一. SELECT语法介绍
官档Select语法
SELECT
-- -------------------------不推荐使用--------------------------
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[MAX_STATEMENT_TIME = N]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
-- -------------------------------------------------------------
select_expr [, select_expr ...]
[FROM table_references
[PARTITION partition_list]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
二. LIMIT 和 ORDER BY
ORDER BY 是把已经查询好的结果集进行排序
(gcdb@localhost) 11:53:54 [employees]> select * from employees limit 1; -- 从employees中 随机 取出一条数据,结果是不确定的
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
+--------+------------+------------+-----------+--------+------------+
1 row in set (0.00 sec)
# order by col_name :表示根据某列的值进行排序,默认升序
# asc : 升序(default)
# desc: 降序
(gcdb@localhost) 12:04:17 [employees]> select * from employees order by emp_no asc limit 1; -- 使用order by col_name asc进行升序排序
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
+--------+------------+------------+-----------+--------+------------+
1 row in set (0.00 sec)
(gcdb@localhost) 12:05:35 [employees]> select * from employees order by emp_no limit 1; -- 默认就是升序的,获取结果是一样
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
+--------+------------+------------+-----------+--------+------------+
1 row in set (0.00 sec)
(gcdb@localhost) 12:05:39 [employees]> select * from employees order by emp_no desc limit 1; -- desc表示降序
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 499999 | 1958-05-01 | Sachin | Tsukuda | M | 1997-11-30 |
+--------+------------+------------+-----------+--------+------------+
1 row in set (0.00 sec)
(gcdb@localhost) 12:06:21 [employees]> select * from employees order by emp_no limit 1000 ,5; -- limit start, offset;从第1000条开始取,取5条出来
+--------+------------+-------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+-------------+-----------+--------+------------+
| 11001 | 1956-04-16 | Baziley | Buchter | F | 1987-02-23 |
| 11002 | 1952-02-26 | Bluma | Ulupinar | M | 1996-12-23 |
| 11003 | 1960-11-13 | Mariangiola | Gulla | M | 1987-05-24 |
| 11004 | 1954-08-05 | JoAnna | Decleir | F | 1992-01-19 |
| 11005 | 1958-03-12 | Byong | Douceur | F | 1986-07-27 |
+--------+------------+-------------+-----------+--------+------------+
5 rows in set (0.00 sec)
-- 以上这个语法有一种分页的效果,但是会随着start的增加,性能会下降,因为会扫描表(从 1 到 start)
-- 相对比较推荐的方法
(gcdb@localhost) 12:08:58 [employees]> select * from employees where emp_no >50000 order by emp_no limit 5;
+--------+------------+------------+---------------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+---------------+--------+------------+
| 50001 | 1963-11-21 | Boguslaw | Karcich | M | 1987-08-28 |
| 50002 | 1952-03-23 | Dannz | Gecsel | M | 1986-04-09 |
| 50003 | 1960-02-14 | Avishai | McClure | M | 1987-08-17 |
| 50004 | 1964-06-11 | Kish | Quittner | M | 1990-06-29 |
