最近接手了公司两个项目,一个PC端后台管理系统,一个app端项目,当然使用的依然是熟悉“Vue全家桶”那套!但是,当我打开项目时,里面的代码是这样的(路由模块):
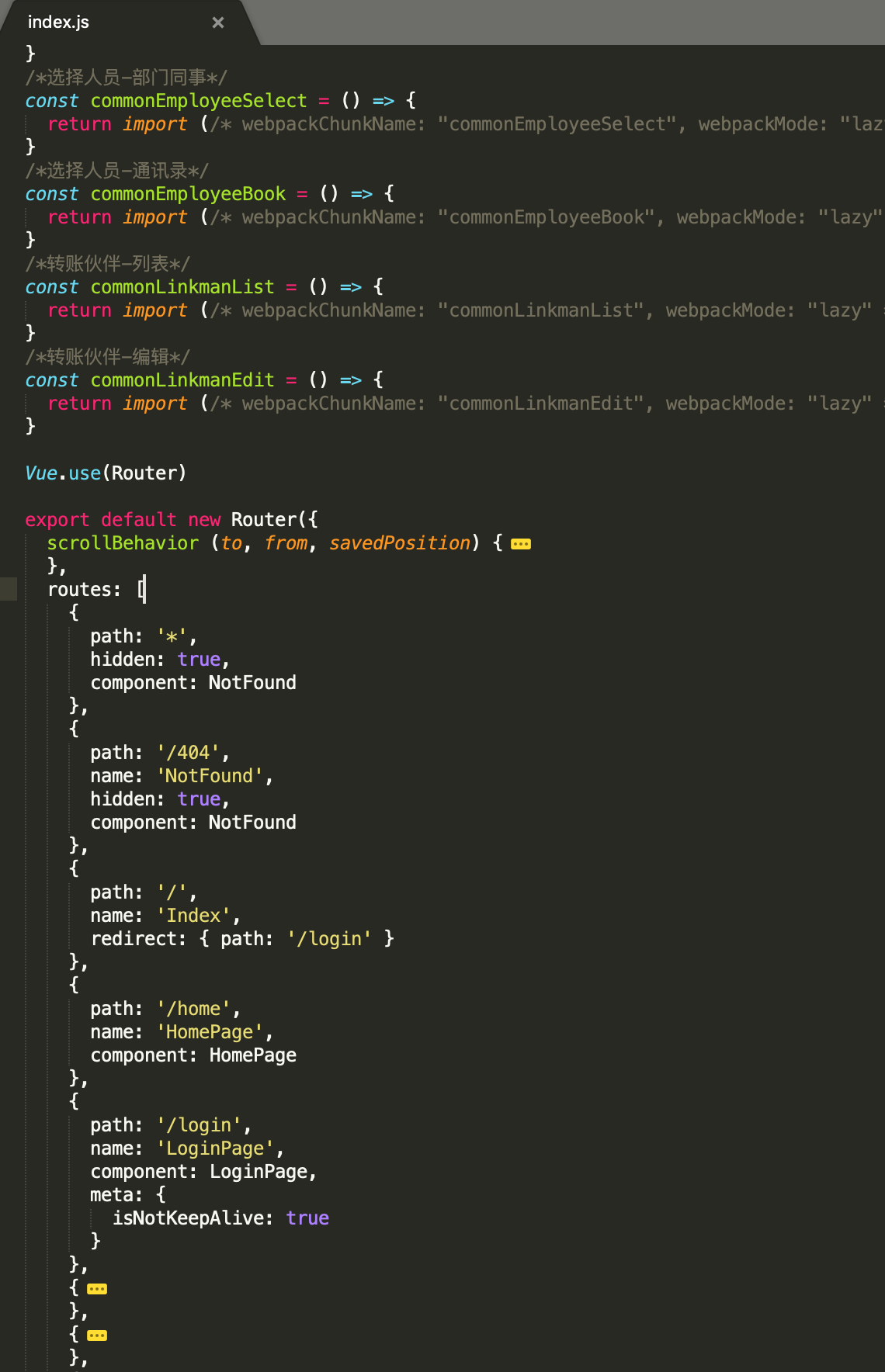
就是所有路由配置都放到一个index.js中,这多少还是让我有点惊呆的,显然,项目会越做越大,模块会越加越多,那这种不分模块的架构方式明显给以后带来很大维护困难,index.js文件会变得异常庞大...
所以,我便想趁现在代码量还在可控的情况下赶紧优化一下吧!于是,跟领导说明了用意,并很快得到了首肯!所以就开始动起来了~
1. 分模块:
首先,当然是要把不同模块的路由分离开来了(本来想只把新加入的功能模块做处理,老模块保留现状,因为复制、粘贴也是很耗体力的。但是,想想所幸现在项目还不大,再加上目前虽然不年轻但还算力壮,且还稍微有点强迫症的催动下,所以还是决定将现在有代码拆开...),心里小小斗争一下之后,就开干了!于是,就有了这样的结构:
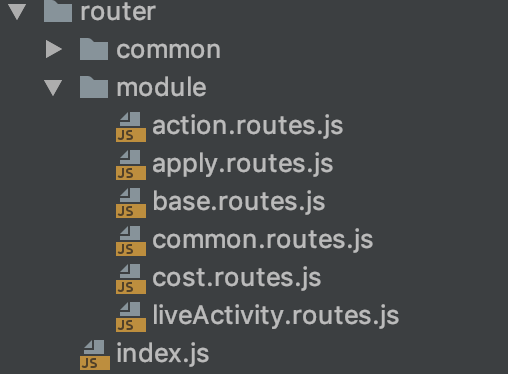
同时,让index.js的全部代码缩减成了这样:

为啥你module里的文件名会是.routes.js 呢?这个嘛...
其实是个小技巧,并不是便性规定, 1. 为了方便正则匹配,2. 为了标识文件的功能,让人一看就是知道这是路由文件...
啥正则匹配?
2. 自动导入:
为啥能将index.js缩减成这样呢?其实就是代码所示,利用了require.context来实现了自动导入...
require.context:是一个webpack提供的api,通过执行require.context函数遍历获取到指定文件夹(及其下子文件夹)内的指定文件,然后自动导入。
语法:require.context(directory, useSubdirectories = false, regExp = /^.//); 三个参数分别代表:
. directory 读取的目录;
. useSubdirectories 是否遍历目录的子目录
. regExp 匹配文件的正则表达式 (即你要读取目录下什么类型的文件,就是这个正则匹配)
require.context() 返回一个函数,该函数包含三个属性 resolve()、keys()、id 具体定义请自行到百度上谷歌一下!
我们这里用到了keys(): 返回匹配成功模块的名字组成的数组:
importAll()是对代码进行了一个封装,里面的r.keys() 得到的将是:
['./action.routes.js', './apply.routes.js', './base.routes.js', './common.routes.js', './cost.routes.js', './liveActivity.routes.js']
可以看到拿到的就是module目录里的所有文件;
拿到数组文件之后便可对其进行forEach,然后通过 `r(key).default`拿到文件的内容也就是各种模块写好的路由配置,从而也就实现了路由模块自动导入功能,从此,每次只需要要将新加的xxx.routes.js文件放入module目录(也可以是里面的子目录),也就不必手动再import了!
其实,require.context,还能实现其他模块的自动导入功能,比如:Vue官网提到的实现基础组件的全局注册(Vue官网的示例),以及对ajax Api模块化管理并自动引入等等...