在C++/Java等语言中,都有传值(pass-by-value)、传引用(pass-by-reference)的概念,在C++中,这个概念区分的很清楚,通过&即可。本人相对而言也是对C++更加熟悉一些,最近需要用到python,在python究竟是传值还是传引用上踩了一下坑。
其实,我发现,python与JavaScript在这个机制上是非常像的,对于JavaScript而言,如果是原子类型(数值、字符串、布尔型)则是传值,如果是对象,则传引用。
而python中,或许我们不该讨论python是否是传值还是传引用,而是应该讨论某个对象是可变的还是不可变的,实际上,python总是传值的,对内置的基本类型而言,dict、list是可变对象,str、int、tuple、float是不可变对象。
简短的回答是,Python总是按值传递,但每个Python变量实际上都是指向某个对象的指针,因此有时它看起来像是传递引用。
在Python中,每个对象都是可变的或不可变的。例如,列表,字典,模块是可变的,并且int,字符串和元组是不可变的。
每个Python变量视为指向对象的指针。
将变量传递给函数时,函数中的变量(指针)始终是传入的变量(指针)的副本。因此,如果为内部变量分配新内容,则所做的只是更改局部变量指向不同的对象。
这不会改变(变异)变量指向的原始对象,也不会使外部变量指向新对象。 此时,外部变量仍指向原始对象,但内部变量指向新对象。
来自Stack Overflow上的一个回答
上面这段话,可能你看了之后还不是很理解他的意思,要理解这些解释的含义,我们有必要搞明白python(对可变对象和不可变对象的)赋值过程中是如何分配内存地址的。
下面,我们可以通过一些简单的例子来理解
a=1
b=1
print(id(a))
print(id(b))
x=[1,2,3]
y=[1,2,3]
print(id(x))
print(id(y))
(如果你不知道python中的id函数是什么,点这里)
输出如下:(这里的id的输出不同的机器上输出不一样,但是你的输出也会有相同的特征,如下面我们看到的a与b的输出必然是相同的,而x,y的输出不相同)
140737211568960
140737211568960
2873979515464
2874037513544
可以发现,对于可变对象list来说,即便列表内容一模一样,python也会给它们分配新的不同的地址。
然而,对于不可变对象int来说,内存里只有一个1。即便再定义一个变量c=1,也是指向内存中同一个1。换句话说,不可变对象1的地址是共享的。
接下来让我们看看在函数中调用可变对象和不可变对象,并修改他们的值,会是一个什么情况。
对于不可变对象int,我们来看看最简单的情况:
a=1
print(id(a))
def x(a):
print(id(a))
b=a
print(id(b))
x(a)
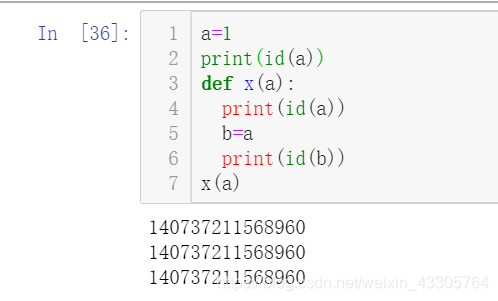
这看起来就是一个引用传递,函数外的a、函数里的a和b都指向了同一个地址。
但我们再来看一个极端情况:
a=1
print(id(a))
def x():
b=1
print(id(b))
x()
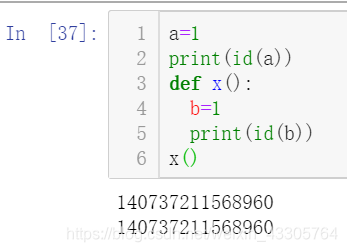
可以看到,函数外定义的a和函数内定义的b没有任何关系,但它们指向同一个地址!
下面来看看传递可变对象list的情况:
l=[1,2,3]
print(id(l))
def a(x):
print(id(x))
x.pop()
print(x)
print(id(x))
x=x+[3]
print(x)
print(id(x))
a(l)
print(id(l))
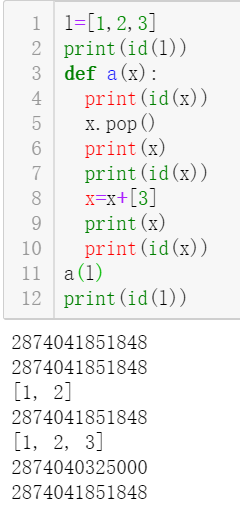
可以看到,当我们把函数外的列表L传递给函数后,x的地址和L是一样的,这看起来就是一个引用传递,没问题。
继续往下,我们调用x本身的方法pop后,x变成[1,2],并且x的地址没变,这也没什么问题。
但是当我们给x赋值以后,x的地址就变了。
也就是说,只要创建一个新的可变对象,python就会分配一个新的地址。就算我们创建的新可变对象和已存在的旧可变对象完全一样,python依旧会分配一个新的地址。
而pop并不是创建新的可变对象,pop是对已有的可变对象进行修改。
所以可以总结为:
在python中,不可变对象是共享的,创建可变对象永远是分配新地址
对于上图的x,当你执行到x=x+[3]这一句时,实际上,是在函数内部创建了一个局部变量,名字为x,x是指向x+[3]的指针,因为x+[3]这个表达式是的结果是一个list,也就是可变对象,python会为其分配一个新的地址,新创建的x覆盖了函数内部的前面的x,因此,在print(id(x))时,显示的就是新创建的x的地址,而在函数外面,l依然是指向原来的l,所以外部的l并没有改变。函数内部的“赋值”实际上只是改变了内部的局部变量x的指向,但是没有改变x指向的数据的值! 现在你再去看前面Stack Overflow的那个回答,我相信应该是可以看懂了。
也就是说,当你对一个可变对象在函数内部直接赋值的时候,需要小心这个问题。 (这里划重点!!!可以看前面的list例子和后面的list例子,作为对比。)如果意识不到这一点,程序本身并不会报错,但未必会按照你的意思来执行,这时找bug往往更加困难。
当然,如果是在函数外部直接赋值,那么就不必考虑这个问题。
那么,如果我们需要在函数内部希望能够改变这个可变对象,应该怎么做呢?
l=[1,2,3]
print(id(l))
def a(x):
print(id(x))
x.pop()
print(x)
print(id(x))
x[:]=x[:]+[3]
print(x)
print(id(x))
a(l)
print(id(l))

还是上面那个list的例子,只是把x=x+[3] 这种直接对x进行赋值,改变成了 x[:] =x[:]+3 这样的,对x所在整个范围进行赋值。可以看到,这时,并没有创建新的对象,整个过程中,地址都没有变。
另一种选择则是通过global关键字将变量设为全局变量,这样,在使用函数内部的变量时,python知道这个变量是用的外面的全局变量,也就是获取了其“引用”。
写到这里,对这篇文章的标题而言,本应结束了。
实际上,我当时是在使用pandas时遇到的一个问题,当时我误认为是python的传值机制引起,后来知道,是由pandas本身的传“副本”或传“视图”而引起的,对于pandas新手而言,很容易遇到的一个警告就是:SettingwithCopy。
引起这个问题的一个主要原因就是由于我们使用了“链式索引”。下面这篇文章是我当时找到的一个讲解,觉得讲的还是不错的,放在下面。Pandas SettingwithCopy 警告解决方案,供需要的人参考。