| 50005 | 1962-02-25 | Kendra | Bernardinello | M | 1988-11-04 |
+--------+------------+------------+---------------+--------+------------+
5 rows in set (0.00 sec)
#
# 推荐把热数据放cache里,比如redis,memcache
#
三. WHERE 条件
WHERE是将查询出来的结果,通过WHERE后面的条件(condition),对结果进行过滤
(gcdb@localhost) 14:32:10 [employees]> select * from employees where emp_no > 30000 limit 5; -- 不加order by的limit是不确定的SQL(一般是按主键来排序)
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 30001 | 1953-03-27 | Izaskun | Morton | M | 1988-05-21 |
| 30002 | 1960-08-23 | Branimir | Snedden | M | 1998-09-24 |
| 30003 | 1952-11-25 | Takahito | Vilarrasa | M | 1990-08-22 |
| 30004 | 1957-11-26 | Lucian | Penttonen | F | 1992-10-08 |
| 30005 | 1955-10-24 | Ramachenga | Nourani | F | 1988-04-18 |
+--------+------------+------------+-----------+--------+------------+
5 rows in set (0.00 sec)
(gcdb@localhost) 14:32:28 [employees]> select * from employees where emp_no >50000 order by emp_no limit 5;
+--------+------------+------------+---------------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+---------------+--------+------------+
| 50001 | 1963-11-21 | Boguslaw | Karcich | M | 1987-08-28 |
| 50002 | 1952-03-23 | Dannz | Gecsel | M | 1986-04-09 |
| 50003 | 1960-02-14 | Avishai | McClure | M | 1987-08-17 |
| 50004 | 1964-06-11 | Kish | Quittner | M | 1990-06-29 |
| 50005 | 1962-02-25 | Kendra | Bernardinello | M | 1988-11-04 |
+--------+------------+------------+---------------+--------+------------+
5 rows in set (0.00 sec)
(gcdb@localhost) 14:45:21 [employees]> select * from employees where emp_no >50500 and hire_date >'1996-12-10' order by emp_no limit 5; -- 可以用 and 进行 逻辑与
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 50515 | 1964-02-23 | Wonhee | Camurati | M | 1998-03-25 |
| 50532 | 1964-06-23 | Kagan | Chaudhuri | M | 1998-12-28 |
| 50538 | 1961-06-27 | Ung | Mawatari | M | 1996-12-18 |
| 50551 | 1960-09-24 | Kazuhisa | Paludetto | M | 1999-08-13 |
| 50671 | 1954-08-11 | Iara | Orlowska | M | 1998-04-21 |
+--------+------------+------------+-----------+--------+------------+
5 rows in set (0.00 sec)
-- 使用()明确条件的逻辑规则并使用 or 做 逻辑或做条件筛选
(gcdb@localhost) 14:48:33 [employees]> select * from employees where emp_no >50500 and ( hire_date >'19996-12-10' or birth_date >'1963-12-10') order by emp_no limit 5;
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 50506 | 1964-02-11 | Tayeb | Lally | M | 1986-05-07 |
| 50508 | 1963-12-24 | Basim | Driscoll | M | 1990-05-09 |
| 50515 | 1964-02-23 | Wonhee | Camurati | M | 1998-03-25 |
| 50532 | 1964-06-23 | Kagan | Chaudhuri | M | 1998-12-28 |
| 50538 | 1961-06-27 | Ung | Mawatari | M | 1996-12-18 |
+--------+------------+------------+-----------+--------+------------+
5 rows in set (0.00 sec)
四. 七种JOIN
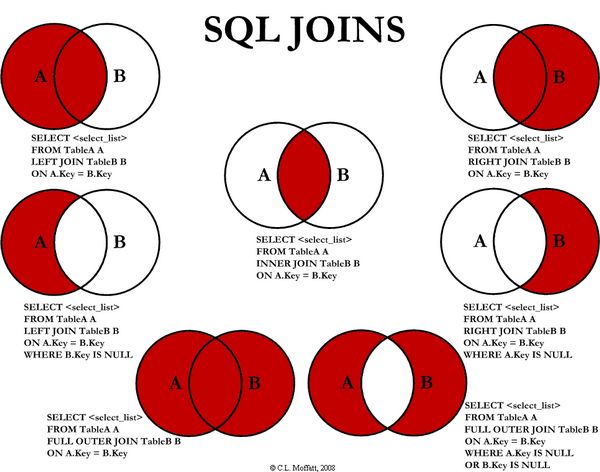
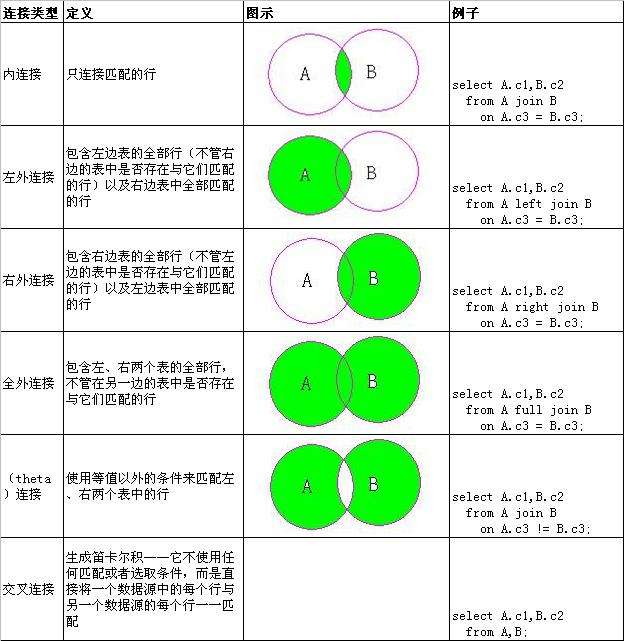

4.1. INNER JOIN(内连接)
