Spark SQL学习笔记
窗口函数
窗口函数的定义引用一个大佬的定义: a window function calculates a return value for every input row of a table based on a group of rows。窗口函数与与其他函数的区别:
普通函数: 作用于每一条记录,计算出一个新列(记录数不变);
聚合函数: 作用于一组记录(全部数据按照某种方式分为多组),计算出一个聚合值(记录数变小);
窗口函数: 作用于每一条记录,逐条记录去指定多条记录来计算一个值(记录数不变)。
窗口函数语法结构: 函数名(参数)OVER(PARTITION BY 子句 ORDER BY 子句 ROWS/RANGE子句)
函数名:
OVER: 关键字,说明这是窗口函数,不是普通的聚合函数;
子句
PARTITION BY: 分组字段
ORDER BY: 排序字段
ROWS/RANG窗口子句: 用于控制窗口的尺寸边界,有两种(ROW,RANGE)
ROW: 物理窗口,数据筛选基于排序后的index
RANGE: 逻辑窗口,数据筛选基于值
主要有以下三种窗口函数
ranking functions
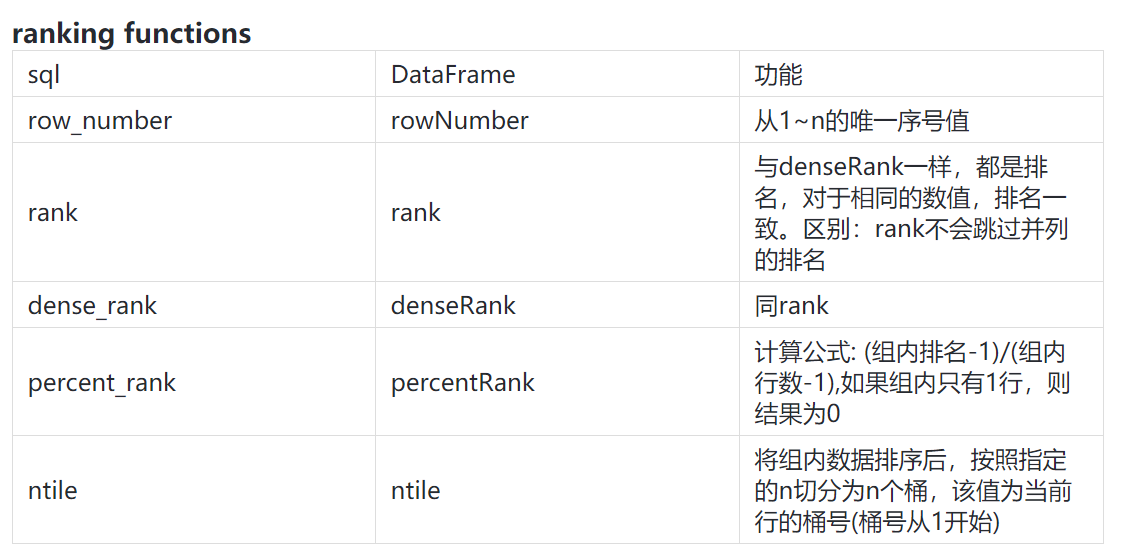
analytic functions

aggregate functions
窗口函数一般用来
1、我们需要统计用户的总使用时长(累加历史)
2、前台展现页面需要对多个维度进行查询,如:产品、地区等等
3、需要展现的表格头如: 产品、2015-04、2015-05、2015-06
over()开窗函数的默认关键字
开窗的窗口范围:
over(order by sroce range between 5 preceding and 5 following):窗口范围为当前行数据幅度减5加5后的范围内的。
over(order by sroce rows between 5 preceding and 5 following):窗口范围为当前行前后各移动5行。
与over()函数结合的函数的介绍无敌的肉包
在使用聚合函数后,会将多行变成一行,而开窗函数是将一行变成多行;
并且在使用聚合函数后,如果要显示其他的列必须将列加入到group by中,而使用开窗函数后,可以不使用group by,直接将所有信息显示出来。
开窗函数适用于在每一行的最后一列添加聚合函数的结果。
开窗函数作用
为每条数据显示聚合信息.(聚合函数() over())
为每条数据提供分组的聚合函数结果(聚合函数() over(partition by 字段) as 别名)
--按照字段分组,分组后进行计算
与排名函数一起使用(row number() over(order by 字段) as 别名)
常用分析函数:(最常用的应该是1.2.3 的排序)
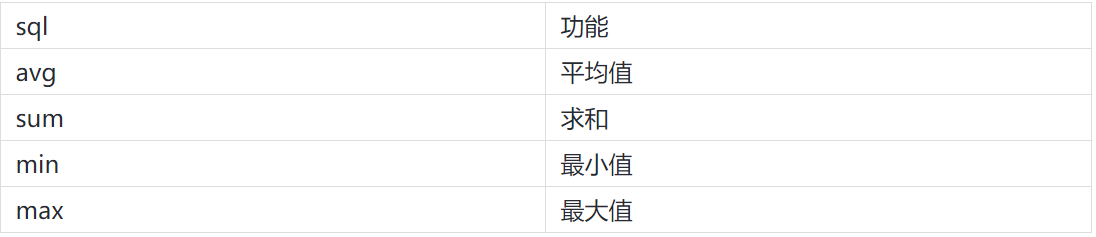
聚合函数
row_number() over(partition by ... order by ...)是根据表中字段进行分组,然后根据表中的字段排序;其实就是根据其排序顺序,给组中的每条记录添
加一个序号;且每组的序号都是从1开始,可利用它的这个特性进行分组取top-n
rank() over(partition by ... order by ...)
