Modern operating systems provide three basic approaches for building concurrent programs:
-
Processes. With this approach, each logical control flow is a process that is scheduled and maintained by the kernel. Since processes have separate virtual address spaces, flows that want to communicate with each other must use some kind of explicit interprocess communication (IPC) mechanism.
-
I/O multiplexing.This is a form of concurrent programming where applications explicitly schedule their own logical flows in the context of a single process. Logical flows are modeled as state machines that the main program explicitly transitions from state to state as a result of dataarriving on file descriptors. Since the program is a single process, all flows share the same address space.
-
Threads. Threads are logical flows that run in the context of a single process and are scheduled by the kernel. You can think of threads as a hybrid of the other two approaches, scheduled by the kernel like process flows, and sharing the same virtual address space like I/O multiplexing flows.
Concurrent Programming with Processes
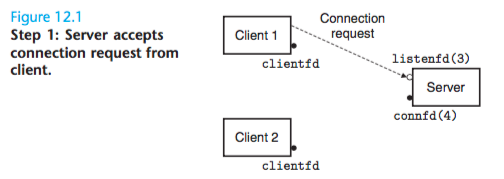
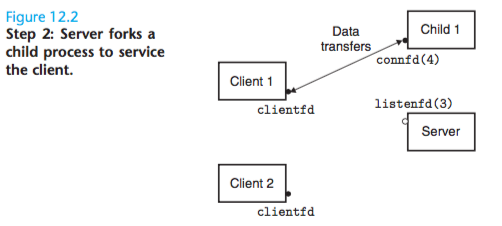
The child closes its copy of listening descriptor 3, and the parent closes its copy of connected descriptor 4, since they are no longer needed.
Since the connected descriptors in the parent and child each point to the same file table entry, it is crucial for the parent to close its copy of the connected descriptor.
Otherwise, the file table entry for connected descriptor 4 will never be released, and the resulting memory leak will eventually consume the available memory and crash the system.
Concurrent Programming with I/O Multiplexing
A Concurrent Event-Driven Server Based on I/O Multiplexing
# TO study carefully
Concurrent Programming with Threads
The threads are scheduled automatically by the kernel.
Each thread has its own thread context, including a unique integer thread ID (TID), stack, stack pointer, program counter, general-purpose registers, and condition codes.
All threads running in a process share the entire virtual address space of that process.
Logical flows based on threads combine qualities of flows based on processes and I/O multiplexing.
Like processes, threads are scheduled automatically by the kernel and are known to the kernel by an integer ID.
Like flows based on I/O multiplexing, multiple threads run in the context of a single process, and thus share the entire contents of the process virtual address space, including its code, data, heap, shared libraries, and open files.
Thread Execution Model
Each process begins life as a single thread called the main thread.
At some point, the main thread creates a peer thread, and from this point in time the two threads run concurrently.
Eventually, control passes to the peer thread via a context switch, because the main thread executes a slow system call such as read or sleep, or because it is interrupted by the system’s interval timer.
The peer thread executes for a while before control passes back to the main thread, and so on.
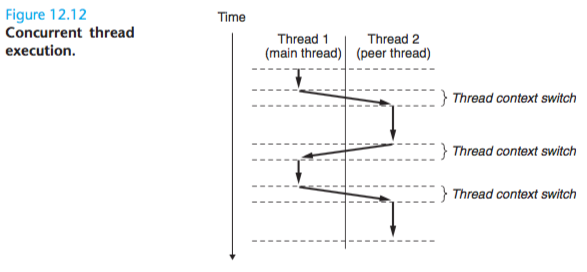
Thread execution differs from processes in some important ways.
Because a thread context is much smaller than a process context, a thread context switch is faster than a process context switch.
Another difference is that threads, unlike pro- cesses, are not organized in a rigid parent-child hierarchy.
The threads associated with a process form a pool of peers, independent of which threads were created by which other threads.
The main thread is distinguished from other threads only in the sense that it is always the first thread to run in the process.
The main impact of this notion of a pool of peers is that a thread can kill any of its peers, or wait for any of its peers to terminate.
Further, each peer can read and write the same shared data.
Posix Threads
Creating Threads
Threads create other threads by calling the pthread_create function.

The pthread_create function creates a new thread and runs the thread rou- tine f in the context of the new thread and with an input argument of arg.
The attr argument can be used to change the default attributes of the newly created thread. Changing these attributes is beyond our scope, and in our examples, we will always call pthread_create with a NULL attr argument.
When pthread_create returns, argument tid contains the ID of the newly created thread.
The new thread can determine its own thread ID by calling the pthread_self function.

Terminating Threads
A thread terminates in one of the following ways:
-
. The thread terminates implicitly when its top-level thread routine returns.
-
. The thread terminates explicitly by calling the pthread_exit function. If the main thread calls pthread_exit, it waits for all other peer threads to terminate, and then terminates the main thread and the entire process with a return value of thread_return.

-
. Some peer thread calls the Unix exit function, which terminates the process and all threads associated with the process.
-
. Another peer thread terminates the current thread by calling the pthread_cancel function with the ID of the current thread.

Reaping Terminated Threads
Threads wait for other threads to terminate by calling the pthread_join function.

The pthread_join function blocks until thread tid terminates, assigns the generic (void *) pointer returned by the thread routine to the location pointed to by thread_return, and then reaps any memory resources held by the terminated thread.
Notice that, unlike the Unix wait function, the pthread_join function can only wait for a specific thread to terminate.
There is no way to instruct pthread_wait to wait for an arbitrary thread to terminate.
This can complicate our code by forcing us to use other, less intuitive mechanisms to detect process termination. Indeed, Stevens argues convincingly that this is a bug in the specification [109].
Detaching Threads
At any point in time, a thread is joinable or detached.
A joinable thread can be reaped and killed by other threads. Its memory resources (such as the stack) are not freed until it is reaped by another thread.
In contrast, a detached thread cannot be reaped or killed by other threads. Its memory resources are freed automatically by the system when it terminates.
By default, threads are created joinable.
In order to avoid memory leaks, each joinable thread should either be explicitly reaped by another thread, or detached by a call to the pthread_detach function.

For example, a high-performance Web server might create a new peer thread each time it receives a connection re- quest from a Web browser.
Since each connection is handled independently by a separate thread, it is unnecessary—and indeed undesirable—for the server to ex- plicitly wait for each peer thread to terminate.
In this case, each peer thread should detach itself before it begins processing the request so that its memory resources can be reclaimed after it terminates.
Initializing Threads
The pthread_once function allows you to initialize the state associated with a thread routine.

The once_control variable is a global or static variable that is always initial- ized to PTHREAD_ONCE_INIT.
The first time you call pthread_once with an argument of once_control, it invokes init_routine, which is a function with no input arguments that returns nothing.
Subsequent calls to pthread_once with the same once_control variable do nothing.
The pthread_once function is useful whenever you need to dynamically initialize global variables that are shared by multiple threads.
A Concurrent Server Based on Threads
The first issue is how to pass the con- nected descriptor to the peer thread when we call pthread_create.
The obvious approach is to pass a pointer to the descriptor, as in the following:

Then we have the peer thread dereference the pointer and assign it to a local variable, as follows:

This would be wrong, however, because it introduces a race between the as- signment statement in the peer thread and the accept statement in the main thread.
If the assignment statement completes before the next accept, then the lo- cal connfd variable in the peer thread gets the correct descriptor value.
However, if the assignment completes after the accept, then the local connfd variable in the peer thread gets the descriptor number of the next connection.
The unhappy result is that two threads are now performing input and output on the same descriptor.
In order to avoid the potentially deadly race, we must assign each connected de- scriptor returned by accept to its own dynamically allocated memory block, as shown in lines 21–22:

Another issue is avoiding memory leaks in the thread routine.
Since we are not explicitly reaping threads, we must detach each thread so that its memory resources will be reclaimed when it terminates (line 31).
Further, we must be careful to free the memory block that was allocated by the main thread (line 32).
