Redis
一、简介
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
1. 竞品
a. Memcached介绍
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提供动态、数据库驱动网站的速度,现在已被LiveJournal、hatena、Facebook、Vox、LiveJournal等公司所使用。
b. Memcached工作方式分析
许多Web应用都将数据保存到 RDBMS中,应用服务器从中读取数据并在浏览器中显示。 但随着数据量的增大、访问的集中,就会出现RDBMS的负担加重、数据库响应恶化、 网站显示延迟等重大影响。Memcached是高性能的分布式内存缓存服务器,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web等应用的速度、 提高可扩展性。下图展示了memcache与数据库端协同工作情况:

c. 过程
- 1.检查用户请求的数据是缓存中是否有存在,如果有存在的话,只需要直接把请求的数据返回,无需查询数据库。
- 2.如果请求的数据在缓存中找不到,这时候再去查询数据库。返回请求数据的同时,把数据存储到缓存中一份。
- 3.保持缓存的“新鲜性”,每当数据发生变化的时候(比如,数据有被修改,或被删除的情况下),要同步的更新缓存信息,确保用户不会在缓存取到旧的数据。
2. 对比优缺点
- a. Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等。
- b. Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
- c. 虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
- d. 过期策略–memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10
- e. 存储数据安全–memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)
- f. 灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
- g. Redis支持数据的备份,即master-slave模式的数据备份。
3. 总结
应该说Memcached和Redis都能很好的满足解决我们的问题,它们性能都很高,总的来说,可以把Redis理解为是对Memcached的拓展,是更加重量级的实现,提供了更多更强大的功能。具体来说:
-
1.性能上:
性能上都很出色,具体到细节,由于Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比 Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis最近也在存储大数据的性能上进行优化,但是比起Memcached,还是稍有逊色。 -
2.内存空间和数据量大小:
MemCached可以修改最大内存,采用LRU算法。Redis增加了VM的特性,突破了物理内存的限制。 -
3.操作便利上:
MemCached数据结构单一,仅用来缓存数据,而Redis支持更加丰富的数据类型,也可以在服务器端直接对数据进行丰富的操作,这样可以减少网络IO次数和数据体积。 -
4.可靠性上:
MemCached不支持数据持久化,断电或重启后数据消失,但其稳定性是有保证的。Redis支持数据持久化和数据恢复,允许单点故障,但是同时也会付出性能的代价。 -
5.应用场景:
Memcached:动态系统中减轻数据库负载,提升性能;做缓存,适合多读少写,大数据量的情况(如人人网大量查询用户信息、好友信息、文章信息等)。
Redis:适用于对读写效率要求都很高,数据处理业务复杂和对安全性要求较高的系统(如新浪微博的计数和微博发布部分系统,对数据安全性、读写要求都很高)。
需要慎重考虑的部分
- 1.Memcached单个key-value大小有限,一个value最大只支持1MB,而Redis最大支持512MB
- 2.Memcached只是个内存缓存,对可靠性无要求;而Redis更倾向于内存数据库,因此对对可靠性方面要求比较高
- 3.从本质上讲,Memcached只是一个单一key-value内存Cache;而Redis则是一个数据结构内存数据库,支持五种数据类型,因此Redis除单纯缓存作用外,还可以处理一些简单的逻辑运算,Redis不仅可以缓存,而且还可以作为数据库用
二、安装
1. Window
-
Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包到 C 盘,解压后,将文件夹重新命名为 redis。
-
打开一个 cmd 窗口 使用 cd 命令切换目录到 C: edis 运行:
redis-server.exe redis.windows.conf -
这时候另启一个 cmd 窗口,原来的不要关闭,不然就无法访问服务端了。切换到 redis 目录下运行:
redis-cli.exe -h 127.0.0.1 -p 6379
2. Linux
-
命令安装
$ wget http://download.redis.io/releases/redis-5.0.7.tar.gz $ tar xzf redis-5.0.7.tar.gz $ cd redis-5.0.7 $ make -
src目录中现在提供了已编译的二进制文件 。使用以下命令运行Redis:$ src/redis-server -
运行
$ src/redis-cli redis> set foo bar OK redis> get foo "bar" -
