: ShardRegion.ExtractEntityId, extractShardId: ShardRegion.ExtractShardId, handOffStopMessage: Any, replicator: ActorRef, majorityMinCap: Int) extends Actor with ActorLogging
ShardRegion根据需要为分片创建对应的实体actor,并可以把消息路由给其他分片内的实体。既然消息都是发送给ShardRegion这个actor的,那么这个actor的receive定义就比较重要了。
def receive: Receive = {
case Terminated(ref) ⇒ receiveTerminated(ref)
case ShardInitialized(shardId) ⇒ initializeShard(shardId, sender())
case evt: ClusterDomainEvent ⇒ receiveClusterEvent(evt)
case state: CurrentClusterState ⇒ receiveClusterState(state)
case msg: CoordinatorMessage ⇒ receiveCoordinatorMessage(msg)
case cmd: ShardRegionCommand ⇒ receiveCommand(cmd)
case query: ShardRegionQuery ⇒ receiveQuery(query)
case msg: RestartShard ⇒ deliverMessage(msg, sender())
case msg: StartEntity ⇒ deliverStartEntity(msg, sender())
case msg if extractEntityId.isDefinedAt(msg) ⇒ deliverMessage(msg, sender())
case unknownMsg ⇒ log.warning("Message does not have an extractor defined in shard [{}] so it was ignored: {}", typeName, unknownMsg)
}
很显然,收到本分片能够处理的消息时,会去调用deliverMessage这个方法。
def deliverMessage(msg: Any, snd: ActorRef): Unit =
msg match {
case RestartShard(shardId) ⇒
regionByShard.get(shardId) match {
case Some(ref) ⇒
if (ref == self)
getShard(shardId)
case None ⇒
if (!shardBuffers.contains(shardId)) {
log.debug("Request shard [{}] home. Coordinator [{}]", shardId, coordinator)
coordinator.foreach(_ ! GetShardHome(shardId))
}
val buf = shardBuffers.getOrEmpty(shardId)
log.debug("Buffer message for shard [{}]. Total [{}] buffered messages.", shardId, buf.size + 1)
shardBuffers.append(shardId, msg, snd)
}
case _ ⇒
val shardId = extractShardId(msg)
regionByShard.get(shardId) match {
case Some(ref) if ref == self ⇒
getShard(shardId) match {
case Some(shard) ⇒
if (shardBuffers.contains(shardId)) {
// Since now messages to a shard is buffered then those messages must be in right order
bufferMessage(shardId, msg, snd)
deliverBufferedMessages(shardId, shard)
} else shard.tell(msg, snd)
case None ⇒ bufferMessage(shardId, msg, snd)
}
case Some(ref) ⇒
log.debug("Forwarding request for shard [{}] to [{}]", shardId, ref)
ref.tell(msg, snd)
case None if shardId == null || shardId == "" ⇒
log.warning("Shard must not be empty, dropping message [{}]", msg.getClass.getName)
context.system.deadLetters ! msg
case None ⇒
if (!shardBuffers.contains(shardId)) {
log.debug("Request shard [{}] home. Coordinator [{}]", shardId, coordinator)
coordinator.foreach(_ ! GetShardHome(shardId))
}
bufferMessage(shardId, msg, snd)
}
}
很显然,普通消息会走最后一个case代码块。它首先根据extractShardId解析出消息所属分片的ID。然后根据shardId从本地的regionByShard中查找对应的实体,如果找到且属于本地,就把消息转发给它。如果是远程的或不属于当前ShardRegion则会把消息转发给对应的Shard。如果当前ShardRegion没有找到对应的Shard,则会给coordinator发送GetShardHome消息来获取对应的Shard的ActorRef信息,不过这种情况我们先不分析。
regionByShard是用来做什么的呢?其实这是一个索引,它保存分片ID到分区区域的映射,因为分片区域负责管理分片。分片区域(ShardRegion)可以在本地也可以在远程或其他JVM。我们假设法消息给本地的分片区域,很显然刚开始时regionByShard是空的,而且shardBuffers也是空的,所以会给协调器发送GetShardHome消息,并调用bufferMessage消息。bufferMessage简单来说就是把shardId保存到shardBuffers并把消息做一个临时缓存。在Region创建之后再把消息发送过去。
ShardCoordinator分为PersistentShardCoordinator、DDataShardCoordinator,来看看他们是如何处理GetShardHome消息的。
case GetShardHome(shard) ⇒
if (!handleGetShardHome(shard)) {
// location not know, yet
