组件:
容器:管理某类对象的集合。
迭代器:用来在一个对象集合内遍历元素。
算法:处理集合内的元素。
容器
- 序列式容器:顾名思义。array,vector,deque,list 和 forward_list(c++11)。
- 关联式容器:已排序集合。元素位置取决于value(或者key -- 如果元素是个key--value 对)和给定的某个排序准则。set,multiset,map 和 multimap。
- 无序容器:无序集合,每个元素的位置无关紧要,唯一重要的是某特定元素是否位于此集合内。值或安插顺序都不能影响元素的位置,元素的位置有可能在容器生命中被改变。unordered_set, unordered_multiset, unordered_map 和 unordered_multimap。 unordered容器在TR1中引入。
序列式容器常被时限为array或者linked list 。
关联式容器常被实现为binary tree。
无序容器常被实现为hash table。
序列式容器
重点提一下 TR1中新加入的array。
一个array对象乃是在某个固定大小的array内管理元素。因此,不可以改变元素个数,只能改变元素值。必须在建立时就指明其大小。array允许随机访问,只要有索引。包含在头<array>中
eg:
//array container of 5 string elements array<string,5> col = {"hello","world"}; array<string,5> col2; //默认情况下被default构造函数初始化,对基础类型而言,初值不明确
list:list不提供随机访问,比如要访问第10个元素,就必须走完前9个。这比vector和deque提供的摊提式常量时间,效率差太多。但优势是快速插入和删除,只需改变链接即可。
std::forward_list 是支持从容器中的任何位置快速插入和移除元素的容器。不支持快速随机访问。它实现为单链表,且实质上与其在 C 中实现相比无任何开销。与 std::list 相比,此容器提在不需要双向迭代时提供更有效地利用空间的存储。
在链表内或跨数个链表添加、移除和移动元素,不会非法化当前指代链表中其他元素的迭代器。然而,在从链表移除元素(通过 erase_after )时,指代对应元素的迭代器或引用会被非法化。
std::forward_list 满足容器 (Container) (除了 operator== 的复杂度始终为线性和 size 函数)、具分配器容器(AllocatorAwareContainer) 和顺序容器 (SequenceContainer) 的要求。
参考链接:为什么forward_list不支持push_back , 如何使用std::forward_list 单链表
关联式容器
- set : 元素依据value自动排序,每个元素只能出现一次,不许重复
- multiset:和set的唯一差别就是可以重复
- map:每个 元素都是键值对,key是排序准则的基准。每个key只准出现一次
- multimap:和map的唯一差别就是,元素可以重复,即key可以重复
实际上所有这些关联式容器通常都由二叉树实现。multimap也可以用作字典。
无序容器
对于无序容器而言,某次插入操作可能对其他元素位置造成影响(rehashing,删除操作不会造成rehashing)。我们唯一关心的是,某个特定元素是否位于容器内。可以理解为无序容器是个袋子。
无序容器常以hash table实现出来,内部结构是一个“由linked list组成”的array。通过某个hash函数计算,确定元素落于这个array的位置。Hash函数运算的目标是:让每个元素的落点(位置)有助于快速访问任何一个元素。
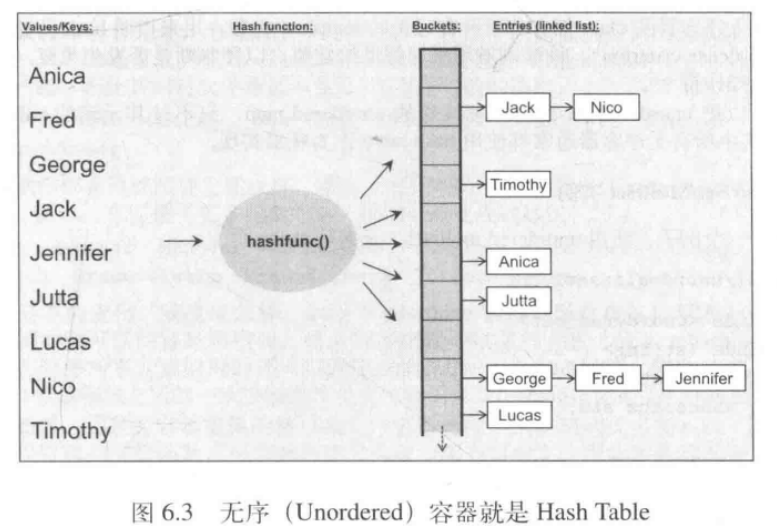
但前提是hash函数本身必须足够快。但这个完美的hash函数不一定存在或者被找到,抑或是由于它造成array耗费巨额内存而显得不切实际,因此,退而求其次的hash函数可能让多个元素落在同一个位置上。所以,设计上就让array的元素再被放进一个linked list中,如此一来array的每个位置就得以存在一个以上的元素。
无序容器优点是,查找一个带有特定值的元素,其速度肯能快过关联式容器。事实上无序容器提供的是摊提式常量复杂度,前提是有一个良好的hash函数。然而这并不简单,你可能需要提供许多内存作为bucket。
stl定义了下面这些无序容器:
- unordered set 无需元素集合。元素不允许重复
- unordered map 键值对。每个key唯一。
- unordered multiset 允许元素重复
- unordered multimap 允许key重复,可以作为字典
容器适配器
Container Adapter是预定义的容器,提供的是一定限度的接口,用于处理特殊需求。这些容器都是根据基本容器定义实现的。
- stack 顾名思义。对元素采用LIFO管理策略。
- Queue FIFO策略。
- Priority queue 期内元素拥有优先权。优先权奶水给予程序员提供的排序准则而定义的。效果类似于这样一个缓冲区:下一元素永远是容器中优先权最高的元素。
迭代器
自c++11起,可以使用range-based for循环处理所有元素。
- Operator* 返回当前位置上的元素值,
- Operator ++ 迭代器前进到下一元素
- operator == 和 != 判断两个迭代器是否相同
- Operator = 对迭代器赋值
任何容器定义两种迭代器类型:
1 container::iterator 以“读/写”模式遍历元素
2 container::const_iterator 以“只读”模式遍历元素
cbegin() 和 cend()
