1. 问题分析

如图,在开始训练后, loss升高到87.3365后保持不变。这个问题是因为梯度爆炸导致的。
loss -= log(std::max(prob_data[i * dim + label_value * inner_num_ + j],
Dtype(FLT_MIN)));
在softmax_loss_layer.cpp的原码中,loss的最大值由FLT_MIN得到,FLT_MIN定义为1.17549435E-38F,这个数字的自然对数正好就是
-87.3356,算loss时需要取负值,结果就能了87.3356。
这说明softmax计算得到概率值出现了零(由于float类型所能表示的最小数值是10−3810−38,比这个值还小的无法表示,只能是零)
而softmax是用指数函数计算的,指数函数的值都是大于零的。因此,我们有理由相信,计算过程中出现了float溢出等异常,出现了inf,nan等异常数值导致softmax输出为零
最后我们发现,当softmax之前的feature值过大时,由于softmax先求指数,会超出float数据范围,成为inf。inf与其他任何数值的和都是inf,softmax在做除法时任何正常范围的数值除以inf都会变为0。然后求loss时log一下就出现了87.3356这样的值。
2. 解决办法
1. 降低学习率,提高batchsize,这样就能减小权重参数的波动范围,从而减小权重变大的可能性
2. 输入归一化
用均值文件归一化
transform_param {
mirror: true
crop_size: 331
mean_file: "lmdb_data/img_test_lmdb/mean.binaryproto"
3. 查看输入数据、标签是否有异常,
solver.prototxt中设置,debug_info: true
标签仔细看了,从0到60,总分类个数也改成了61
数据都是严格按照预处理lmdb来的。
4. 数据shuffle
已经在lmdb数据生成时进行了shuffle。
5. batch normalization的设置
如果有BN(batch normalization)层,finetune时最好不要冻结BN的参数,否则数据分布不一致时很容易使输出值变的很大.
我的问题
我这里碰到的问题,其实是通过第6点解决的。如图,inception_resnet_v2是我从github上找的,其中use_global_stats值为true.应当进行修改,训练阶段是false,测试阶段是true。
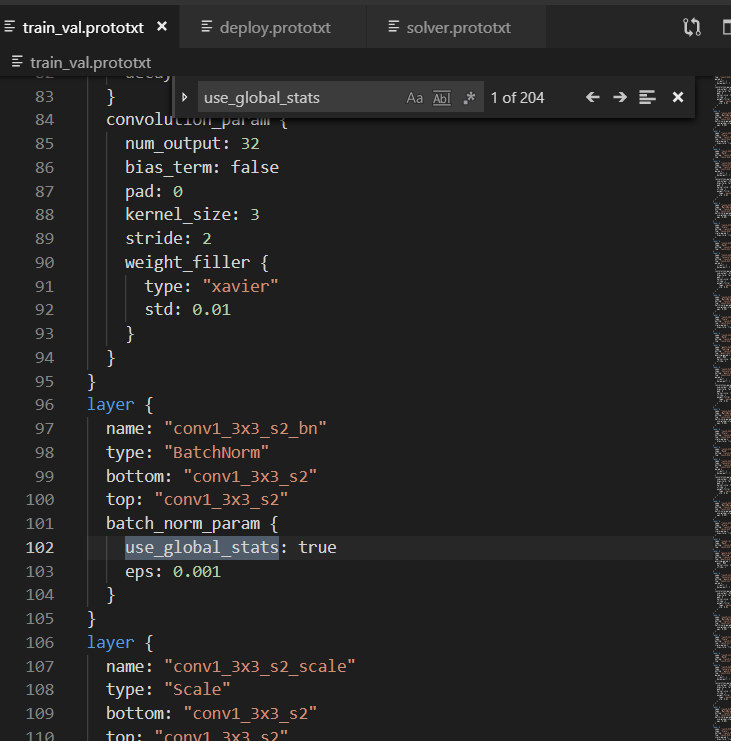
将batch normaliztion的use_global_stats由true改成false.
batch_norm_param {
use_global_stats: false
}