关闭
- 如果是用apt-get或者yum install安装的redis,可以直接通过下面的命令停止/启动/重启redis
/etc/init.d/redis-server stop /etc/init.d/redis-server start /etc/init.d/redis-server restart- 如果是通过源码安装的redis,则可以通过redis的客户端程序redis-cli的shutdown命令来重启redis
redis-cli -h 127.0.0.1 -p 6379 shutdown如果上述方式都没有成功停止redis,则可以使用终极武器 kill -9
三、配置
1. 配置文件
语法:
// 获取
CONFIG GET CONFIG_SETTING_NAME
// 编辑
CONFIG SET CONFIG_SETTING_NAME NEW_CONFIG_VALUE
实例:
127.0.0.1:6379> CONFIG GET loglevel
1) "loglevel"
2) "notice"
127.0.0.1:6379> config set appendonly yes
127.0.0.1:6379> config set save ""
OK
2. 常用配置属性
-
Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
daemonize no -
当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis.pid -
指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
port 6379 -
绑定的主机地址
bind 127.0.0.1 -
当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 300 -
指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose -
日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout -
设置数据库的数量,默认数据库为0,可以使用SELECT
命令在连接上指定数据库id databases 16 -
指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
save <seconds> <changes> Redis默认配置文件中提供了三个条件: save 900 1 save 300 10 save 60 10000分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
-
指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes -
指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb -
指定本地数据库存放目录
dir ./ -
设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof <masterip> <masterport> -
当master服务设置了密码保护时,slav服务连接master的密码
masterauth <master-password> -
设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH
命令提供密码,默认关闭 requirepass foobared -
设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxclients 128 -
指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory <bytes> -
指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendonly no -
指定更新日志文件名,默认为appendonly.aof
appendfilename appendonly.aof -
指定更新日志条件,共有3个可选值:
no:表示等操作系统进行数据缓存同步到磁盘(快)
always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)
everysec:表示每秒同步一次(折衷,默认值)appendfsync everysec -
指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中
vm-enabled no -
虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap -
将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-max-memory 0 -
Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值
vm-page-size 32 -
设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。
vm-pages 134217728 -
设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4 -
设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
glueoutputbuf yes -