c++11起,关键字auto可以代替迭代器的精确类型 ,其可以使程序比较精简,或者当容器类型变化时,程序整体仍保持较佳的强壮性。 缺点是迭代器丧失常量性,可能引发“计划外赋值”风险。因为 auto pos = coll.begin();会使pos成为一个非常量迭代器。那么,cbegin() 和 cend() 就是返回了一个类型为const_iterator的对象。
为了避免循环中大量的拷贝行为,每个元素的copy构造函数和析构函数都被调用,可以使用const reference
std::vector<int> vec; for(const auto& elem : vec){ cout << elem ; }
迭代器种类
根据能力不同,迭代器被划分为5种不同的类别。STL预先定义好的所有容器,其迭代器均属于以下三种分类:
- 前向迭代器 只能够以累加操作符向前迭代。class forward_list的迭代器就是属于此类,unordered_set , unordered_multiset , unordered_map 和 unordered_multimap都至少是此类。
- 双向迭代器 递增递减都行。list,set,map, multimap,multiset提供的迭代器都属此类
- 随机访问迭代器 不但具备双向迭代的所有属性,还具备随机访问的能力。它们提供了迭代器算术运算的必要操作符。vector,dequeue,array和string提供的迭代器都属于此类。
除此之外,stl还定义了两个类别:
- 输入型迭代器 向前迭代时能够读取/处理 value. Input stream迭代器就是这样的例子。
- 输出型迭代器 向前迭代时能够涂写value。Inserter和output stream迭代器都是此类。
迭代器之适配器
Insert Iterator(安插型迭代器)
它可以使算法以安插的方式而非覆写的方式运作。使用它可以解决算法的“目标空间不足”的问题。是的,他会促使目标区间的大小按需要成长。
#include <algorithm> #include<iterator> #include<list> #include<vector> #include<deque> #include<set> #include<iostream> using namespace std; int main() { list<int> coll1 = { 1,2,3,4,5,6,7,8,9 }; //复制coll1的元素到coll2,by appending them vector<int> coll2; copy(coll1.cbegin(),coll1.cend(), //source back_inserter(coll2)); //destination //复制coll1的元素到coll3中,by inserting them at the front,反转了元素顺序 deque<int> coll3; copy(coll1.cbegin(),coll1.cend(), //source front_inserter(coll3)); //destination //只有inserter工作于关联式集合 set<int> coll4; copy(coll1.cbegin(),coll1.cend(), inserter(coll4,coll4.begin())); }
此例运用了三种预定义的insert iterator:
1 Back inserter(安插于容器最末端):其内部调用push_back(),在容器末端插入元素(即追加动作)。只有在提供push_back() 的容器中back inserter才能派上用场。在c++标准库中的此类容器有vector,deque,和string。
2 Front inserter(安插于容器最前端) 其内部元素调用push_front(),将元素安插与容器的最前端。c++中可用的容器为deque,list和 forward_list。
3 General inserter :一般性的inserter,作用是在“初始化时接受之第二实参”所指位置的前方插入元素。内部调用 成员函数insert(),并以新值和新位置作为实参传入。所有STL容器都提供insert()成员函数,因为,这是唯一可用于关联式容器身上的一种预定义inserter。

Stream Iterator(串流迭代器)
#include <algorithm> #include<iterator> #include<string> #include<vector> #include<iostream> using namespace std; int main() { vector<string> coll; //read all words from the standard input //-source :all strings until end-of-file(or err) //-detination :coll(inserting) copy(istream_iterator<string>(cin), //start of source istream_iterator<string>(), //end of source back_inserter(coll)); //destination sort(coll.begin(),coll.end()); //print all elements without duplicates //-source :coll //-destination: 标准输出 unique_copy(coll.begin(),coll.end(), //source ostream_iterator<string> (cout," ")); //destination }
具体介绍查阅stream 迭代器
