一.梯度下降
梯度下降就是最简单的用于神经网络当中用于更新参数的用法,计算loss的公式如下:
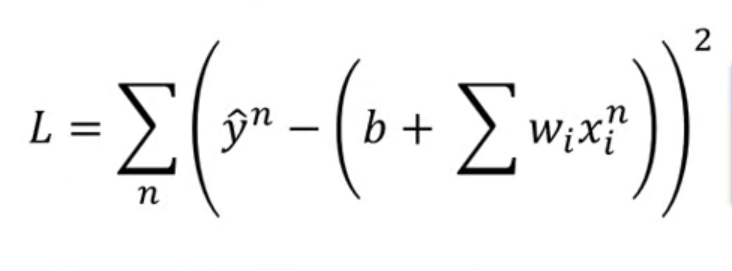
有了loss function之后,我们立马通过这个loss求解出梯度,并将梯度用于参数theta的更新,如下所示:
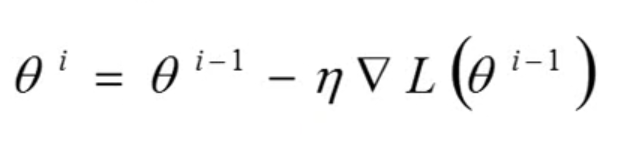
这样做之后,我们只需要遍历所有的样本,就可以得到一个最终的参数theta了,这个参数可能是全局最小值,也可能不是,因为很有可能走入了一个loss的局部最小值当中。
二.随机梯度下降(SGD)
随机梯度下降与梯度下降相比,其实也会遍历全部的样本,但是只会梯度在遍历同样样本数量的情况下会下降得更快。因为我们首先将全部样本切分成m个样本,然后对这m个样本进行遍历,更新参数,用一个一个切分后的样本更新完参数之后,保留目前的theta的值,基于这个theta的值,继续用下一个样本进行参数theta的优化。
下面是梯度下降的loss在图像当中的表示:
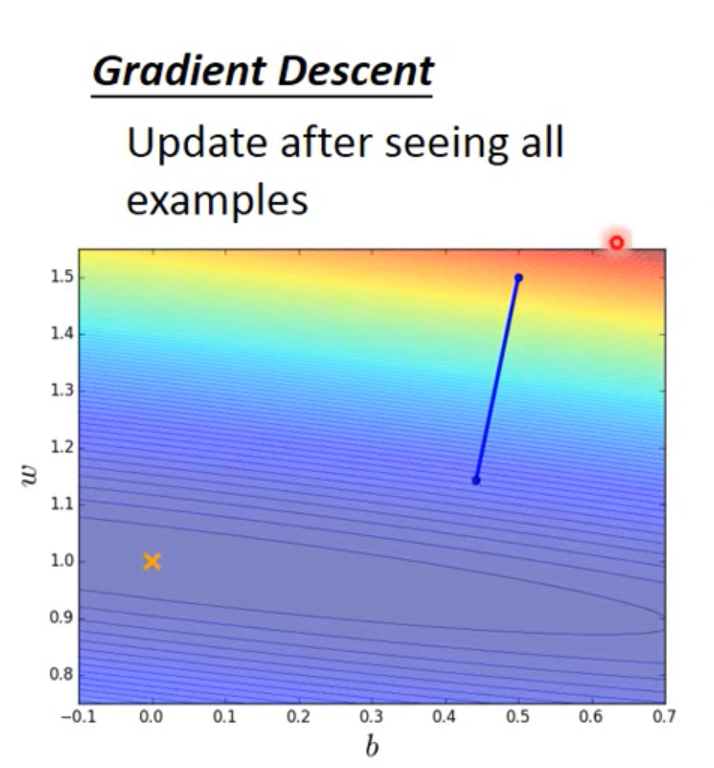
这是SGD,将样本进行切分之后的loss的变化:
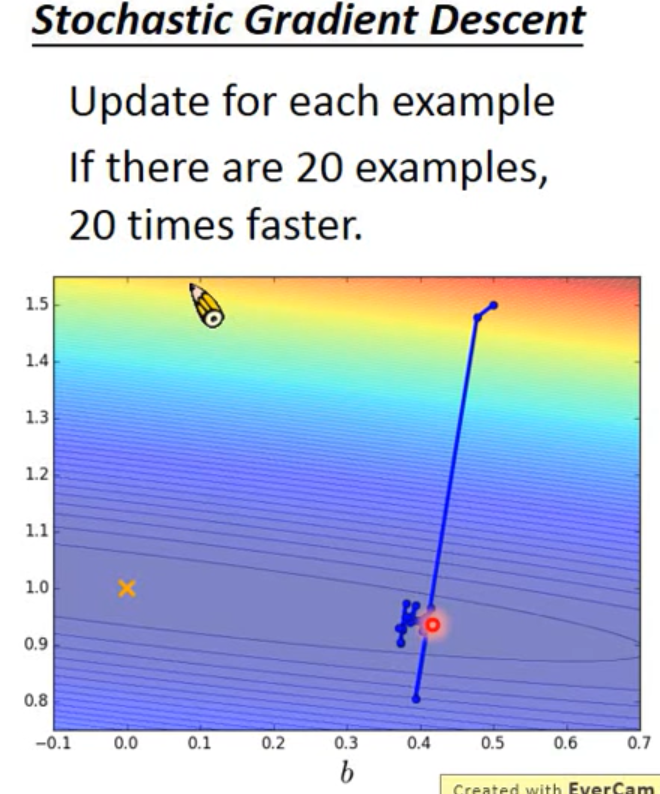
三.mini-batch梯度下降
mini-batch和SGD稍微有点不同,那就是mini-batch每次进行参数更新的同时,使用了多个样本继续参数的更新,loss下降的速度会比SGD更慢,但是结果回避SGD更加准确。
这就是我们常用的用于梯度下降的方法啦!希望大家有所收获,有疑问的话可以在下方的疑问区提出!