--
-- ANSI SQL 89
-- 关联employees表和titles表
-- 要求是 employees的emp_no 等于 titles的emp_no
--
(gcdb@localhost) 15:06:00 [employees]> select * from employees e,titles t where e.emp_no = t.emp_no limit 5;
+--------+------------+------------+-----------+--------+------------+--------+-----------------+------------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date | emp_no | title | from_date | to_date |
+--------+------------+------------+-----------+--------+------------+--------+-----------------+------------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10001 | Senior Engineer | 1986-06-26 | 9999-01-01 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | 10002 | Staff | 1996-08-03 | 9999-01-01 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 | 10003 | Senior Engineer | 1995-12-03 | 9999-01-01 |
| 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 | 10004 | Engineer | 1986-12-01 | 1995-12-01 |
| 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 | 10004 | Senior Engineer | 1995-12-01 | 9999-01-01 |
+--------+------------+------------+-----------+--------+------------+--------+-----------------+------------+------------+
5 rows in set (0.00 sec)
--
-- 在上面的基础上只显示emp_no,名字,性别和职位名称
--
(gcdb@localhost) 15:00:48 [employees]> select e.emp_no,concat(last_name,' ',first_name) as name ,genderr,title from employees e,titles t where e.emp_no = t.emp_no limit 5; --concat 表示拼接显示,e.emp_no表示employees表的emp_no
+--------+-------------------+--------+-----------------+
| emp_no | name | gender | title |
+--------+-------------------+--------+-----------------+
| 10001 | Facello Georgi | M | Senior Engineer |
| 10002 | Simmel Bezalel | F | Staff |
| 10003 | Bamford Parto | M | Senior Engineer |
| 10004 | Koblick Chirstian | M | Engineer |
| 10004 | Koblick Chirstian | M | Senior Engineer | -- concat(last_name,' ',first_name) as name 取别名name
+--------+-------------------+--------+-----------------+
5 rows in set (0.00 sec)
--
-- ANSI SQL 92
-- inner join ... on ...语法
--
(gcdb@localhost) 15:08:45 [employees]> (gcdb@localhost) 15:08:45 [employees]> select * from employees e join titles t on e.emp_no = t.emp_no limit 5; - inner join 可以省略inner关键字,配合join使用on来查询,效果跟上面一样
+--------+------------+------------+-----------+--------+------------+--------+-----------------+------------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date | emp_no | title | from_date | to_date |
+--------+------------+------------+-----------+--------+------------+--------+-----------------+------------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10001 | Senior Engineer | 1986-06-26 | 9999-01-01 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | 10002 | Staff | 1996-08-03 | 9999-01-01 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 | 10003 | Senior Engineer | 1995-12-03 | 9999-01-01 |
| 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 | 10004 | Engineer | 1986-12-01 | 1995-12-01 |
| 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 | 10004 | Senior Engineer | 1995-12-01 | 9999-01-01 |
+--------+------------+------------+-----------+--------+------------+--------+-----------------+------------+------------+
5 rows in set (0.00 sec)
--
-- 上面两种语句在效率上其实是一样的,只是语法上的区别
--
--- 第一种
(gcdb@localhost) 15:10:48 [employees]> explain select * from employees e,titles t where e.emp_no = t.emp_no limit 5;
+----+-------------+-------+------------+------+---------------+---------+---------+--------------------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+--------------------+--------+----------+-------+
| 1 | SIMPLE | e | NULL | ALL | PRIMARY | NULL | NULL | NULL | 299423 | 100.00 | NULL |
| 1 | SIMPLE | t | NULL | ref | PRIMARY | PRIMARY | 4 | employees.e.emp_no | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+---------+---------+--------------------+--------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
--- 第二种
(gcdb@localhost) 15:08:50 [employees]> explain select * from employees e join titles t on e.emp_no = t.emp_no limit 5;
+----+-------------+-------+------------+------+---------------+---------+---------+--------------------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+--------------------+--------+----------+-------+
| 1 | SIMPLE | e | NULL | ALL | PRIMARY | NULL | NULL | NULL | 299423 | 100.00 | NULL |
| 1 | SIMPLE | t | NULL | ref | PRIMARY | PRIMARY | 4 | employees.e.emp_no | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+---------+---------+--------------------+--------+----------+-------+
2 rows in set, 1 warning (0.01 sec)
-- 通过explain看两条语句的执行计划,发现是一样的,所以性能上是一样的,只是语法的不同
4.2. LEFT JOIN(左连接)
--创建测试表
(gcdb@localhost) 15:25:09 [mytest]> create table a(a int);
Query OK, 0 rows affected (0.01 sec)
(gcdb@localhost) 15:25:16 [mytest]> create table b(a int);
Query OK, 0 rows affected (0.01 sec)
(gcdb@localhost) 15:33:08 [mytest]> insert into a values(1),(3),(4),(5),(7);
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
(gcdb@localhost) 15:33:38 [mytest]> insert into b values(2),(4),(8),(10);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
(gcdb@localhost) 15:33:57 [mytest]> select * from a;
+------+
| a |
+------+
| 1 |
| 3 |
| 4 |
| 5 |
| 7 |
+------+
5 rows in set (0.00 sec)
(gcdb@localhost) 15:34:09 [mytest]> select * from b;
+------+
| a |
+------+
| 2 |
| 4 |
| 8 |
| 10 |
+------+
4 rows in set (0.00 sec)
-- left join : 左表 left join 右表 on 条件;
-- 左表全部显示,右表是匹配表,
-- 如果右表的某条记录满足 [on 条件] 匹配,则该记录显示
-- 如果右表的某条记录 不 满足 匹配,则该记录显示NULL
(gcdb@localhost) 15:36:34 [mytest]> select * from a left join b on a.a=b.a;
+------+------+
| a | a |
+------+------+
| 4 | 4 | -- 满足条件的,显示t2中该条记录的值
| 1 | NULL | -- 不满足条件的,用NULL填充
| 3 | NULL |
| 5 | NULL |
| 7 | NULL |
+------+------+