反向迭代器
move 迭代器
更易型算法
移除(Removing)元素
算法remove() 自某个区间删除元素。然而如果用它来删除容器所有的元素,行为肯定会令人吃惊。例如:
int main() { list<int> coll; for (int i = 0; i < 7; ++i) { coll.push_front(i); coll.push_back(i); } //print all elements of the collection cout << "pre: "; copy(coll.cbegin(), coll.cend(), ostream_iterator<int>(cout, " ")); cout << endl; //remove all elements with value 3 remove(coll.begin(),coll.end(),3); cout << "post: "; copy(coll.cbegin(),coll.cend(), ostream_iterator<int>(cout," ")); cout << endl; }
输出为:
pre: 6 5 4 3 2 1 0 0 1 2 3 4 5 6
post: 6 5 4 2 1 0 0 1 2 4 5 6 5 6
显然,这不符合预期。
事实上,remove() 函数返回了新的终点。可以利用该终点获得新区间,缩减后的容器大小,或者获得被删除元素的个数。下面是改进版本:
int main() { list<int> coll; for (int i = 0; i < 7; ++i) { coll.push_front(i); coll.push_back(i); } //print all elements of the collection cout << "pre: "; copy(coll.cbegin(), coll.cend(), ostream_iterator<int>(cout, " ")); cout << endl; //remove all elements with value 3 list<int>::iterator end = remove(coll.begin(),coll.end(),3); copy(coll.begin(), end, ostream_iterator<int>(cout, " ")); cout << endl; //print numbers of removed elements cout << "member of remove elements:" << distance(end, coll.end()) << endl; coll.erase(end,coll.end()); cout << "post: "; copy(coll.cbegin(),coll.cend(), ostream_iterator<int>(cout," ")); cout << endl; }
pre: 6 5 4 3 2 1 0 0 1 2 3 4 5 6
6 5 4 2 1 0 0 1 2 4 5 6
member of remove elements:2
post: 6 5 4 2 1 0 0 1 2 4 5 6
end正是“被修改集合”经过元素移除动作后的新的逻辑终点。
当然,你可以单一一句完成上述过程:
coll.erase(remove(coll.begin(),coll.end(),3),coll.end());
为何算法不自己调用erase()呢,这个问题正好点出STL为获取弹性而付出的代价。通过“以迭代器为接口”,STL将数据结构和算法分离开。迭代器不过是“容器内部某一位置的抽象”。一般而言,迭代器对自己所属的容器一无所知,任何“以迭代器访问容器”的算法,都不得通过迭代器调用容器类所提供的任何成员函数。
更易Associative(关联式)和Unordered(无序)容器
更易型算法(指的是那些会移除(remove),重拍(reorder),修改(modify)元素的算法)若用于关联式容器或者无序容器,会出问题。关联式容器和无序容器不能被当作操作目标,原因很简单:如果更易维护型算法用于关联式和无序容器上,会改变某些位置上的值,进而破坏容器本身对次序的维护。为了避免累及内部次序,关联式容器和无序容器的所有迭代器均被声明为指向常量的value或key。
那如何实现从关联容器和无序容器删除元素呢? ====调用它们的成员函数。如果earse()函数。
以函数作为算法的实参
有些算法可以接受用户自定义的辅助函数,借以提高弹性和能力。这些函数将被算法内部调用。
以函数作为算法实参的实例示范
最简单的是for_each()算法,它针对区间内的每一个函数,调用一个由用户指定的函数。
void print(int elem){ cout << elem ; } int main(){ vector<int> coll{1,2,3,4}; for_each(coll.cbegin(),coll.cend(), print); cout << endl; }
算法以数种态度来面对这些辅助函数:有的是为可有可无,有的视为必要。你可以利用它们来指定查找准则,排序准则,或定义某种操作使其在“容器元素转换至另一容器”时被调用。
int Aquare(int elem){ return elem*elem ; } int main(){ vector<int> coll{1,2,3,4}; vector<int> coll2; transform(coll.cbegin(),coll.cend(), //source back_inserter(coll2), //destination squre); //operation cout << endl; }
此例是将coll的值平方,然后转移至coll2.