指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64 hash-max-zipmap-value 512 -
指定是否激活重置哈希,默认为开启
activerehashing yes -
指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
include /path/to/local.conf
四、数据类型
1. 字符串(String)
string 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。
string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。
string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。
使用场景:微博数,粉丝数、缓存、限流、计数器等
2. 散列(Hash)
Redis hash 是一个键值(key=>value)对集合。
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
使用场景:存储用户信息,商品信息、组合查询等
3. 列表(List)
list 就是链表,Redis list 的应用场景非常多,也是Redis最重要的数据结构之一
Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销
使用场景:微博的关注列表,粉丝列表,消息列表等功能
4. 集合(Set)
Redis 的 Set 是 string 类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
使用场景:赞、踩、关注、共同关注、共同粉丝、共同喜好等功能
5. 有序集合(Sorted Set)
和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列
使用场景:排行榜、弹幕消息等
6.其他类型
五、命令
1. Redis 操作
redis-server; // 启动服务
redis-cli -h 127.0.0.1 -p 6379 // 连接redis -h 主机地址 -p 端口号
127.0.0.1:6379> PING // 客户端下验证服务器
PONG
127.0.0.1:6379> exit // 退出客户端
// 关闭服务器
redis-cli -h 127.0.0.1 -p 6379 shutdown
&
ps -ef | grep redis // 拿到redis的服务进程号如1688
kill -9 1688
2. Key
Redis 键命令的基本语法如下:
127.0.0.1:6379> COMMAND KEY_NAME
// 例子
127.0.0.1:6379> set gerf redis
OK
127.0.0.1:6379> get gerf
"redis"
相关命令:
// DEL key 该命令用于在 key 存在时删除 key
127.0.0.1:6379> set gerf redis
OK
127.0.0.1:6379> del gef
(integer) 0
// DUMP key 序列化给定 key ,并返回被序列化的值
127.0.0.1:6379> set gerf redis
OK
127.0.0.1:6379> dump gerf // 存在则返回序列化值
"x00x05redis x00x15xa2xf8=xb6xa9xdex90"
127.0.0.1:6379> dump aaa // 不存在则返回 (nil)
(nil)
// EXISTS key 检查给定 key 是否存在
127.0.0.1:6379> EXISTS aaa
(integer) 0 // 不存在返回 0
127.0.0.1:6379> EXISTS gerf
(integer) 1 // 存在返回 1
// 为给定 key 设置过期时间,以秒计
127.0.0.1:6379> EXPIREAT gerf 5
(integer) 1
127.0.0.1:6379> EXISTS gerf
(integer) 0
Redis keys 命令
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | DEL key | 该命令用于在 key 存在时删除 key。 |
| 2 | DUMP key | 序列化给定 key ,并返回被序列化的值。 |
| 3 | EXISTS key | 检查给定 key 是否存在。 |
| 4 | EXPIRE key seconds | 为给定 key 设置过期时间,以秒计。 |
| 5 | EXPIREAT key timestamp | EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。 |
| 6 | PEXPIRE key milliseconds | 设置 key 的过期时间以毫秒计。 |
| 7 | PEXPIREAT key milliseconds-timestamp | 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 |
| 8 | KEYS pattern | 查找所有符合给定模式( pattern)的 key 。 |
| 9 | MOVE key db | 将当前数据库的 key 移动到给定的数据库 db 当中。 |
| 10 | PERSIST key | 移除 key 的过期时间,key 将持久保持。 |
| 11 | PTTL key | 以毫秒为单位返回 key 的剩余的过期时间。 |
| 12 | TTL key | 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。 |
| 13 | RANDOMKEY | 从当前数据库中随机返回一个 key。 |
| 14 | RENAME key newkey | 修改 key 的名称 |
| 15 | RENAMENX key newkey | 仅当 newkey 不存在时,将 key 改名为 newkey 。 |
| 16 | TYPE key | 返回 key 所储存的值的类型。 |
3. String
在绝大部分编程语言中都有 String 字符串类型,对于作为数据库的 Redis 也是必不可少的。
- set key value 设置值
- get key 获取某个key的值
- mset key1 value1 key2 value2 批量设置并且是原子的,可以用来减少网络时间消耗
- mget key1 key2 批量获取并且是原子的,可以用来减少网络时间消耗
127.0.0.1:6379> set user1 aaa
OK
127.0.0.1:6379> mset user2 bbb user3 ccc
OK
127.0.0.1:6379> get user1
"aaa"
127.0.0.1:6379> mget user1 user2 user3
1) "aaa"
2) "bbb"
3) "ccc"
- incr key 自增指定key的值
- decr key 自减指定key的值
- incrby key value 自增指定数值
- decrby key value 自减指定数值
- incrbyfloat key floatvalue 增加指定浮点数
127.0.0.1:6379> set count 1
OK
127.0.0.1:6379> incr count
(integer) 2
127.0.0.1:6379> get count
"2"
127.0.0.1:6379> decr count
(integer) 1
127.0.0.1:6379> get count
"1"
127.0.0.1:6379> incrby count 99
(integer) 100
127.0.0.1:6379> get count
"100"
127.0.0.1:6379> decrby count 99
(integer) 1
127.0.0.1:6379> get count
"1"
127.0.0.1:6379> incrbyfloat count 0.5
"1.5"
127.0.0.1:6379> get count
"1.5"
- 前面几个操作就可以用来实现计数器的功能。
- setnx key value 如果不存在该key则可以设置成功,否则会失败,加上过期时间限制,则是redis实现分布式锁的一种方式(后面会提到)。
- set key value xx 与前面相反,如果存在则设置成功,否则失败(相当于更新操作)
127.0.0.1:6379> keys *
1) "user1"
2) "user4"
3) "user2"
4) "user3"
5) "count"
127.0.0.1:6379> setnx user1 11aa
(integer) 0
127.0.0.1:6379> get user1
"aaa"
127.0.0.1:6379> setnx user5 55aa
(integer) 1
127.0.0.1:6379> get user5
"55aa"
127.0.0.1:6379> set user4 show xx
OK
127.0.0.1:6379> get user4
"show"
- getset key newvalue 设置新值并返回旧值
- append key value 为原本内容追加内容
- strlen key 获取字符串长度
- getrange key start end 获取指定范围的内容
- setrange key index value 设置指定范围的内容
127.0.0.1:6379> keys *
1) "user1"
2) "user5"
3) "user4"
4) "user2"
5) "user3"
6) "count"
127.0.0.1:6379> get user1
"aaa"
127.0.0.1:6379> getset user1 11aa
"aaa"
127.0.0.1:6379> get user1
"11aa"
127.0.0.1:6379> append user1 22bb
(integer) 8
127.0.0.1:6379> get user1
"11aa22bb"
127.0.0.1:6379> strlen user
(integer) 0
127.0.0.1:6379> strlen user1
(integer) 8
127.0.0.1:6379> getrange user1 0 5
"11aa22"
127.0.0.1:6379> setrange user1 5 cc
(integer) 8
127.0.0.1:6379> get user1
"11aa2ccb"
- setex key seconds value 设置值且设置过期时间
- set key value ex seconds nx 为不存在的key设置值且设置过期时间
127.0.0.1:6379> setex user 10 user111
OK
127.0.0.1:6379> ttl user
(integer) 5
127.0.0.1:6379> ttl user
(integer) 1
127.0.0.1:6379> ttl user
(integer) 0
127.0.0.1:6379> set user1 snow ex 10 nx
(nil)
127.0.0.1:6379> set user snow ex 10 nx
OK
127.0.0.1:6379> get user
(nil)
127.0.0.1:6379> set user snow ex 20 nx
OK
127.0.0.1:6379> get user
"snow"
127.0.0.1:6379> ttl user
(integer) 7
127.0.0.1:6379> ttl user
(integer) 3
127.0.0.1:6379> ttl user
(integer) 0
4. Hash
其实我们可以理解 hash 为 小型Redis ,Redis 在底层实现上和 Java 中的 HashMap 差不多,都是使用 数组 + 链表 的二维结构实现的。
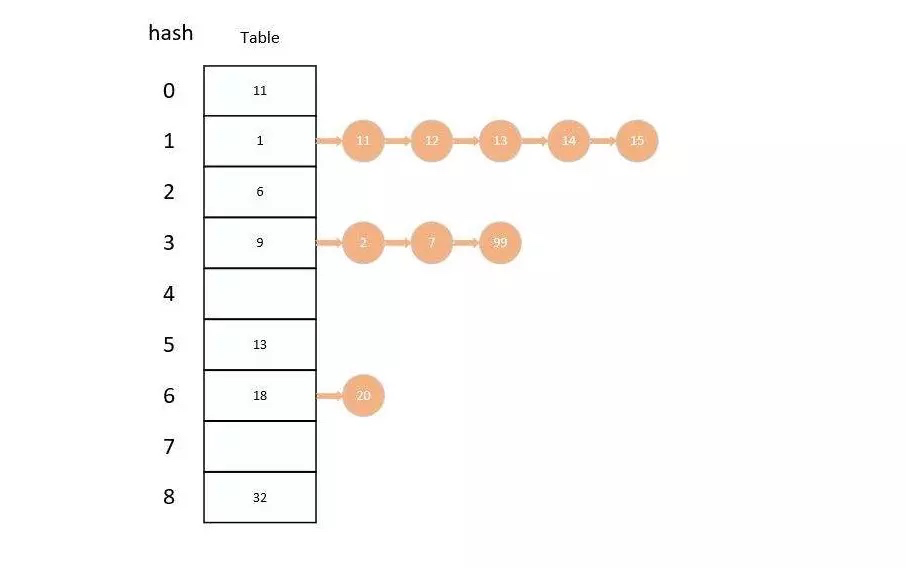
不同的是,在 Redis 中字典的值只能是字符串,而且他们 rehash 的方式不一样,在 Redis 中使用的是 渐进式rehash 。
在 rehash 的时候会保留新旧两个 hash 字典,在数据迁移的时候会将旧字典中的内容一点一点迁移到新字典中,查询的同时会查询两个 hash 字典,等数据全部迁移完成才会将新字典代替就字典。
- hset key field value 设置字典中某个key的值
- hsetnx key field value 设置字典中某个key的值(不存在的)
- hmset key field1 value1 field2 value2 ... 批量设置
- hget key field 获取字典中某个key的值
- hmget key field1 field2 批量获取
- hgetall key 获取全部
127.0.0.1:6379> hset userinfo name gerf
(integer) 1
127.0.0.1:6379> hsetnx userinfo name aaa
(integer) 0
127.0.0.1:6379> hmset userinfo age 28 email 444@qq.com
OK
127.0.0.1:6379> hget userinfo name
"gerf"
127.0.0.1:6379> hmget userinfo name age
1) "gerf"
2) "28"
127.0.0.1:6379> hgetall userinfo
1) "name"
2) "gerf"
3) "age"
4) "28"
5) "email"
6) "444@qq.com"
127.0.0.1:6379>
- hdel key field 删除某个key
- hexists key field 判断是否存在
- hlen key 获取指定key对应的字典中的存储个数
- hvals key 返回所有的value
- hkeys key 返回所有的key
127.0.0.1:6379> hkeys userinfo
1) "name"
2) "age"
3) "email"
127.0.0.1:6379> hdel userinfo email
(integer) 1
127.0.0.1:6379> hkeys userinfo
1) "name"
2) "age"
127.0.0.1:6379> hexists userinfo name
(integer) 1
127.0.0.1:6379> hlen userinfo
(integer) 2
127.0.0.1:6379> hvals userinfo
1) "gerf"
2) "28"
- hincrby key field increValue 增加某个value的值(也可以增加负数)
- hincrbyfloat key field floatValue 增加某个value的值(浮点数)
127.0.0.1:6379> hincrby userinfo age 1
(integer) 29
127.0.0.1:6379> hget userinfo age
"29"
127.0.0.1:6379> hincrbyfloat userinfo age 0.5
"29.5"
127.0.0.1:6379> hget userinfo age
"29.5"
5. List
Redis 中的列表相当于 Java 中的 LinkedList(双向链表) ,也就是底层是通过 链表 来实现的,所以对于 list 来说 插入删除操作很快,但 索引定位非常慢。

Redis 提供了许多对于 list 的操作,如出,入等操作,你可以充分利用它们来实现一个 栈 或者 队列。
- lpush key item1 item2 item3... 从左入栈
- rpush key item1 item2 item3... 从右入栈
- lpop key 从左出栈
- rpop key 从右出栈
- lindex key index 获取指定索引的元素 O(n)谨慎使用
- lrange key start end 获取指定范围的元素 O(n)谨慎使用
127.0.0.1:6379> lpush userlist aaa
(integer) 1
127.0.0.1:6379> lpush userlist bbb
(integer) 2
127.0.0.1:6379> lpush userlist ccc ddd
(integer) 4
127.0.0.1:6379> lrange userlist 0 -1
1) "ddd"
2) "ccc"
3) "bbb"
4) "aaa"
127.0.0.1:6379> rpush userlist eee
(integer) 5
127.0.0.1:6379> lrange userlist 0 -1
1) "ddd"
2) "ccc"
3) "bbb"
4) "aaa"