5 rows in set (0.00 sec)
4.3. RIGHT JOIN(右连接)
-- right join : 左表 right join 右表 on 条件
-- 右表全部显示,左边是匹配表
-- 同样和left join,满足则显示,不满足且右表中有值,则填充NULL
(gcdb@localhost) 15:36:48 [mytest]> select * from a right join b on a.a=b.a;
+------+------+
| a | a |
+------+------+
| 4 | 4 | -- 右表(t2)全部显示,左表不满足条件的,用NULL填充
| NULL | 2 |
| NULL | 8 | -- 右表存在,左表没有,用NULL填充
| NULL | 10 |
+------+------+
4 rows in set (0.00 sec)
mysql> insert into test_left_join_2 values (3); -- t2 中再增加一条记录
Query OK, 1 row affected (0.03 sec)
mysql> select * from
-> test_left_join_1 as t1
-> right join
-> test_left_join_2 as t2
-> on t1.a = t2.b;
+------+------+
| a | b |
+------+------+
| 1 | 1 |
| NULL | 3 | -- 右表存在,左表没有,用NULL填充
+------+------+
2 rows in set (0.00 sec)
--
-- 查找在t1表,而不在t2表的数据
--
mysql> select * from
-> test_left_join_1 as t1
-> left join
-> test_left_join_2 as t2
-> on t1.a = t2.b where t2.b is null;
+------+------+
| a | b |
+------+------+
| 2 | NULL | -- 数据1 在t1和t2中都有,所以不显示
+------+------+
1 row in set (0.00 sec)
-- left join : left outer join , outer关键字可以省略
-- right join: right outer join , outer关键字可以省略
-- join无论inner还是outer,列名不需要一样,甚至列的类型也可以不一样,会进行转换。
-- 一般情况下,表设计合理,需要关联的字段类型应该是一样的
4.4. LEFT JOIN(左连接),左表独有
-- 左表中不包含右边的值
(gcdb@localhost) 15:50:43 [mytest]> select * from a left join b on a.a=b.a where b.a is null;
+------+------+
| a | a |
+------+------+
| 1 | NULL |
| 3 | NULL |
| 5 | NULL |
| 7 | NULL |
+------+------+
4 rows in set (0.00 sec)
4.5. RIGHT JOIN(右连接),右表独有
--右表中不包含左表的值
(gcdb@localhost) 15:50:02 [mytest]> select * from a right join b on a.a=b.a where a.a is null;
+------+------+
| a | a |
+------+------+
| NULL | 2 |
| NULL | 8 |
| NULL | 10 |
+------+------+
3 rows in set (0.00 sec)
-- 在 inner join中,过滤条件放在where或者on中都是可以的
-- 在 outer join中 条件放在where和on中是不一样的
4.6.FULL JOIN(全连接)
(gcdb@localhost) 16:04:00 [mytest]> select * from a left join b on a.a=b.a union select * from a right join b on a.a=b.a ;
+------+------+
| a | a |
+------+------+
| 4 | 4 |
| 1 | NULL |
| 3 | NULL |
| 5 | NULL |
| 7 | NULL |
| NULL | 2 |
| NULL | 8 |
| NULL | 10 |
+------+------+
8 rows in set (0.00 sec)
4.7.FULL JOIN(并集去交集)
(gcdb@localhost) 16:00:48 [mytest]> select * from a left join b on a.a=b.a where b.a is null union select * from a right join b on a.a=b.a where a.a is null;
+------+------+
| a | a |
+------+------+
| 1 | NULL |
| 3 | NULL |
| 5 | NULL |
| 7 | NULL |
| NULL | 2 |
| NULL | 8 |
| NULL | 10 |
+------+------+
7 rows in set (0.00 sec)
4.8. 笛卡尔积
--笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X×Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员
(gcdb@localhost) 16:00:45 [mytest]> select * from a full join b ;
+------+------+
| a | a |
+------+------+
| 1 | 2 |
| 1 | 4 |
| 1 | 8 |
| 1 | 10 |
| 3 | 2 |
| 3 | 4 |
| 3 | 8 |
| 3 | 10 |
| 4 | 2 |
| 4 | 4 |
| 4 | 8 |
| 4 | 10 |
| 5 | 2 |
| 5 | 4 |
| 5 | 8 |
| 5 | 10 |
| 7 | 2 |
| 7 | 4 |
| 7 | 8 |
| 7 | 10 |
+------+------+
20 rows in set (0.00 sec)
4.3. GROUP BY
dbt3库网盘地址
--
-- 找出同一个部门的员工数量
--
(root@localhost) 16:17:07 [employees]> select dept_no,count(emp_no) as emp_num from dept_emp group bydept_no; -- 通过 dept_no 分组,用count emp_no 来统计数量
+---------+---------+
| dept_no | emp_num |
+---------+---------+
| d001 | 20211 |
| d002 | 17346 |
| d003 | 17786 |
| d004 | 73485 |
| d005 | 85707 |
| d006 | 20117 |
| d007 | 52245 |
| d008 | 21126 |
| d009 | 23580 |
+---------+---------+
9 rows in set (0.14 sec)
--
-- 选出部门人数 > 20000
--
(root@localhost) 16:18:21 [employees]> select dept_no,count(emp_no) as emp_num from dept_emp group bydept_no having emp_num >20000; -- 如果是对分组的聚合函数做过滤,使用having,用where报语法错误
+---------+---------+
| dept_no | emp_num |
+---------+---------+
| d001 | 20211 |
| d004 | 73485 |
| d005 | 85707 |
| d006 | 20117 |
| d007 | 52245 |
| d008 | 21126 |
| d009 | 23580 |
+---------+---------+
7 rows in set (0.15 sec)
--
-- 每个用户每个月产生的订单数目
--
(root@localhost) 16:20:35 [employees]> use dbt3;
Database changed
(root@localhost) 16:21:52 [dbt3]> desc orders;
+-----------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+-------------+------+-----+---------+-------+
| o_orderkey | int(11) | NO | PRI | NULL | | -- 订单ID
| o_custkey | int(11) | YES | MUL | NULL | | -- 客户ID
| o_orderstatus | char(1) | YES | | NULL | |
| o_totalprice | double | YES | | NULL | |
| o_orderDATE | date | YES | MUL | NULL | | -- 订单日期
| o_orderpriority | char(15) | YES | | NULL | |
| o_clerk | char(15) | YES | | NULL | |
| o_shippriority | int(11) | YES | | NULL | |
| o_comment | varchar(79) | YES | | NULL | |
+-----------------+-------------+------+-----+---------+-------+
9 rows in set (0.00 sec)
mysql> select o_orderkey, o_custkey, o_orderDATE from orders limit 3;
+------------+-----------+-------------+
| o_orderkey | o_custkey | o_orderDATE |
+------------+-----------+-------------+
| 1 | 36901 | 1996-01-02 |
| 2 | 78002 | 1996-12-01 |
| 3 | 123314 | 1993-10-14 |
+------------+-----------+-------------+
3 rows in set (0.00 sec)
--
-- 查找客户每年每月产生的订单数
--
(root@localhost) 16:46:03 [dbt3]> select o_custkey as 客户,count(o_orderkey) as 订单总数 ,year(o_orderDATE) as 年 , month(o_orderDATE) as 月 from orders group by o_custkey,year(o_orderDATE),month(o_orderDATE) limit 10;
+--------+--------------+------+------+
| 客户 | 订单总数 | 年 | 月 |
+--------+--------------+------+------+
| 1 | 1 | 1992 | 4 |
| 1 | 1 | 1992 | 8 |
| 1 | 1 | 1996 | 6 |
| 1 | 1 | 1996 | 7 |
| 1 | 1 | 1996 | 12 |
| 1 | 1 | 1997 | 3 |
| 2 | 1 | 1992 | 4 |
| 2 | 1 | 1994 | 5 |
| 2 | 1 | 1994 | 8 |
| 2 | 1 | 1994 | 12 |
+--------+--------------+------+------+
10 rows in set (6.98 sec)
-- 使用 date_format 函数
(root@localhost) 16:47:03 [dbt3]> select o_custkey, count(o_orderkey),
-> date_format(o_orderDATE, '%Y-%m') as date
-> from orders
-> group by o_custkey, date_format(o_orderDATE, '%Y-%m')
-> limit 10;
+-----------+-------------------+---------+
| o_custkey | count(o_orderkey) | date |
+-----------+-------------------+---------+
| 1 | 1 | 1992-04 |
| 1 | 1 | 1992-08 |
| 1 | 1 | 1996-06 |
| 1 | 1 | 1996-07 |
| 1 | 1 | 1996-12 |
| 1 | 1 | 1997-03 |
| 2 | 1 | 1992-04 |
| 2 | 1 | 1994-05 |
| 2 | 1 | 1994-08 |
| 2 | 1 | 1994-12 |
+-----------+-------------------+---------+
10 rows in set (11.46 sec)
-- 查找客户每周(以年,月,周 显示)产生的订单量
(root@localhost) 17:05:37 [dbt3]> SELECT o_custkey AS 客户, count(o_orderkey) AS 订单总数, YEAR (o_orderDATE) AS 年, MONTH (o_orderDATE) AS 月, WEEK(o_orderDATE) AS 周 FROM orders GROUP BYo_custkey, YEAR (o_orderDATE) , MONTH (o_orderDATE), WEEK(o_orderDATE) LIMIT 30;
+--------+--------------+------+------+------+
| 客户 | 订单总数 | 年 | 月 | 周 |
+--------+--------------+------+------+------+
| 1 | 1 | 1992 | 4 | 16 |
| 1 | 1 | 1992 | 8 | 33 |
| 1 | 1 | 1996 | 6 | 25 |
| 1 | 1 | 1996 | 7 | 26 |
| 1 | 1 | 1996 | 12 | 49 |
| 1 | 1 | 1997 | 3 | 12 |
| 2 | 1 | 1992 | 4 | 14 |
| 2 | 1 | 1994 | 5 | 20 |
| 2 | 1 | 1994 | 8 | 35 |
| 2 | 1 | 1994 | 12 | 51 |
| 2 | 1 | 1995 | 3 | 10 |
| 2 | 1 | 1996 | 8 | 31 |
| 2 | 1 | 1997 | 2 | 7 |
| 4 | 1 | 1992 | 4 | 17 |
| 4 | 1 | 1992 | 9 | 38 |
| 4 | 1 | 1993 | 10 | 40 |
| 4 | 1 | 1994 | 6 | 23 |
| 4 | 1 | 1995 | 5 | 18 |
| 4 | 1 | 1995 | 11 | 44 |
| 4 | 2 | 1996 | 1 | 0 |
| 4 | 2 | 1996 | 6 | 22 |
| 4 | 1 | 1996 | 8 | 30 | --用年月周来统计4号客户1996年8月2个单,分别是第30周一个单,第32周一个单
| 4 | 1 | 1996 | 8 | 32 | --第32周一个单
| 4 | 1 | 1996 | 11 | 47 |
| 4 | 1 | 1997 | 3 | 9 |
| 4 | 1 | 1997 | 6 | 23 |
| 4 | 1 | 1997 | 7 | 27 |
| 4 | 1 | 1997 | 9 | 36 |
| 4 | 1 | 1997 | 10 | 39 |
| 4 | 1 | 1997 | 11 | 47 |
+--------+--------------+------+------+------+
30 rows in set (7.25 sec)
(root@localhost) 17:06:52 [dbt3]> SELECT o_custkey AS 客户, count(o_orderkey) AS 订单总数, YEAR (o_orderDATE) AS 年, MONTH (o_orderDATE) AS 月 FROM orders GROUP BY o_custkey, YEAR (o_orderDDATE) , MONTH (o_orderDATE) LIMIT 30;
+--------+--------------+------+------+
| 客户 | 订单总数 | 年 | 月 |
+--------+--------------+------+------+
| 1 | 1 | 1992 | 4 |
| 1 | 1 | 1992 | 8 |
| 1 | 1 | 1996 | 6 |
| 1 | 1 | 1996 | 7 |
| 1 | 1 | 1996 | 12 |
| 1 | 1 | 1997 | 3 |
| 2 | 1 | 1992 | 4 |
| 2 | 1 | 1994 | 5 |
| 2 | 1 | 1994 | 8 |
| 2 | 1 | 1994 | 12 |
| 2 | 1 | 1995 | 3 |
| 2 | 1 | 1996 | 8 |
| 2 | 1 | 1997 | 2 |
| 4 | 1 | 1992 | 4 |
| 4 | 1 | 1992 | 9 |
| 4 | 1 | 1993 | 10 |
| 4 | 1 | 1994 | 6 |
| 4 | 1 | 1995 | 5 |
| 4 | 1 | 1995 | 11 |
| 4 | 2 | 1996 | 1 |
| 4 | 2 | 1996 | 6 |
| 4 | 2 | 1996 | 8 | --用年月来统计4号客户1996年8月2个单
| 4 | 1 | 1996 | 11 |
| 4 | 1 | 1997 | 3 |
| 4 | 1 | 1997 | 6 |
| 4 | 1 | 1997 | 7 |
| 4 | 1 | 1997 | 9 |
| 4 | 1 | 1997 | 10 |
| 4 | 1 | 1997 | 11 |
| 4 | 1 | 1998 | 5 |
+--------+--------------+------+------+
30 rows in set (6.97 sec)
(root@localhost) 17:07:30 [dbt3]>