判断式
Predicate是一种特殊的辅助函数。会返回bool值。常被用来指定作为排序准则或者查找准则。判断式可能有一或两个操作数。
并非任何返回bool的单参函数或双参函数都是合法的判断式,stl要求,面对相同的值,predicate必须得出相同的结果。
双参数函数:
class Student{ public: string name() const; }; bool StudentSortCriterion(const Student& s1, const Student&s2) { return s1.name() < s2.name(); } int main() { deque<Student> coll; //... sort(coll.begin(),coll.end(),StudentSortCriterion); }
单参数函数:略
使用Lambda
函数对象
传递给算法的“函数型实参”不一定得是函数,可以是行为类似函数的对象。这种对象称为函数对象,或称为仿函数。
定义一个函数对象
任何东西,只要其行为像函数,它就是函数。
什么才算具备函数行为呢?所谓函数行为,是指可“使用小括号传递实参,借以调用某个东西”。例如:
functon(arg1,arg2);
对象如果也要如此,只需 定义operator(),并给予合适的参数类型:
class X{ public: return-value operator(arguments) const; };
现在,你可以把这个class 的对象当作函数来调用了:
X fo; ... fo(arg1, arg2); //call operator for function object fo
上述调用等同于;
fo.operator()(arg1, arg2);
一个完整的例子:
class PrintInt { public: void operator() (int elem) const { cout << elem << " "; } }; int main() { vector<int> coll{1,2,3,4,5,6,7,8,9}; for_each(coll.cbegin(), coll.cend(), PrintInt()); cout << endl; }
比起寻常函数,仿函数带来如下优点:
1 函数对象是一种带状态的函数。行为像pointer 的对象我们称之为smart pointer。同理,“行为像function”的对象可以称之为“smart function”,因为它们的能力超越了operator()。函数对象可以拥有成员对象和成员变量,这意味着函数对象拥有状态。事实上,在同一时间点,相同类型的两个不同的函数对象所表述的相同技能,,可具备不同的状态,这在寻常函数中是不可能的。另一个好处是,你可以在运行期初始化它们---当然必须在它们被使用(调用)之前。
2 每个函数对象都有自己的类型。寻常函数,唯有在其签名式(signature)不同时,才算类型不同。而函数对象即使签名相同,也可以有不同的类型。事实上由函数对象定义的每一个函数行为都有其自己的类型。这对于“运用template实现泛型编程”是一个卓越贡献,因为这样一来我们便可以将函数行为当作template参数来运用。这使得不同类型的容器可以使用同类型的函数对象作为排序准则。也可以确保你不会在“排序准则不同”的集合间赋值,合并,比较。你甚至可以设计函数对象的继承体系,以此完成某些特别的事情,比如在一个总体原则下确立某些特殊的情况。
3 函数对象通常比寻常函数速度快。就template概念而言,由于更多细节在编译期就已确定,所以通常可能进行更好的优化。所以,传入一个函数对象(而非寻常函数)可能获得更好的执行效能。
下面是几个例子:
对集合内的每个元素加上一个特定的值,如果在编译期便确定这个值,可以使用寻常函数完成工作:
void add10(int& elem) { elem += 10; } void f1() { vector<int> coll{ 1,2,3,4,5 }; for_each(coll.begin(), coll.end(), add10); } //如果你需要数个不同的特定值,而且他们在编译期都已经确定,可以使用template template <int theValue> void add(int& elem) { elem += theValue; } void f1() { vector<int> coll{ 1,2,3,4,5 }; for_each(coll.begin(), coll.end(), add<10>); }
如果在执行时期处理这个特定的值,那就麻烦了。你必须在函数被调用之前先将这个数值传给该函数。这通常会导致生成若干全局变量,让“算法的调用者”和“算法所调用的函数”都能看到和用到他们。这样不好。
如果两次用到该函数,每次用到的特定值不同,而且都是在执行期才处理那些特定值,那么寻常函数根本无能为力。要么传入一个标记,要么干脆写2个函数。你是否有过这样的经验:手握一个函数,他有个static变量用以记录状态(state),而你需要这个函数在同一时刻内有另外一个不同的状态?于是你只好拷贝整份函数定义,华为两个不同的函数。这正是先前所说的问题。(这段话本可以不抄,但抄下来下次看的时候就能直接点题)
