线性支持向量机与软间隔最大化
我前面的博客内容讲了感知机,讲了线性可分问题下的支持向量机。二者却有相似之处,但是都是处理样本在可分条件下的情况。即将样本表示在特征空间中,一定能找到一个超平面来将样本正确分为两类,没有一个误分类的。
但是很多时候我们需要处理的问题并不都是这样,很多时候样本在特征空间中表示,却没有完全可以将样本正确分类的超平面,即这样的超平面不存在。这时我们的学习策略需要调整,即软间隔最大化。
什么是软间隔最大化?
我的理解是,我们仍然需要求出一个超平面来尽量将样本分为两类,但是不强求完全分类,可以容忍很少一部分特殊的样本不符合yi(w.x+b)-1>=0。即这部分样本在空间中表示的点可以不被正确分类过着到超平面的函数距离小于1。(函数距离在我之前关于支持向量机的博客中提到,如有不了解的,可以看看。)学习策略是这样的,如何用数学公式抽象表达呢?
为了实现上面的想法,我们为每个样本的函数距离松弛变量使其函数距离加上松弛变量大于等于1。
此时我们的约束问题较之前数据集可分情况发生了变化。
变成如下约束问题:
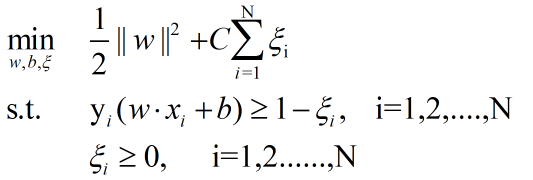
这松弛变量是大于等于0的,因为我们在之前说过,松弛变量的作用就是让样本的函数距离加上它大于等于1,所以松弛变量只应该大于等于。
两个约束条件,我想都应该理解了吧。但是最小化函数好像也发生了变化。这里最小化函数在之前的基础上加上后面加上了一个松弛变量的代价。这个原因是,我们总不能让松弛变量无限大吧。我们的目的只是为了让函数距离小于1的样本加上松弛变量大于等于1,大于一的松弛变量都应该等于0。
那么C是什么呢?C其实就是惩罚系数,就是说如果我们现在想要的模型不追求泛化能力,我们呢只要现在的训练集尽可能多的被模型划分,那么我们就让这个惩罚系数非常非常大,此时模型的学习策略就是尽量的划分数据集,让松弛因子尽量小。但如果C很小呢?说明此时我们考虑的是最大间隔尽量大一些。一定程度上忽略误分类点。这里C>0.
对于上述约束问题,我们仍然可以用拉格朗日对偶函数解决问题,我在上一篇博客刚好讲了这个知识点,不了解的可以看看。
那么拉个朗日函数为:
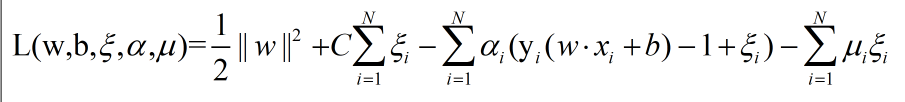
就按拉格朗日函数的形式套过来就是
我们还是按部就班,这个拉个朗日函数其约束条件与优化函数都为凸函数,且其则其对偶问题的解与原始问题得解应该是一样的,这是一个定理。
那么我们可以求解其对偶问题的解
首先先求w,b和第三个变量它们关于的极小值,对其求导得:
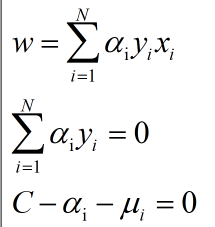
然后后面就是将上式代入原始,再求阿尔法,代会就可求得w和b。

关于上述的关系,结合函数关于变量先后取极大值,极小值的特点可以分析出来,这里就不多说了。