5) "eee"
127.0.0.1:6379> lpop userlist
"ddd"
127.0.0.1:6379> rpop userlist
"eee"
127.0.0.1:6379> lrange userlist 0 -1
1) "ccc"
2) "bbb"
3) "aaa"
127.0.0.1:6379> lindex userlist 1
"bbb"
- linsert key before|after item newitem 在指定元素的前面或者后面添加新元素
- lrem key count value 删除指定个数值为value的元素
count = 0 :删除所有值为value的元素
count > 0 :从左到右删除 count 个值为 value 的元素
count < 0 :从右到做删除 |count| 个值为 value 的元素 - ltrim key start end 保留指定范围的元素
- lset key index newValue 更新某个索引的值
127.0.0.1:6379> lrange userlist 0 -1
1) "ccc"
2) "bbb"
3) "a111"
4) "aaa"
127.0.0.1:6379> linsert userlist after aaa a222
(integer) 5
127.0.0.1:6379> lrange userlist 0 -1
1) "ccc"
2) "bbb"
3) "a111"
4) "aaa"
5) "a222"
127.0.0.1:6379> lrem userlist 0 aaa
(integer) 1
127.0.0.1:6379> lrange userlist 0 -1
1) "ccc"
2) "bbb"
3) "a111"
4) "a222"
127.0.0.1:6379> lpush userlist bbb
(integer) 5
127.0.0.1:6379> lrange userlist 0 -1
1) "bbb"
2) "ccc"
3) "bbb"
4) "a111"
5) "a222"
127.0.0.1:6379> lrem userlist 2 bbb
(integer) 2
127.0.0.1:6379> lrange userlist 0 -1
1) "ccc"
2) "a111"
3) "a222"
127.0.0.1:6379> ltrim userlist 0 1
OK
127.0.0.1:6379> lrange userlist 0 -1
1) "ccc"
2) "a111"
127.0.0.1:6379> lset userlist 0 c11
OK
127.0.0.1:6379> lrange userlist 0 -1
1) "c11"
2) "a111"
- blpop key timeout 没有则阻塞(timeout指定阻塞时间 为0代表永久)
- brpop key timeout 没有则阻塞(timeout指定阻塞时间 为0代表永久) 这两个可以用来实现消费者生产者
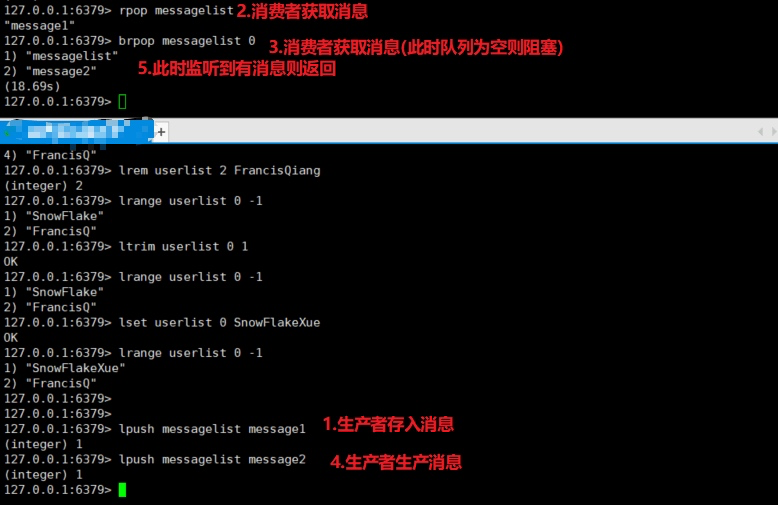
总结来说我们可以使用 左入右出或者右入左出 来实现队列,左入左出或者右入右出 来实现栈。
- lpush + lpop = Stack
- rpush + rpop = Stack**
- lpush + rpop = Queue
- rpush + lpop = Queue
- lpush/rpush + ltrim = Capped List (定长列表)
- lpush + brpop = Message Queue (消息队列)
- rpush + blpop = Message Queue (消息队列)
6. Set
Redis 中的 set 相当于 Java 中的 HashSet(无序集合),其中里面的元素不可以重复,我们可以利用它实现一些去重的功能。我们还有对几个集合进行取交集,取并集等操作,这些操作就可以获取不同用户之间的共同好友,共同爱好等等。
- sadd key value 添加元素
- sdel key value 删除某个元素
- sismember key value 判断是否是集合中的元素
- srandmember key count 随机获取指定个数的元素(不会影响集合结构)
- spop key count 从集合中随机弹出元素(会破坏结合结构)
- smembers key 获取集合所有元素 O(n)复杂度
- scard key 获取集合个数
127.0.0.1:6379> sadd userset aaa
(integer) 1
127.0.0.1:6379> sadd userset aaa
(integer) 0
127.0.0.1:6379> sadd userset nnn
(integer) 1
127.0.0.1:6379> sismember userset bbb
(integer) 0
127.0.0.1:6379> srandmember userset 1
1) "nnn"
127.0.0.1:6379> spop userset 1
1) "nnn"
127.0.0.1:6379> smembers userset
1) "aaa"
127.0.0.1:6379> scard userset
(integer) 1
- sinter set1 set2 ... 获取所有集合中的交集
- sdiff set1 set2 ... 获取所有集合中的差集
- sunion set1 set2 ... 获取所有集合中的并集
127.0.0.1:6379> sadd set1 aa bb cc dd
(integer) 4
127.0.0.1:6379> sadd set2 11 22 33 44
