An input operation copies data from an I/O device to main memory, and an output operation copies data from memory to a device.
All language run-time systems provide higher-level facilities for performing I/O.
On Unix systems, these higher-level I/O functions are implemented using system-level Unix I/O functions provided by the kernel.
--Sometimes you have no choice but to use Unix I/O
For example, the standard I/O library provides no way to access file metadata such as file size or file creation time.
Further, there are problems with the standard I/O library that make it risky to use for network programming.
A Unix file is a sequence of m bytes:
B0,B1,...,Bk,...,Bm−1.
All I/O devices, such as networks, disks, and terminals, are modeled as files, and all input and output is performed by reading and writing the appropriate files.
This elegant mapping of devices to files allows the Unix kernel to export a simple, low- level application interface, known as Unix I/O, that enables all input and output to be performed in a uniform and consistent way:
Opening files. An application announces its intention to access an I/O device by asking the kernel to open the corresponding file.
The kernel returns a small nonnegative integer, called a descriptor, that identifies the file in all subsequent operations on the file.
The kernel keeps track of all information about the open file. The application only keeps track of the descriptor.
Each process created by a Unix shell begins life with three open files: standard input (descriptor 0), standard output (descriptor 1), and standard error (descriptor 2).
The header file <unistd.h> defines constants STDIN_ FILENO, STDOUT_FILENO, and STDERR_FILENO, which can be used instead of the explicit descriptor values.
Changing the current file position. The kernel maintains a file position k, ini- tially 0, for each open file.
The file position is a byte offset from the beginning of a file. An application can set the current file position k explicitly by per- forming a seek operation.
Reading and writing files.
A read operation copies n > 0 bytes from a file to memory, starting at the current file position k, and then incrementing k by n.
Given a file with a size of m bytes, performing a read operation when k ≥ m triggers a condition known as end-of-file (EOF), which can be detected by the application. There is no explicit “EOF character” at the end of a file.
Similarly, a write operation copies n > 0 bytes from memory to a file, starting at the current file position k, and then updating k.
Closing files. When an application has finished accessing a file, it informs the kernel by asking it to close the file.
The kernel responds by freeing the data structures it created when the file was opened and restoring the descriptor to a pool of available descriptors.
When a process terminates for any reason, the kernel closes all open files and frees their memory resources.
Opening and Closing Files
A process opens an existing file or creates a new file by calling the open function:

The open function converts a filename to a file descriptor and returns the descriptor number.
The descriptor returned is always the smallest descriptor that is not currently open in the process. The flags argument indicates how the process intends to access the file:
-
. O_RDONLY: Reading only
-
. O_WRONLY: Writing only
-
. O_RDWR: Reading and writing
The mode argument specifies the access permission bits of new files.
As part of its context, each process has a umask that is set by calling the umask function.
When a process creates a new file by calling the open function with some mode argument, then the access permission bits of the file are set to mode & ~umask.
Reading and Writing Files

The read function copies at most n bytes from the current file position of descriptor fd to memory location buf.
A return value of −1 indicates an error, and a return value of 0 indicates EOF. Otherwise, the return value indicates the number of bytes that were actually transferred.
In some situations, read and write transfer fewer bytes than the application requests. Such short counts do not indicate an error. They occur for a number of reasons:
-
. Encountering EOF on reads.
-
. Reading text lines from a terminal. If the open file is associated with a terminal (i.e., a keyboard and display), then each read function will transfer one text line at a time, returning a short count equal to the size of the text line.
-
. Reading and writing network sockets. If the open file corresponds to a network socket (Section 11.3.3), then internal buffering constraints and long network delays can cause read and write to return short counts. Short counts can also occur when you call read and write on a Unix pipe, an interprocess communication mechanism that is beyond our scope.
Reading File Metadata
The stat function takes as input a file name and fills in the members of a stat structure shown in Figure 10.8. The fstat function is similar, but takes a file descriptor instead of a file name.
Unix recognizes a number of different file types.
A regular file contains some sort of binary or text data. To the kernel there is no difference between text files and binary files.
A directory file contains information about other files.
A socket is a file that is used to communicate with another process across a network (Section 11.4).
Unix provides macro predicates for determining the file type from the st_mode member.
Sharing Files
The kernel represents open files using three related data structures:
-
Descriptor table. Each process has its own separate descriptor table whose en- tries are indexed by the process’s open file descriptors. Each open descriptor entry points to an entry in the file table.
-
. File table. The set of open files is represented by a file table that is shared by all processes. Each file table entry consists of (for our purposes) the current file position, a reference count of the number of descriptor entries that currently point to it, and a pointer to an entry in the v-node table. Closing a descriptor decrements the reference count in the associated file table entry. The kernel will not delete the file table entry until its reference count is zero.
-
. v-node table. Like the file table, the v-node table is shared by all processes. Each entry contains most of the information in the stat structure, including the st_mode and st_size members.
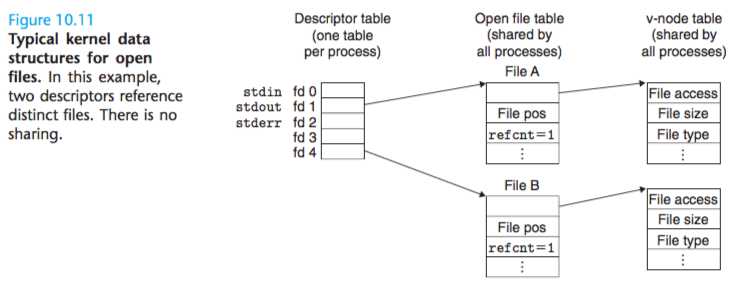
This is the typical situation, where files are not shared, and where each descriptor corresponds to a distinct file.

As shown in Figure 10.12. This might happen, for example, if you were to call the open function twice with the same filename.
The key idea is that each descriptor has its own distinct file position, so different reads on different descriptors can fetch data from different locations in the file.
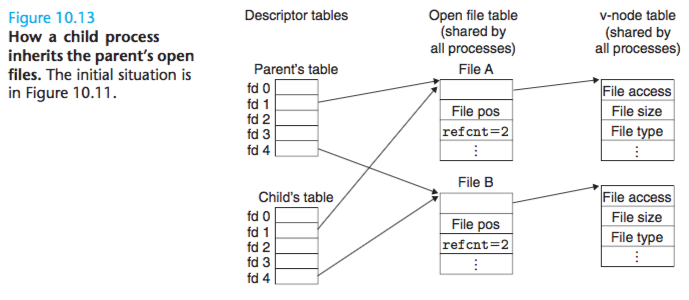
We can also understand how parent and child processes share files. Suppose that before a call to fork, the parent process has the open files shown in Fig- ure 10.11. Then Figure 10.13 shows the situation after the call to fork. The child gets its own duplicate copy of the parent’s descriptor table. Parent and child share the same set of open file tables, and thus share the same file position. An important consequence is that the parent and child must both close their descriptors before the kernel will delete the corresponding file table entry.
I/O Redirection
Unix shells provide I/O redirection operators that allow users to associate standard input and output with disk files.
So how does I/O redirection work? One way is to use the dup2 function.

The dup2 function copies descriptor table entry oldfd to descriptor table entry newfd, overwriting the previous contents of descriptor table entry newfd.
If newfd was already open, then dup2 closes newfd before it copies oldfd.
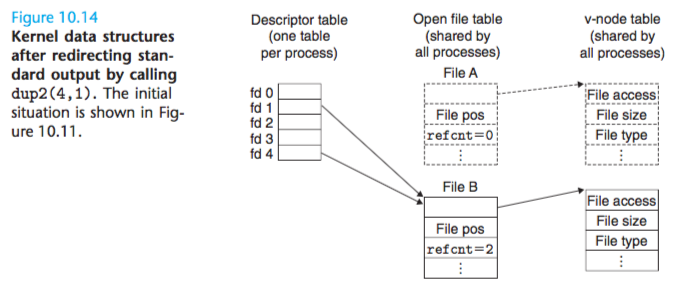
Suppose that before calling dup2(4,1) we have the situation in Figure 10.11, where descriptor 1 (standard output) corresponds to file A (say, a terminal), and descriptor 4 corresponds to file B (say, a disk file). The reference counts for A and B are both equal to 1.
Figure 10.14 shows the situation after calling dup2(4,1).
Both descriptors now point to file B; file A has been closed and its file table and v-node table entries deleted;
and the reference count for file B has been incremented. From this point on, any data written to standard output is redirected to file B.
Standard I/O
ANSI C defines a set of higher level input and output functions, called the standard I/O library, that provides programmers with a higher-level alternative to Unix I/O.
The library (libc) provides functions for opening and closing files (fopen and fclose), reading and writing bytes (fread and fwrite), reading and writing strings (fgets and fputs), and sophisticated formatted I/O (scanf and printf).
The standard I/O library models an open file as a stream. To the programmer, a stream is a pointer to a structure of type FILE.
Every ANSI C program begins with three open streams, stdin, stdout, and stderr, which correspond to standard input, standard output, and standard error, respectively
A stream of type FILE is an abstraction for a file descriptor and a stream buffer.
The purpose of the stream buffer is the same as the Rio read buffer: to minimize the number of expensive Unix I/O system calls.
For example, suppose we have a program that makes repeated calls to the standard I/O getc function, where each invocation returns the next character from a file.
When getc is called the first time, the library fills the stream buffer with a single call to the read function, and then returns the first byte in the buffer to the application.
As long as there are unread bytes in the buffer, subsequent calls to getc can be served directly from the stream buffer.
Putting It Together: Which I/O Functions Should I Use?
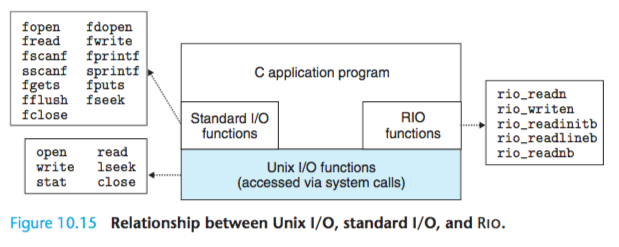
Unix I/O is implemented in the operating system kernel.
It is available to applications through functions such as open, close, lseek, read, write, and stat functions.
The higher-level Rio and standard I/O functions are implemented “on top of” (using) the Unix I/O functions. The Rio functions are robust wrappers for read and write that were developed specifically for this textbook.
They au- tomatically deal with short counts and provide an efficient buffered approach for reading text lines.
The standard I/O functions provide a more complete buffered alternative to the Unix I/O functions, including formatted I/O routines.
Most C programmers use standard I/O exclusively throughout their careers, never both- ering with the lower-level Unix I/O functions.
The Unix abstraction for a network is a type of file called a socket.
Like any Unix file, sockets are referenced by file descriptors, known in this case as socket descriptors.
Application processes communicate with processes running on other computers by reading and writing socket descriptors.
Standard I/O streams are full duplex in the sense that programs can perform input and output on the same stream.
However, there are poorly documented restrictions on streams that interact badly with restrictions on sockets:
Restriction 1: Input functions following output functions. An input function cannot follow an output function without an intervening call to fflush, fseek, fsetpos, or rewind.
The fflush function empties the buffer associated with a stream. The latter three functions use the Unix I/O lseek function to reset the current file position.
Restriction 2: Output functions following input functions. An output function cannot follow an input function without an intervening call to fseek, fsetpos, or rewind, unless the input function encounters an end-of-file.
These restrictions pose a problem for network applications because it is illegal to use the lseek function on a socket.
The first restriction on stream I/O can be worked around by adopting a discipline of flushing the buffer before every input operation.
However, the only way to work around the second restriction is to open two streams on the same open socket descriptor, one for reading and one for writing:
FILE *fpin, *fpout; fpin = fdopen(sockfd, "r"); fpout = fdopen(sockfd, "w");
But this approach has problems as well, because it requires the application to call fclose on both streams in order to free the memory resources associated with each stream and avoid a memory leak:
fclose(fpin);
fclose(fpout);
Each of these operations attempts to close the same underlying socket descrip- tor, so the second close operation will fail.
This is not a problem for sequential programs, but closing an already closed descriptor in a threaded program is a recipe for disaster (see Section 12.7.4).
Thus, we recommend that you not use the standard I/O functions for input and output on network sockets.Use the robust Rio functions instead.
If you need formatted output, use the sprintf function to format a string in memory, and then send it to the socket using rio_writen.
If you need formatted input, use rio_ readlineb to read an entire text line, and then use sscanf to extract different fields from the text line.