如果使用函数对象,我们就可以写出更具智能的函数达成目的。对象可以有自己的状态,可以被正确初始化。下面是个完整的例子:
template <typename T> inline void PRINT_ELEMENTS(const T& coll, const std::string& optstr = "") { std::cout << optstr; for (const auto& elem : coll) { std::cout << elem << ' '; } std::cout << std::endl; } class AddValue { private: int theValue; //the value to add public: //初始化 AddValue(int v) : theValue(v) { } //函数调用 void operator()(int& elem) const { elem += theValue; } }; int main() { list<int> coll{ 1,2,3,4,5 }; PRINT_ELEMENTS(coll, "initialized: "); for_each(coll.begin(),coll.end(), AddValue(10)); PRINT_ELEMENTS(coll, "after adding 10: "); for_each(coll.begin(), coll.end(), AddValue(*coll.begin())); PRINT_ELEMENTS(coll, "after adding first of element: "); }
运行结果:
initialized: 1 2 3 4 5
after adding 10: 11 12 13 14 15
after adding first of element: 22 23 24 25 26
表达式AddValue(10)生出一个AddValue对象,并以10为初值。AddValue构造函数将这个值保存在成员theValue中。第二次也是这个机能。
预定义的函数对象
一个例子,作为排序准则的函数对象。Operator < 之默认排序准则乃是调用less<>,所以,如果你声明:set<int> coll; 会被扩展为set<int,less<int>> coll; 同样,反向排列这些元素也可以:set<int, greater<int>> coll;
另一个运用“预定义函数对象”的地点是STL算法。考虑下面的代码:
template <typename T> inline void PRINT_ELEMENTS(const T& coll, const std::string& optstr = "") { std::cout << optstr; for (const auto& elem : coll) { std::cout << elem << ' '; } std::cout << std::endl; } int main() { deque<int> coll = { 1,2,3,5,7,11,13,17,19 }; PRINT_ELEMENTS(coll, "initialized: "); transform(coll.cbegin(), coll.cend(),coll.begin(),negate<int>()); PRINT_ELEMENTS(coll, "negated: "); transform(coll.cbegin(),coll.cend(), //first source coll.cbegin(), //second source coll.begin(), //destination multiplies<int>()); //operation PRINT_ELEMENTS(coll, "squared: "); }
运行结果:
initialized: 1 2 3 5 7 11 13 17 19
negated: -1 -2 -3 -5 -7 -11 -13 -17 -19
squared: 1 4 9 25 49 121 169 289 361
negate<int>() 根据class template negate<> 生成一个函数对象,将传入的int设为负。transform()算法使用此一运算,将第一集合内的所有元素转移到第二个集合。如果转移目的地是自己,那么就是对集合内的所有元素设负值。
下面的求平方则用了transform()的另一种形式,以某个给定的运算,将两集合内的元素处理后写入第三个集合。本例中三个集合实际上是同一个,所以,自身求平方。
Binder
你可以使用特殊的function adapter(函数适配器),或者所谓的binder,将预定义的函数对象和其他数值结合为一体。一个完整的例子: