复习
'''
流程控制
1.顺序结构、分支结构、循环结构
2.if分支结构
if 条件:
代码块
elif 条件:
代码块
else:
代码块
# 可以被if转换为False:0 | '' | None | [] | {}
3.while循环结构
while 条件:
循环体
# 1)可以通过改变循环变量,使循环条件不满足
# 2)当达到特定条件,直接使用break来强行结束所属循环
break:结束所属循环
continue:结束所属循环的本次循环进入下一次循环
while...else...:当循环正常结束,else分支才会被执行(break结束的循环才叫不正常结束)
4.for循环(迭代器)
# for循环:用来循环容器对象的(左右多个值的对象)
# range(end) # [0, end)
# range(start, end) # [start, end)
# range(start, end, step) # [start, end, 步长)
'''
今日内容
'''
数据类型的使用
# int | complex | float | str | bool | list | dict | tuple | set
# 重点:
# 数据类型的重点方法
# 可变与不可变类型
# 数据类型的相互转化
# 非重点:
# 数据类型不常用的方法
'''
数字类型
# 了了解:py2中小整数用int存放,大整数用long
# 1.整型
num = -1000000000000000000000000000000000000000000000000
print(num, type(num))
# 2.小数
num = 3.14
print(num, type(num))
# 3.布尔
res = True
print(res, type(res), isinstance(res, int))
print(3.14 + True)
# 4.复数
num = complex(5, 4) # 5 + 4j
print(num + (4 + 5j))
# 重点:数字类型之间的相互转化 *****
a = 10
b = 3.74
c = True
print(int(a), int(b), int(c))
print(float(a), float(b), float(c))
print(bool(a), bool(b), bool(c))
字符串类型
# 1.定义: 可以有多种引号嵌套
# 需求:你是"好学生"
s1 = "你是"好学生""
print(s1)
# 可以通过引号的嵌套,使内部不同的引号在不转义的情况下直接输出
s2 = '你是"好学生"'
print(s2)
# 需求:你是"好学生",是'我的'
s3 = """你是"好学生",是'我的'"""
print(s3)
字符串的常规操作
# 1.字符串的索引取值: 字符串[index]
# 正向取值从0编号,反向取值从-1编号
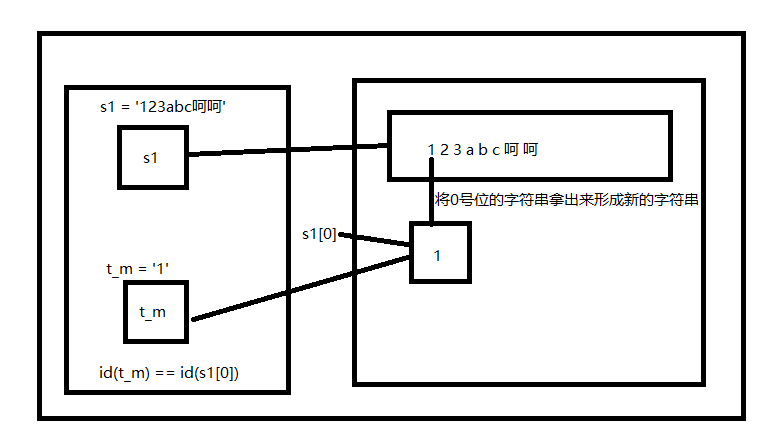
s1 = '123abc呵呵'
print(id(s1)) # 2217572683576
print(s1[0], id(s1[0])) # 2217543167200
t_s = '1'
print(id(t_s)) # 2217543167200
# 取出c
print(s1[5], s1[-3])
# 2.字符串拼接
s2 = '你好'
s22 = '帅'
ss2 = s2 + s22
print(ss2, id(s2), id(s22), id(ss2))
# 如果要拼接其他类型
a = 10
b = "20"
c = True
# res = "1020True"
res = "%s%s%s" % (a, b, c) # 方法1
print(res)
res = str(a) + b + str(c) # 方法2
print(res)
# 3.字符串长度
s3 = '12345'
ln1 = s3.__len__()
print(ln1)
ln2 = len(s3)
print(ln2)
# 4.字符串切片: 取子字符串 - [::] - [start_index:end_index:step]
s4 = '123abc呵呵'
sub_s = s4[0:6:]
print(sub_s) # 123abc
sub_s = s4[0:6:2]
print(sub_s) # 13b
sub_s = s4[::-1]
print(sub_s) # 呵呵cba321
sub_s = s4[-1:-6:-1]
print(sub_s) # 呵呵cba
# 5.成员运算:判断某字符串是否在该字符串中
s5 = '123abc呵呵'
ss5 = '12a'
print(ss5 in s5) # False
print(ss5 not in s5) # True
# 6.字符串循环(遍历)
s6 = '123abc呵呵'
for v in s5:
print(v)
重要方法
# 1.索引(目标字符串的索引位置)
s1 = '123abc呵呵'
print(s1.index('b'))
# 2.去留白(默认去两端留白,也可以去指定字符)
s2 = '***好 * 的 ***'
print(s2.strip('*'))
# 3.计算子字符串个数
s3 = '12312312'
print(s3.count('123'))
# 4.判断字符串是否是数字:只能判断正整数
s4 = '123'
print(s4.isdigit())
# 5.大小写转换
s5 = "AbC def"
print(s5.upper()) # 全大写
print(s5.lower()) # 全小写
# 了了解
print(s5.capitalize()) # 首字母大写
print(s5.title()) # 每个单词首字母大写
# 6.以某某开头或结尾
s6 = 'https://www.baidu.com'
r1 = s6.startswith('https:')
r2 = s6.startswith('http:')
r3 = s6.endswith('com')
r4 = s6.endswith('cn')
if (r1 or r2) and (r3 or r4):
print('合法的链接')
else:
print('非合法的链接')
# 7.替换
s7 = 'egon say: he is da shuai b,egon!egon!egon!'