val activeRegions = state.regions -- gracefulShutdownInProgress
if (activeRegions.nonEmpty) {
val getShardHomeSender = sender()
val regionFuture = allocationStrategy.allocateShard(getShardHomeSender, shard, activeRegions)
regionFuture.value match {
case Some(Success(region)) ⇒
continueGetShardHome(shard, region, getShardHomeSender)
case _ ⇒
// continue when future is completed
regionFuture.map { region ⇒
AllocateShardResult(shard, Some(region), getShardHomeSender)
}.recover {
case _ ⇒ AllocateShardResult(shard, None, getShardHomeSender)
}.pipeTo(self)
}
}
}
上面的代码表明,在ShardRegion给ShardCoordinator发送GetShardHome之前,ShardCoordinator就已经知道了Region的信息,那么什么时候知道的呢?我们似乎漏掉了什么。我们发现ShardRegion在收到集群的消息时(ClusterDomainEvent、CurrentClusterState)最终都会触发changeMembers方法,我们知道集群消息是在actor启动的时候就会收到的。
def changeMembers(newMembers: immutable.SortedSet[Member]): Unit = {
val before = membersByAge.headOption
val after = newMembers.headOption
membersByAge = newMembers
if (before != after) {
if (log.isDebugEnabled)
log.debug("Coordinator moved from [{}] to [{}]", before.map(_.address).getOrElse(""), after.map(_.address).getOrElse(""))
coordinator = None
register()
}
}
changeMembers中会调用register方法。
def register(): Unit = {
coordinatorSelection.foreach(_ ! registrationMessage)
if (shardBuffers.nonEmpty && retryCount >= 5) coordinatorSelection match {
case Some(actorSelection) ⇒
val coordinatorMessage =
if (cluster.state.unreachable(membersByAge.head)) s"Coordinator [${membersByAge.head}] is unreachable."
else s"Coordinator [${membersByAge.head}] is reachable."
log.warning(
"Trying to register to coordinator at [{}], but no acknowledgement. Total [{}] buffered messages. [{}]",
actorSelection, shardBuffers.totalSize, coordinatorMessage
)
case None ⇒ log.warning(
"No coordinator found to register. Probably, no seed-nodes configured and manual cluster join not performed? Total [{}] buffered messages.",
shardBuffers.totalSize)
}
}
register其实就是给coordinatorSelection发送registrationMessage消息。
def registrationMessage: Any =
if (entityProps.isDefined) Register(self) else RegisterProxy(self)
registrationMessage只是区分了Register还是RegisterProxy,其实就是区分是注册Region还是RegionProxy。
case Register(region) ⇒
if (isMember(region)) {
log.debug("ShardRegion registered: [{}]", region)
aliveRegions += region
if (state.regions.contains(region)) {
region ! RegisterAck(self)
allocateShardHomesForRememberEntities()
} else {
gracefulShutdownInProgress -= region
update(ShardRegionRegistered(region)) { evt ⇒
state = state.updated(evt)
context.watch(region)
region ! RegisterAck(self)
allocateShardHomesForRememberEntities()
}
}
} else {
log.debug("ShardRegion {} was not registered since the coordinator currently does not know about a node of that region", region)
}
上面是ShardCoordinator收到Register时的处理逻辑,其实就是保存了region的相关信息,并发送了RegisterAck消息。但请注意allocateShardHomesForRememberEntities,这个机制后面会再深入分析,因为它影响了分片的性能。
case RegisterAck(coord) ⇒
context.watch(coord)
coordinator = Some(coord)
requestShardBufferHomes()
ShardRegion收到RegisterAck消息如何处理的呢,其实就是保存了coord的ActorRef,并把缓存的消息发出去了。
我们回到GetShardHome处理的代码块,其实它最终调用了allocationStrategy.allocateShard(getShardHomeSender, shard, activeRegions)创建了Shard。
/**
* Invoked when the location of a new shard is to be decided.
* @param requester actor reference to the [[ShardRegion]] that requested the location of the
* shard, can be returned if preference should be given to the node where the shard was first accessed
* @param shardId the id of the shard to allocate
* @param currentShardAllocations all actor refs to `ShardRegion` and their current allocated shards,
* in the order they were allocated
* @return a `Future` of the actor ref of the [[ShardRegion]] that is to be responsible for the shard, must be one of
* the references included in the `currentShardAllocations` parameter
*/
def allocateShard(requester: ActorRef, shardId: ShardId,
currentShardAllocations: Map[ActorRef, immutable.IndexedSeq[ShardId]]): Future[ActorRef]
allocateShard是ShardAllocationStrategy这个trait的一个方法。通过上下文,我们知道ShardAllocationStrategy是LeastShardAllocationStrategy的一个实例。
/**
* The default implementation of [[ShardCoordinator.LeastShardAllocationStrategy]]
* allocates new shards to the `ShardRegion` with least number of previously allocated shards.
* It picks shards for rebalancing handoff from the `ShardRegion` with most number of previously allocated shards.
* They will then be allocated to the `ShardRegion` with least number of previously allocated shards,
* i.e. new members in the cluster. There is a configurable threshold of how large the difference
* must be to begin the rebalancing. The number of ongoing rebalancing processes can be limited.
*/
@SerialVersionUID(1L)
class LeastShardAllocationStrategy(rebalanceThreshold: Int, maxSimultaneousRebalance: Int)
extends ShardAllocationStrategy with Serializable
override def allocateShard(requester: ActorRef, shardId: ShardId,
currentShardAllocations: Map[ActorRef, immutable.IndexedSeq[ShardId]]): Future[ActorRef] = {
val (regionWithLeastShards, _) = currentShardAllocations.minBy { case (_, v) ⇒ v.size }
Future.successful(regionWithLeastShards)
}
LeastShardAllocationStrategy是如何实现allocateShard的呢?其实就是从currentShardAllocations选择保持shard最少的actorRef,那么currentShardAllocations传入的时候值是什么呢?其实就是当前活跃的ShardRegion。很显然我们目前只有一个ShardRegion,根据源码来分析,GetShardHome消息的代码块中会调用continueGetShardHome
def continueGetShardHome(shard: ShardId, region: ActorRef, getShardHomeSender: ActorRef): Unit =
if (rebalanceInProgress.contains(shard)) {
deferGetShardHomeRequest(shard, getShardHomeSender)
} else {
state.shards.get(shard) match {
case Some(ref) ⇒ getShardHomeSender ! ShardHome(shard, ref)
case None ⇒
if (state.regions.contains(region) && !gracefulShutdownInProgress.contains(region)) {
update(ShardHomeAllocated(shard, region)) { evt ⇒
state = state.updated(evt)
log.debug("Shard [{}] allocated at [{}]", evt.shard, evt.region)
sendHostShardMsg(evt.shard, evt.region)
getShardHomeSender ! ShardHome(evt.shard, evt.region)
}
} else
log.debug(
"Allocated region {} for shard [{}] is not (any longer) one of the registered regions: {}",
region, shard, state)
}
}
continueGetShardHome其实就是从state.shards中获取region的实例,如果找到则返回,如果没有找到则创建ShardHomeAllocated消息,然后调用sendHostShardMsg
def sendHostShardMsg(shard: ShardId, region: ActorRef): Unit = {
region ! HostShard(shard)
val cancel = context.system.scheduler.scheduleOnce(shardStartTimeout, self, ResendShardHost(shard, region))
unAckedHostShards = unAckedHostShards.updated(shard, cancel)
}
sendHostShardMsg就是给ShardRegion发送HostShard消息。后续功能不再分析。
那么读者会问了,为啥ShardRegion还需要通过shardId去问协调器ShardRegion的位置呢?你猜啊。哈哈,因为发给本地ShardRegion的消息,并不一定属于它啊,有可能是其他节点的ShardRegion呢?为啥对于同一个shardId可能存在多个节点上呢?你再猜,哈哈。想想本来就该这样啊,我们之定义了实体ID、分片ID,并没有定义分片区域ID啊,也就是说,分片可以属于任意一个分片区域,而分片区域可以跨节点分布。所以这也就是默认的LeastShardAllocationStrategy中allocateShard的意义:从所有节点上找出管理分片最少的分片区域。也就是说,一个消息发送给哪个分片、再有该分片发送给哪个实体是确定的,但是这个分片在哪个节点就不固定了。这也就是所谓的分片漂移,某个分片到达指定阈值,可能会迁移到其他的分片区域内,当迁移时,本地分片内的实体actor都会被stop掉,等分片迁移成功后,收到某个实体第一个消息时重新创建实体actor。
至此,akka的分片机制分析完毕,当然还有很多细节没有分析。但简单来说就是,一个消息先发送给本地的ShardRegion实例,本地实例会计算消息的sharId,通过这个ID找出对应的Shard(因为Shard可能不在本节点或漂移到了其他节点),当然这是通过协调器找到的。找到shardId对应的Shard之后,就会把消息发送给Shard。
不过我们好像忘了分析Shard了,好尴尬,哈哈。那么就看看。
def receiveCommand: Receive = {
case Terminated(ref) ⇒ receiveTerminated(ref)
case msg: CoordinatorMessage ⇒ receiveCoordinatorMessage(msg)
case msg: ShardCommand ⇒ receiveShardCommand(msg)
case msg: ShardRegion.StartEntity ⇒ receiveStartEntity(msg)
case msg: ShardRegion.StartEntityAck ⇒ receiveStartEntityAck(msg)
case msg: ShardRegionCommand ⇒ receiveShardRegionCommand(msg)
case msg: ShardQuery ⇒ receiveShardQuery(msg)
case msg if extractEntityId.isDefinedAt(msg) ⇒ deliverMessage(msg, sender())
}
很显然,它收到消息之后,还是调用deliverMessage。
def deliverMessage(msg: Any, snd: ActorRef): Unit = {
val (id, payload) = extractEntityId(msg)
if (id == null || id == "") {
log.warning("Id must not be empty, dropping message [{}]", msg.getClass.getName)
context.system.deadLetters ! msg
} else if (payload.isInstanceOf[ShardRegion.StartEntity]) {
// in case it was wrapped, used in Typed
receiveStartEntity(payload.asInstanceOf[ShardRegion.StartEntity])
} else {
messageBuffers.contains(id) match {
case false ⇒ deliverTo(id, msg, payload, snd)
case true if messageBuffers.totalSize >= bufferSize ⇒
log.debug("Buffer is full, dropping message for entity [{}]", id)
context.system.deadLetters ! msg
case true ⇒
log.debug("Message for entity [{}] buffered", id)
messageBuffers.append(id, msg, snd)
}
}
}
deliverMessage源码看似很多,但重点就在最后一个else代码块。messageBuffers刚开始是没有这个实体ID的,所以会调用deliverTo。
def deliverTo(id: EntityId, msg: Any, payload: Msg, snd: ActorRef): Unit = {
val name = URLEncoder.encode(id, "utf-8")
context.child(name) match {
case Some(actor) ⇒ actor.tell(payload, snd)
case None ⇒ getEntity(id).tell(payload, snd)
}
}
deliverTo会在当前的分片中查找对应的实体actor,如果找到就把消息发送给它,如果没找到就通过getEntity创建之后在发送给他。
def getEntity(id: EntityId): ActorRef = {
val name = URLEncoder.encode(id, "utf-8")
context.child(name).getOrElse {
log.debug("Starting entity [{}] in shard [{}]", id, shardId)
val a = context.watch(context.actorOf(entityProps(id), name))
idByRef = idByRef.updated(a, id)
refById = refById.updated(id, a)
state = state.copy(state.entities + id)
a
}
}
getEntity比较简单,就是通过name查找子actor,如果没找到就用entityProps创建对应的actor,然后就是更新相关的状态。
本文介绍了分片的基本机制,但分片的功能远比这个要复杂一点,我们后面会再进一步的分析和研读源码。