下载地址:
hadoop: http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-3.0.0/
准备工作:
1.master节点与其他节点需要建立免密登录,这个很简单,两句话搞定:
ssh-keygen
ssh-copy-id 10.1.4.58
2.安装jdk
3.配置/etc/hosts(如果配置为ip ip将会导致datanode无法识别master,下面会讲)
4.关闭防火墙
新建用户
useradd sri_udap
passwd sri_udap
输入密码
方便起见,全部采用root用户操作,新建用户只是独立出目录,后续如果需要权限管理则重新赋权
解压hadoop-3.0.0.tar.gz
tar -zxvf hadoop-3.0.0.tar.gz
加入环境变量
vi /etc/profile
添加如下内容:
export HADOOP_HOME=/home/sri_udap/app/hadoop-3.0.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
修改配置文件:
cd /home/sri_udap/app/hadoop-3.0.0/etc/hadoop/ vi hadoop-env.sh export JAVA_HOME=/usr/java/jdk1.8.0_121 vi core-site.xml
core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.1.4.57:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/sri_udap/app/hadoop-3.0.0/temp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 设置namenode的http通讯地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 设置secondarynamenode的http通讯地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
<!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/soft/hadoop-2.7.2/name</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/soft/hadoop-2.7.2/data</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- 设置 resourcemanager 在哪个节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
新建worker文件:
vi workers
添加如下:
10.1.4.58
10.1.4.59
将整个包拷贝到其他两台主机的相同位置
格式化:(格式化一次就好,多次格式化可能导致datanode无法识别,如果想要多次格式化,需要先删除数据再格式化)
./bin/hdfs namenode -format
启动
[root@10 sbin]# ./start-dfs.sh
报错:
Starting namenodes on [10.1.4.57]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [10.1.4.57]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
把缺少的环境变量加上:hadoop-env.sh
export HDFS_DATANODE_SECURE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
再启动:
又报错:
Starting namenodes on [10.1.4.57] 上一次登录:二 12月 26 15:06:36 CST 2017pts/2 上 Starting datanodes 10.1.4.58: ERROR: Cannot set priority of datanode process 5752 10.1.4.59: ERROR: Cannot set priority of datanode process 9788 Starting secondary namenodes [10.1.4.58] 上一次登录:二 12月 26 15:10:16 CST 2017pts/2 上 10.1.4.58: secondarynamenode is running as process 5304. Stop it first.
这个问题,查阅了各个方面的文档始终无法解决,不知道会不会跟hostname的写法有关系,我的/etc/hosts配置方法是,这种写法在hadoopdatanode节点启动是无法识别到master_ip的,这个问题在后面尝试中改掉了,最后会导致集群没有可用datanode,要避免这样写
10.1.4.57 10.1.4.57
10.1.4.58 10.1.4.58
10.1.4.59 10.1.4.59
尝试失败..不过据说这个问题在2.*版本中是没有出现的,所以回退一下版本
退到2.7.2,把配置拷贝过去,并在配置目录下 etc/hadoop添加两个文件
vi masters
内容:
10.1.4.57
vi slaves
内容:
10.1.4.58 10.1.4.59
启动
[root@10 sbin]# ./start-dfs.sh Starting namenodes on [10.1.4.57] 10.1.4.57: starting namenode, logging to /home/sri_udap/app/hadoop-2.7.2/logs/hadoop-root-namenode-10.1.4.57.out 10.1.4.59: starting datanode, logging to /home/sri_udap/app/hadoop-2.7.2/logs/hadoop-root-datanode-10.1.4.59.out 10.1.4.58: starting datanode, logging to /home/sri_udap/app/hadoop-2.7.2/logs/hadoop-root-datanode-10.1.4.58.out Starting secondary namenodes [10.1.4.57] 10.1.4.57: starting secondarynamenode, logging to /home/sri_udap/app/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-10.1.4.57.out [root@10 sbin]# ./start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/sri_udap/app/hadoop-2.7.2/logs/yarn-root-resourcemanager-10.1.4.57.out 10.1.4.59: starting nodemanager, logging to /home/sri_udap/app/hadoop-2.7.2/logs/yarn-root-nodemanager-10.1.4.59.out 10.1.4.58: starting nodemanager, logging to /home/sri_udap/app/hadoop-2.7.2/logs/yarn-root-nodemanager-10.1.4.58.out
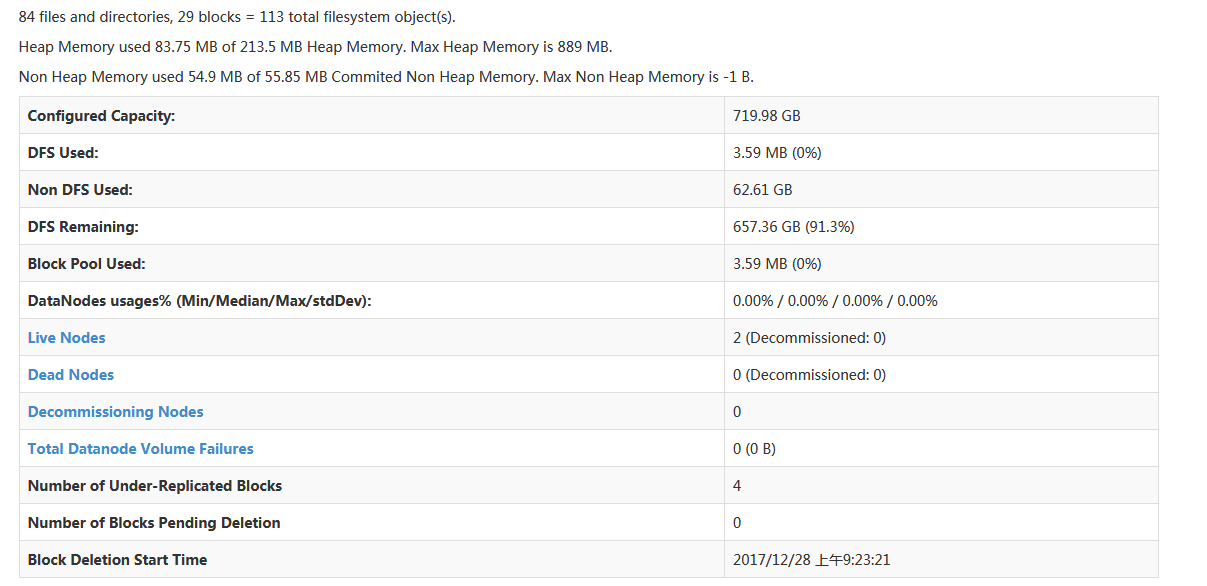
登录http://10.1.4.57:50070 查看hadoop作业情况
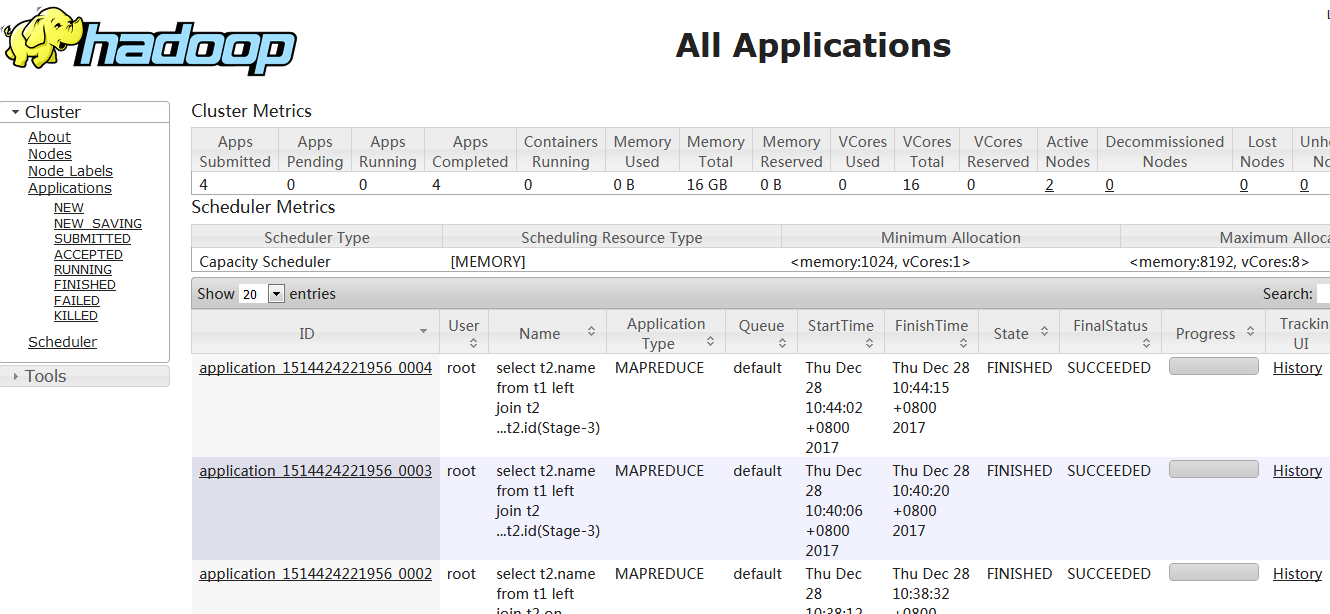
查看yarn 10.1.4.57:8088
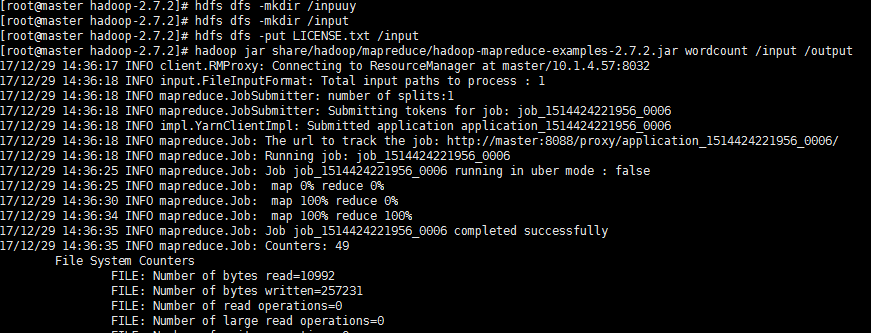
测验:
测验可以等到安装hive后一起,因为复杂的hive语句将会产生MapReduce作业在hdfs
hdfs dfs -mkdir /input hdfs dfs -put 1.txt /input hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /input /output
这样就产生了一个作业,其中1.txt是随便写的一个文件,我们运行一个单词计数作业