dense_rank() over(partition by ... order by ...)
count() over(partition by ... order by ...)
max() over(partition by ... order by ...)
min() over(partition by ... order by ...)
sum() over(partition by ... order by ...)
avg() over(partition by ... order by ...)
first_value() over(partition by ... order by ...)
last_value() over(partition by ... order by ...)
比较函数
lag() over(partition by ... order by ...) #比较函数
lead() over(partition by ... order by ...)
lag 和lead 可以获取结果集中,按一定排序所排列的当前行的上下相邻若干offset 的某个行的某个列(不用结果集的自关联);
lag ,lead 分别是向前,向后;
lag 和lead 有三个参数,第一个参数是列名,第二个参数是偏移的offset,第三个参数是超出记录窗口时的默认值
SQL实现
query = """
SELECT
ROW_NUMBER() OVER (ORDER BY time) AS row,
train_id,
station,
time,
LEAD(time,1) OVER (ORDER BY time) AS time_next
FROM schedule
"""
spark.sql(query).show()
# Give the number of the bad row as an integer
bad_row = 7
# Provide the missing clause, SQL keywords in upper case
clause = 'PARTITION BY train_id'
点表示法dataframe实现
聚合函数
# Give the identical result in each command
spark.sql('SELECT train_id, MIN(time) AS start FROM schedule GROUP BY train_id').show()
df.groupBy('train_id').agg({'time':'min'}).withColumnRenamed('min(time)', 'start').show()
# Print the second column of the result
spark.sql('SELECT train_id, MIN(time), MAX(time) FROM schedule GROUP BY train_id').show()
result = df.groupBy('train_id').agg({'time':'min', 'time':'max'})
result.show()
print(result.columns[1])
Using Python version 3.5.2 (default, Nov 23 2017 16:37:01)
SparkSession available as 'spark'.
<script.py> output:
+--------+-----+
|train_id|start|
+--------+-----+
| 217|6:06a|
| 324|7:59a|
+--------+-----+
+--------+-----+
|train_id|start|
+--------+-----+
| 217|6:06a|
| 324|7:59a|
+--------+-----+
+--------+---------+---------+
|train_id|min(time)|max(time)|
+--------+---------+---------+
| 217| 6:06a| 6:59a|
| 324| 7:59a| 9:05a|
+--------+---------+---------+
+--------+---------+
|train_id|max(time)|
+--------+---------+
| 217| 6:59a|
| 324| 9:05a|
+--------+---------+
max(time)
sql语句的形式
# Write a SQL query giving a result identical to dot_df
query = "SELECT train_id, MIN(time) AS start, MAX(time) AS end FROM schedule GROUP BY train_id"
sql_df = spark.sql(query)
sql_df.show()
<script.py> output:
+--------+-----+-----+
|train_id|start| end|
+--------+-----+-----+
| 217|6:06a|6:59a|
| 324|7:59a|9:05a|
+--------+-----+-----+
# Obtain the identical result using dot notation
dot_df = df.withColumn('time_next', lead('time', 1)
.over(Window.partitionBy('train_id')
.orderBy('time')))
SQL查询
# Create a SQL query to obtain an identical result to dot_df
query = """
SELECT *,
(UNIX_TIMESTAMP(LEAD(time, 1) OVER (PARTITION BY train_id ORDER BY time),'H:m')
- UNIX_TIMESTAMP(time, 'H:m'))/60 AS diff_min
FROM schedule
"""
sql_df = spark.sql(query)
sql_df.show()
1、UNIX_TIMESTAMP() :若无参数调用,则返回一个 Unix timestamp ('1970-01-01 00:00:00' GMT 之后的秒数) 作为无符号整数,得到当前时间戳
2、UNIX_TIMESTAMP(date) :若用date 来调用 UNIX_TIMESTAMP(),它会将参数值以'1970-01-01 00:00:00' GMT后的秒数的形式返回。date 可以是一个 DATE 字符串、一个 DATETIME字符串、一个 TIMESTAMP或一个当地时间的YYMMDD 或YYYMMDD格式的数字。
<script.py> output:
+--------+-------------+-----+--------+
|train_id| station| time|diff_min|
+--------+-------------+-----+--------+
| 217| Gilroy|6:06a| 9.0|
| 217| San Martin|6:15a| 6.0|
| 217| Morgan Hill|6:21a| 15.0|
| 217| Blossom Hill|6:36a| 6.0|
| 217| Capitol|6:42a| 8.0|
| 217| Tamien|6:50a| 9.0|
| 217| San Jose|6:59a| null|
| 324|San Francisco|7:59a| 4.0|
| 324| 22nd Street|8:03a| 13.0|
| 324| Millbrae|8:16a| 8.0|
| 324| Hillsdale|8:24a| 7.0|
| 324| Redwood City|8:31a| 6.0|
| 324| Palo Alto|8:37a| 28.0|
| 324| San Jose|9:05a| null|
+--------+-------------+-----+--------+
## Loading natural language text
加载文本时数据
```r
# Load the dataframe
df = spark.read.load('sherlock_sentences.parquet')
# Filter and show the first 5 rows
df.where('id > 70').show(5, truncate=False)
<script.py> output:
+--------------------------------------------------------+---+
|clause |id |
+--------------------------------------------------------+---+
|i answered |71 |
|indeed i should have thought a little more |72 |
|just a trifle more i fancy watson |73 |
|and in practice again i observe |74 |
|you did not tell me that you intended to go into harness|75 |
+--------------------------------------------------------+---+
only showing top 5 rows
# Split the clause column into a column called words
split_df = clauses_df.select(split('clause', ' ').alias('words')) #alias就是名字的缩写
split_df.show(5, truncate=False)
# Explode the words column into a column called word
exploded_df = split_df.select(explode('words').alias('word')) #explode方法可以从规定的Array或者Map中使用每一个元素创建一列
exploded_df.show(10)
# Count the resulting number of rows in exploded_df
print("
Number of rows: ", exploded_df.count())
First 5 rows of clauses_df:
+----------------------------------------+---+
|clause |id |
+----------------------------------------+---+
|title |0 |
|the adventures of sherlock holmes author|1 |
|sir arthur conan doyle release date |2 |
|march 1999 |3 |
|ebook 1661 |4 |
+----------------------------------------+---+
<script.py> output:
+-----------------------------------------------+
|words |
+-----------------------------------------------+
|[title] |
|[the, adventures, of, sherlock, holmes, author]|
|[sir, arthur, conan, doyle, release, date] |
|[march, 1999] |
|[ebook, 1661] |
+-----------------------------------------------+
only showing top 5 rows
+----------+
| word|
+----------+
| title|
| the|
|adventures|
| of|
| sherlock|
| holmes|
| author|
| sir|
| arthur|
| conan|
+----------+
only showing top 10 rows
Number of rows: 1279
sql滑动窗口
LAG
# Word for each row, previous two and subsequent two words
query = """
SELECT
part,
LAG(word, 2) OVER(PARTITION BY part ORDER BY id) AS w1,
LAG(word, 1) OVER(PARTITION BY part ORDER BY id) AS w2,
word AS w3,
LEAD(word, 1) OVER(PARTITION BY part ORDER BY id) AS w4,
LEAD(word, 2) OVER(PARTITION BY part ORDER BY id) AS w5
FROM text
"""
spark.sql(query).where("part = 12").show(10)
Table 1: First 10 rows of chapter 12
+-----+---------+----+--------------------+
| id| word|part| title|
+-----+---------+----+--------------------+
|95166| xii| 12|Sherlock Chapter XII|
|95167| the| 12|Sherlock Chapter XII|
|95168|adventure| 12|Sherlock Chapter XII|
|95169| of| 12|Sherlock Chapter XII|
|95170| the| 12|Sherlock Chapter XII|
|95171| copper| 12|Sherlock Chapter XII|
|95172| beeches| 12|Sherlock Chapter XII|
|95173| to| 12|Sherlock Chapter XII|
|95174| the| 12|Sherlock Chapter XII|
|95175| man| 12|Sherlock Chapter XII|
+-----+---------+----+--------------------+
only showing top 10 rows
Table 2: First 10 rows of the desired result
+----+---------+---------+---------+---------+---------+
|part| w1| w2| w3| w4| w5|
+----+---------+---------+---------+---------+---------+
| 12| null| null| xii| the|adventure|
| 12| null| xii| the|adventure| of|
| 12| xii| the|adventure| of| the|
| 12| the|adventure| of| the| copper|
| 12|adventure| of| the| copper| beeches|
| 12| of| the| copper| beeches| to|
| 12| the| copper| beeches| to| the|
| 12| copper| beeches| to| the| man|
| 12| beeches| to| the| man| who|
| 12| to| the| man| who| loves|
+----+---------+---------+---------+---------+---------+
<script.py> output:
+----+---------+---------+---------+---------+---------+
|part| w1| w2| w3| w4| w5|
+----+---------+---------+---------+---------+---------+
| 12| null| null| xii| the|adventure|
| 12| null| xii| the|adventure| of|
| 12| xii| the|adventure| of| the|
| 12| the|adventure| of| the| copper|
| 12|adventure| of| the| copper| beeches|
| 12| of| the| copper| beeches| to|
| 12| the| copper| beeches| to| the|
| 12| copper| beeches| to| the| man|
| 12| beeches| to| the| man| who|
| 12| to| the| man| who| loves|
+----+---------+---------+---------+---------+---------+
only showing top 10 rows
Repartition
通过创建更过或更少的分区将数据随机的打散,让数据在不同分区之间相对均匀。这个操作经常是通过网络进行数打散。
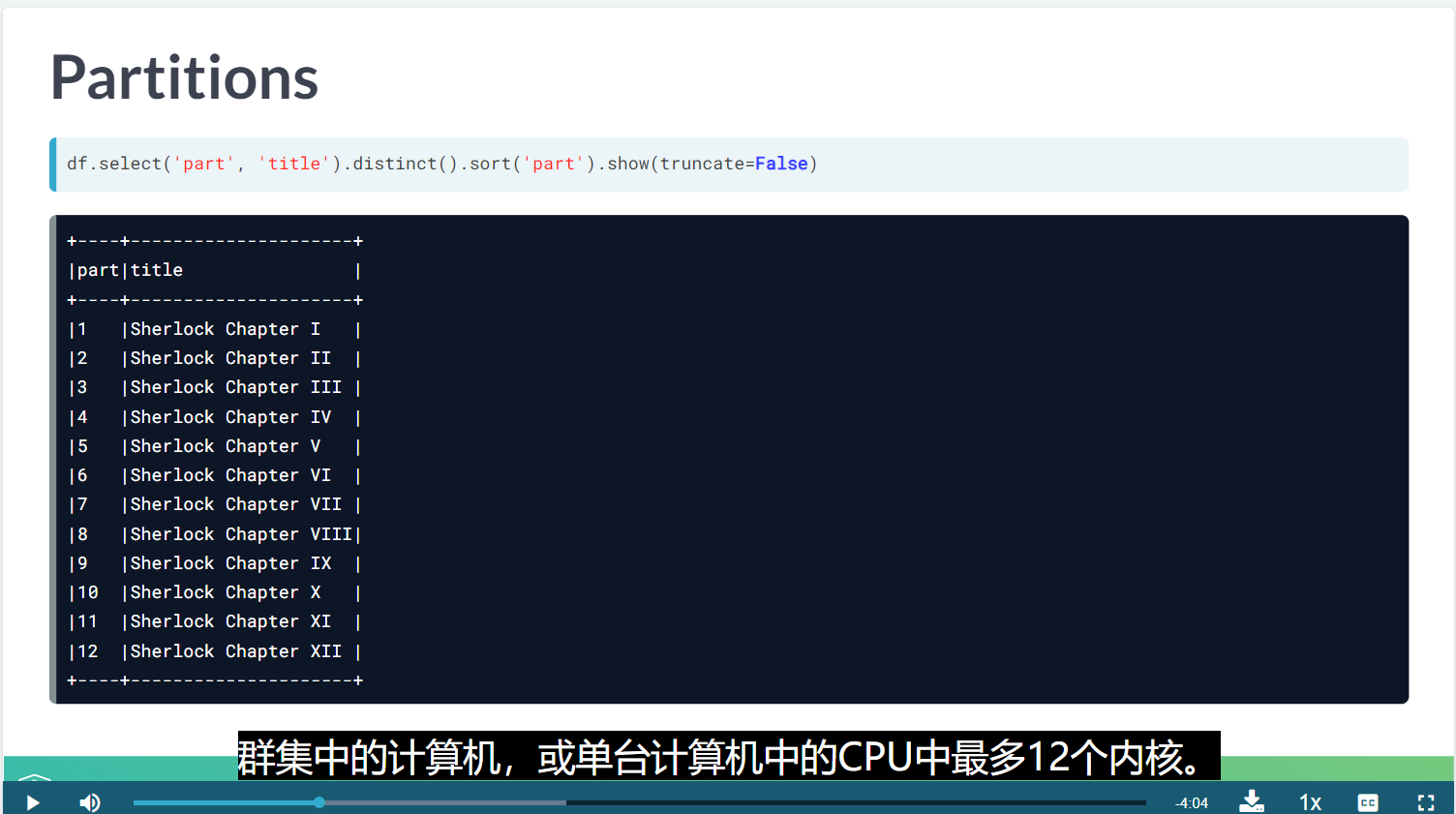
# Repartition text_df into 12 partitions on 'chapter' column
repart_df = text_df.repartition(12, 'chapter')
# Prove that repart_df has 12 partitions
repart_df.rdd.getNumPartitions()
First 5 rows of text_df
+---+-------+------------------+
| id| word| chapter|
+---+-------+------------------+
|305|scandal|Sherlock Chapter I|
|306| in|Sherlock Chapter I|
|307|bohemia|Sherlock Chapter I|
|308| i|Sherlock Chapter I|
|309| to|Sherlock Chapter I|
+---+-------+------------------+
only showing top 5 rows
Table 1
+---------------------+
|chapter |
+---------------------+
|Sherlock Chapter I |
|Sherlock Chapter II |
|Sherlock Chapter III |
|Sherlock Chapter IV |
|Sherlock Chapter IX |
|Sherlock Chapter V |
|Sherlock Chapter VI |
|Sherlock Chapter VII |
|Sherlock Chapter VIII|
|Sherlock Chapter X |
|Sherlock Chapter XI |
|Sherlock Chapter XII |
+---------------------+
分类变量排序
分组排序
# Find the top 10 sequences of five words
query = """
SELECT w1, w2, w3, w4, w5, COUNT(*) AS count FROM (
SELECT word AS w1,
LEAD(word,1) OVER(PARTITION BY part ORDER BY id ) AS w2,
LEAD(word,2) OVER(PARTITION BY part ORDER BY id ) AS w3,
LEAD(word,3) OVER(PARTITION BY part ORDER BY id ) AS w4,
LEAD(word,4) OVER(PARTITION BY part ORDER BY id ) AS w5
FROM text
)
GROUP BY w1, w2, w3, w4, w5
ORDER BY count DESC
LIMIT 10
"""
df = spark.sql(query)
df.show()
<script.py> output:
+-----+---------+------+-------+------+-----+
| w1| w2| w3| w4| w5|count|
+-----+---------+------+-------+------+-----+
| in| the| case| of| the| 4|
| i| have| no| doubt| that| 3|
| what| do| you| make| of| 3|
| the| church| of| st|monica| 3|
| the| man| who|entered| was| 3|
|dying|reference| to| a| rat| 3|
| i| am|afraid| that| i| 3|
| i| think| that| it| is| 3|
| in| his| chair| with| his| 3|
| i| rang| the| bell| and| 3|
+-----+---------+------+-------+------+-----+
distinct
# Unique 5-tuples sorted in descending order
query = """
SELECT DISTINCT w1, w2, w3, w4, w5 FROM (
SELECT word AS w1,
LEAD(word,1) OVER(PARTITION BY part ORDER BY id ) AS w2,
LEAD(word,2) OVER(PARTITION BY part ORDER BY id ) AS w3,
LEAD(word,3) OVER(PARTITION BY part ORDER BY id ) AS w4,
LEAD(word,4) OVER(PARTITION BY part ORDER BY id ) AS w5
FROM text
)
ORDER BY w1 DESC, w2 DESC, w3 DESC, w4 DESC, w5 DESC
LIMIT 10
"""
df = spark.sql(query)
df.show()
<script.py> output:
+----------+------+---------+------+-----+
| w1| w2| w3| w4| w5|
+----------+------+---------+------+-----+
| zealand| stock| paying| 4| 1/4|
| youwill| see| your| pal|again|
| youwill| do| come| come| what|
| youth|though| comely| to| look|
| youth| in| an|ulster| who|
| youth|either| it| s| hard|
| youth| asked| sherlock|holmes| his|
|yourselves| that| my| hair| is|
|yourselves|behind| those| then| when|
| yourself| your|household| and| the|
+----------+------+---------+------+-----+
# Most frequent 3-tuple per chapter
query = """
SELECT chapter, w1, w2, w3, count FROM
(
SELECT
chapter,
ROW_NUMBER() OVER (PARTITION BY chapter ORDER BY count DESC) AS row,
w1, w2, w3, count
FROM ( %s )
)
WHERE row = 1
ORDER BY chapter ASC
""" % subquery
spark.sql(query).show()
<script.py> output:
+-------+-------+--------+-------+-----+
|chapter| w1| w2| w3|count|
+-------+-------+--------+-------+-----+
| 1| up| to| the| 6|
| 2| one| of| the| 8|
| 3| mr| hosmer| angel| 13|
| 4| that| he| was| 8|
| 5| that| he| was| 6|
| 6|neville| st| clair| 15|
| 7| that| i| am| 7|
| 8| dr|grimesby|roylott| 8|
| 9| that| it| was| 7|
| 10| lord| st| simon| 28|
| 11| i| think| that| 8|
| 12| the| copper|beeches| 10|
+-------+-------+--------+-------+-----+
caching
缓存数据表
缓存将数据保存在内存中,这样不用每次重新获取数据,提升效率
但是缓存的过程本身很慢~
缓存之后再加载就会很快
Spark 中一个很重要的能力是将数据持久化(或称为缓存),在多个操作间都可以访问这些持久化的数据。当持久化一个 RDD 时,每个节点的其它分区都可以使用 RDD 在内存中进行计算,在该数据上的其他 action 操作将直接使用内存中的数据。这样会让以后的 action 操作计算速度加快(通常运行速度会加速 10 倍)。缓存是迭代算法和快速的交互式使用的重要工具。
RDD 可以使用 persist() 方法或 cache() 方法进行持久化。数据将会在第一次 action 操作时进行计算,并缓存在节点的内存中。Spark 的缓存具有容错机制,如果一个缓存的 RDD 的某个分区丢失了,Spark 将按照原来的计算过程,自动重新计算并进行缓存。
在 shuffle 操作中(例如 reduceByKey),即便是用户没有调用 persist 方法,Spark 也会自动缓存部分中间数据。这么做的目的是,在 shuffle 的过程中某个节点运行失败时,不需要重新计算所有的输入数据。如果用户想多次使用某个 RDD,强烈推荐在该 RDD 上调用 persist 方法。董可伦
# Unpersists df1 and df2 and initializes a timer
prep(df1, df2)
# Cache df1
df1.cache()
# Run actions on both dataframes
run(df1, "df1_1st")
run(df1, "df1_2nd")
run(df2, "df2_1st")
run(df2, "df2_2nd", elapsed=True)
# Prove df1 is cached
print(df1.is_cached)
<script.py> output:
df1_1st : 3.1s
df1_2nd : 0.1s
df2_1st : 0.3s
df2_2nd : 0.1s
Overall elapsed : 3.9
True
persist()
RDD分布式抽象数据集
_useDisk:使用磁盘
_useMemory:使用内存
_useOffHeap:使用堆外存,这是Java虚拟机里面的概念,堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
_deserialized:使用反序列化,其逆过程序列化(Serialization)是java提供的一种机制,将对象表示成一连串的字节;而反序列化就表示将字节恢复为对象的过程。序列化是对象永久化的一种机制,可以将对象及其属性保存起来,并能在反序列化后直接恢复这个对象
_replication:副本数,默认是一个
Persist df2 using memory and disk storage level
df2.persist(storageLevel=pyspark.StorageLevel.MEMORY_AND_DISK)
spark.catalog.isCached
一个api
# List the tables
print("Tables:
", spark.catalog.listTables())
# Cache table1 and Confirm that it is cached
spark.catalog.cacheTable('table1')
print("table1 is cached: ", spark.catalog.isCached('table1'))
# Uncache table1 and confirm that it is uncached
spark.catalog.uncacheTable('table1')
print("table1 is cached: ", spark.catalog.isCached('table1'))
Logging
学习一下记录日志以及防止cpu隐形丢失
查看日志信息的几种方式
DEBUG详细信息,常用于调试
INFO程序正常运行过程中产生的一些信息
WARNING警告用户,虽然程序还在正常工作,但有可能发生错误
ERROR由于更严重的问题,程序已不能执行一些功能了
CRITICAL严重错误,程序已不能继续运行
# Uncomment the 5 statements that do NOT trigger text_df
logging.debug("text_df columns: %s", text_df.columns)
logging.info("table1 is cached: %s", spark.catalog.isCached(tableName="table1"))
# logging.warning("The first row of text_df: %s", text_df.first())
logging.error("Selected columns: %s", text_df.select("id", "word"))
logging.info("Tables: %s", spark.sql("SHOW tables").collect())
logging.debug("First row: %s", spark.sql("SELECT * FROM table1 LIMIT 1"))
# logging.debug("Count: %s", spark.sql("SELECT COUNT(*) AS count FROM table1").collect())
# Log selected columns of text_df as error message
logging.error("Selected columns: %s", text_df.select("id", "word"))
explain
查询数据的执行计划
自定义函数
# Returns true if the value is a nonempty vector
nonempty_udf = udf(lambda x:
True if (x and hasattr(x, "toArray") and x.numNonzeros())
else False, BooleanType())
# Returns first element of the array as string
s_udf = udf(lambda x: str(x[0]) if (x and type(x) is list and len(x) > 0)
else '', StringType())
感觉这里稍微熟悉一些了
用户自定义函数
# Returns true if the value is a nonempty vector
nonempty_udf = udf(lambda x:
True if (x and hasattr(x, "toArray") and x.numNonzeros())
else False, BooleanType())
# Returns first element of the array as string
s_udf = udf(lambda x: str(x[0]) if (x and type(x) is list and len(x) > 0)
else '', StringType())
array_contains
判断某个字符串是否包含某个元素

# Transform df using model
result = model.transform(df.withColumnRenamed('in', 'words'))
.withColumnRenamed('words', 'in')
.withColumnRenamed('vec', 'invec')
result.drop('sentence').show(3, False)
# Add a column based on the out column called outvec
result = model.transform(result.withColumnRenamed('out', 'words'))
.withColumnRenamed('words', 'out')
.withColumnRenamed('vec', 'outvec')
result.select('invec', 'outvec').show(3,False)
spark可以部署一些线上模型
哦哦,spark也试一门语言,有包,哈哈,目前是这样理解的
# Split the examples into train and test, use 80/20 split
df_trainset, df_testset = df_examples.randomSplit((0.80, 0.20), 42)
# Print the number of training examples
print("Number training: ", df_trainset.count())
# Print the number of test examples
print("Number test: ", df_testset.count())
<script.py> output:
Number training: 2091
Number test: 495
逻辑回归的例子
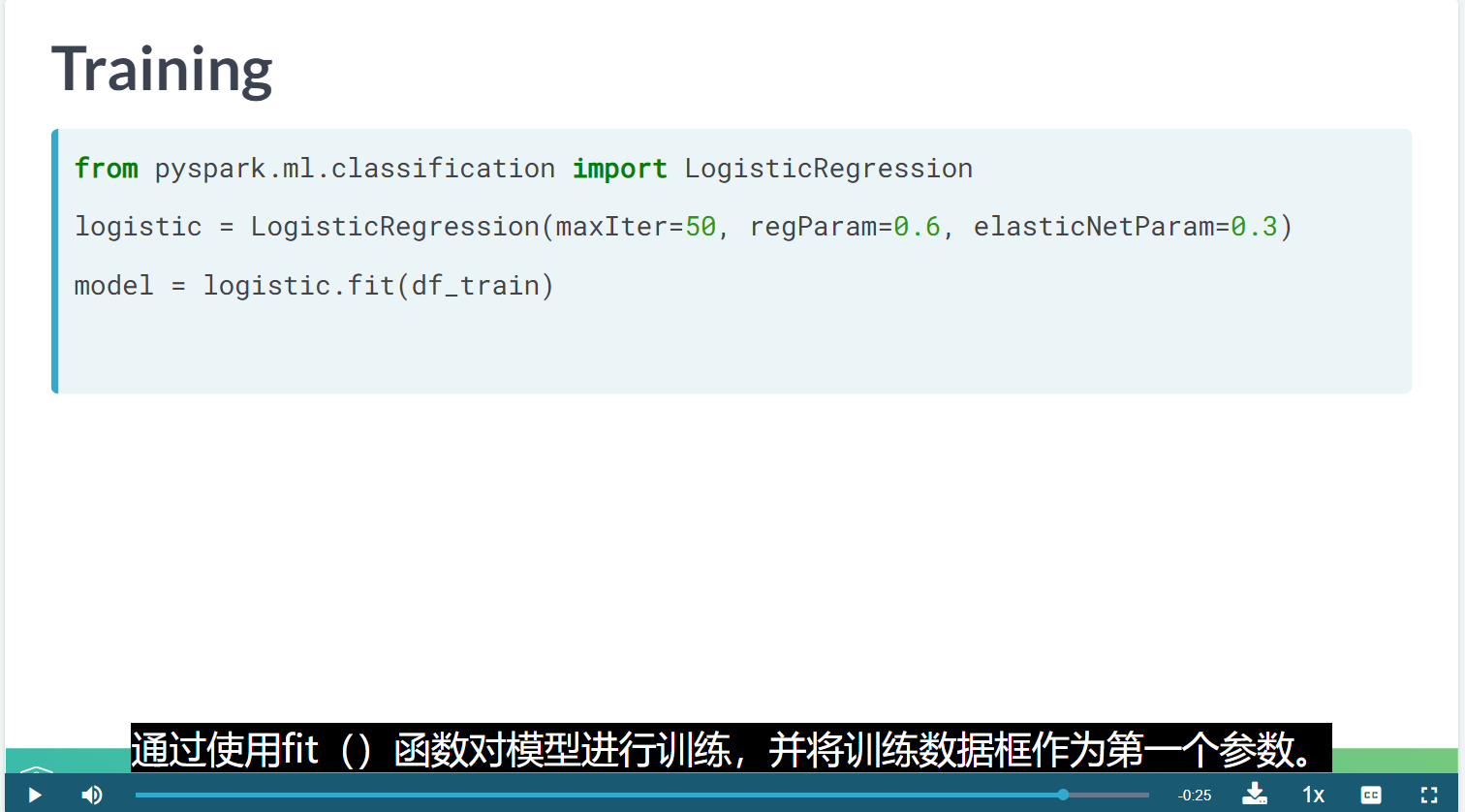
# Import the logistic regression classifier
from pyspark.ml.classification import LogisticRegression
# Instantiate logistic setting elasticnet to 0.0
logistic = LogisticRegression(maxIter=100, regParam=0.4, elasticNetParam=0.0)
# Train the logistic classifer on the trainset
df_fitted = logistic.fit(df_trainset)
# Print the number of training iterations
print("Training iterations: ", df_fitted.summary.totalIterations)
<script.py> output:
Training iterations: 21
# Score the model on test data
testSummary = df_fitted.evaluate(df_testset)
# Print the AUC metric
print("
test AUC: %.3f" % testSummary.areaUnderROC)
入门先到这里啦,看的云里雾里的哈哈~
我觉得可以先熟悉pyspark里面的ml和mlib