new_s7 = s7.replace('egon', 'Liu某') # 默认替换所有
print(new_s7)
new_s7 = s7.replace('egon', 'Liu某', 1) # 替换一次
print(new_s7)
# 8.格式化
s8 = 'name:{},age:{}'
print(s8.format('Owen', 18)) # 默认按位置
print('name:{0},age:{1}, height:{1}'.format('Owen', 18)) # 标注位置,一个值可以多次利用
print('name:{n},age:{a}, height:{a}'.format(a=18, n="Zero")) # 指名道姓
了了解
'''
1. find | rfind:查找子字符串索引,无结果返回-1
2. lstrip:去左留白
3. rstrip:去右留白
4. center | ljust | rjust | zfill:按位填充
语法:center(所占位数, '填充符号')
5. expandtabs:规定 所占空格数
6. captialize | title | swapcase:首字母大写 | 单词首字母大写 | 大小写反转
7. isdigit | isdecimal | isnumeric:数字判断
8. isalnum | isalpha:是否由字母数字组成 | 由字母组成
9. isidentifier:是否是合法标识符
10. islower | isupper:是否全小 | 大写
11. isspace:是否是空白字符
12. istitle:是否为单词首字母大写格式
'''
列表类型
# 定义:
# 1.list中可以存放多个值,可以存放所有类型的数据
# 2.list中有序的,可以通过索引取值
常规操作
# 1.索引取值: 列表名[index]
s1 = [1, 3, 2]
print(s1[0])
print(s1[-1])
# 2.列表运算: 得到的是新list
s2 = [1, 2, 3]
print(s2 + s2)
print(s2 * 2)
print(s2)
# 3.list的长度
s3 = [3, 4, 1, 2, 5]
print(len(s3))
# 4.切片:[start_index:end_index:step]
s4 = [3, 4, 1, 2, 5]
new_s4 = s4[::-1]
print(new_s4)
new_s4 = s4[1:4:]
print(new_s4)
new_s4 = s4[-2:-5:-1]
print(new_s4)
# 5.成员运算:in
s5 = [3, 4, '1', 2, 5]
print('1' in s5)
print(1 in s5)
print(5 not in s5)
# 6.循环
for v in s5:
print(v, type(v))
# 只打印数字类型的数据
for v in s5:
if isinstance(v, int):
print(v, end=' ')
增删改查
# 1.列表的增删改查
ls = [1, 2, 3]
# 查
print(ls)
print(ls[1])
# 增
ls.append(0) # 末尾增
print(ls)
ls.insert(1, 666) # 任意index前增
print(ls)
ls.insert(len(ls), 888) # insert实行末尾增
print(ls)
# 改
ls[1] = 66666
print(ls)
# 删
ls.remove(888)
print(ls)
res = ls.pop() # 默认从末尾删,并返还删除的值
print(res)
res = ls.pop(1) # 从指定索引删除,并返还删除的值
print(res, ls)
# 了了解
del ls[2]
print(res, ls)
# 清空
ls.clear()
print(ls)
了解的方法
# 1)排序: 针对于同类型
ls = ['3', '1', '2']
ls.sort() # 默认正向排序
print(ls)
ls.sort(reverse=True) # 正向排序结果上翻转,形成倒序
print(ls)
# 2)翻转
ls = ['3', '1', '2']
ls.reverse() # 按存储的顺序进行翻转
print(ls)
# 3)计算值的个数 => 列表中可以存放重复数据
ls = [1, 2, 1, 2, 3, 1]
print(ls.count(1)) # 对象1存在的次数
了了解
# 1)整体增加,添加到末尾
ls = [1, 2, 3]
ls.extend('123')
print(ls)
ls.extend([0, 1, 2])
print(ls)
# 2) 目标的索引位置,可以规定查找区间
ls = [1, 2, 1, 2, 3, 1]
# 找对象1,在索引3开始往后找到索引6之前
ind = ls.index(1, 3, 6)
print(ind)
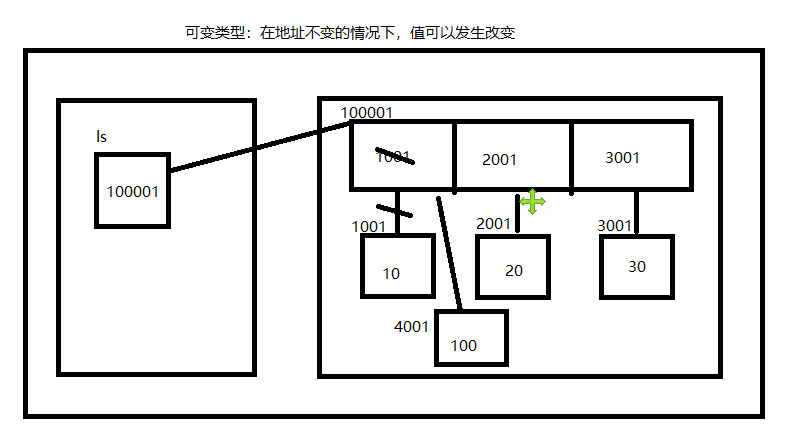
可变类型与不可变类型