(integer) 4
127.0.0.1:6379> sinter set1 set2
(empty list or set)
127.0.0.1:6379> sadd set1 aa11
(integer) 1
127.0.0.1:6379> sadd set2 aa11
(integer) 1
127.0.0.1:6379> sinter set1 set2
1) "aa11"
127.0.0.1:6379> sdiff set1 set2
1) "dd"
2) "bb"
3) "cc"
4) "aa"
127.0.0.1:6379> sunion set1 set2
1) "cc"
2) "bb"
3) "aa"
4) "33"
5) "22"
6) "11"
7) "aa11"
8) "44"
9) "dd"
7. Sorted Set
Redis 中的 zset 是一个 有序集合,通过它可以实现很多有意思的功能,比如学生成绩排行榜,视频播放量排行榜等等。
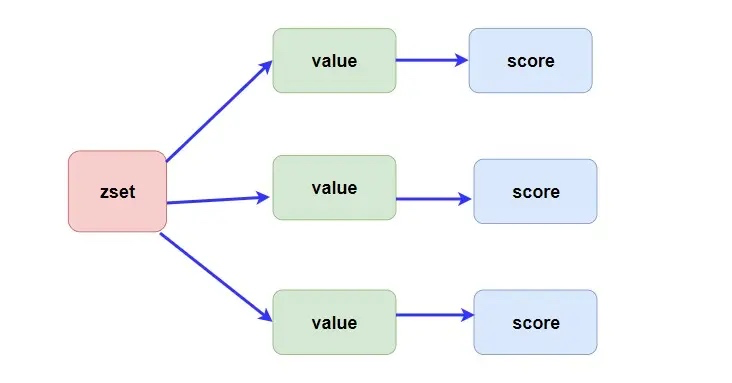
- zadd key score element 添加,score用于排序,value需要唯一,由于使用的跳表,时间复杂度为 O(logn)。
- zrem key element 删除某元素 O(1)时间复杂度
- zscore key element 获取某个元素的分数
- zincrby key incrScore element 增加某个元素的分数
- zrange key start end [withscores] 获取指定索引范围的元素 加上withscores则返回分数 O(logn + m)时间复杂度
- zrangebyscore key minScore maxScore [withscores] 获取指定分数范围的元素 加上withscores则返回分数,O(logn + m)时间复杂度
- zcard key 获取有序集合长度
127.0.0.1:6379> zadd mathtest 88 aa
(integer) 1
127.0.0.1:6379> zadd mathtest 77 bb
(integer) 1
127.0.0.1:6379> zadd mathtest 66 cc
(integer) 1
127.0.0.1:6379> zrange mathtest 0 -1
1) "cc"
2) "bb"
3) "aa"
127.0.0.1:6379> zrem mathtest bb
(integer) 1
127.0.0.1:6379> zscore mathtest aa
"88"
127.0.0.1:6379> zincrby mathtest 11 aa
"99"
127.0.0.1:6379> zrange mathtest 0 -1
1) "cc"
2) "aa"
127.0.0.1:6379> zincrby mathtest 44 bb
"44"
127.0.0.1:6379> zrange mathtest 0 -1
1) "bb"
2) "cc"
3) "aa"
127.0.0.1:6379> zrange mathtest 0 -1 withscores
1) "bb"
2) "44"
3) "cc"
4) "66"
5) "aa"
6) "99"
127.0.0.1:6379> zcard mathtest
(integer) 3
8. 排序
- sort mylist 排序
- sort mylist alpha desc limit 0 2 字母排序
- sort list by it:* desc by命令
- sort list by it:* desc get it:* get参数
- sort list by it:* desc get it:* store sorc:result sort命令之store参数:表示把sort查询的结果集保存起来
127.0.0.1:6379> lpush today-cost 30
(integer) 1
127.0.0.1:6379> lpush today-cost 1.5
(integer) 2
127.0.0.1:6379> lpush today-cost 10
(integer) 3
127.0.0.1:6379> lpush today-cost 8
(integer) 4
127.0.0.1:6379> sort today-cost
1) "1.5"
2) "8"
3) "10"
4) "30"
127.0.0.1:6379> lpush website "www.aaa.com"
(integer) 1
127.0.0.1:6379> lpush website "www.bbb.com"
(integer) 2
127.0.0.1:6379> lpush website "www.ccc.com"
(integer) 3
127.0.0.1:6379> lpush website "www.123.com"
(integer) 4
127.0.0.1:6379> sort website alpha
1) "www.123.com"
2) "www.aaa.com"
3) "www.bbb.com"
4) "www.ccc.com"
127.0.0.1:6379> sort website alpha desc limit 0 3
1) "www.ccc.com"
2) "www.bbb.com"
3) "www.aaa.com"
127.0.0.1:6379>
六、数据备份与恢复
1. Redis 持久化
Redis 提供了不同级别的持久化方式:
- RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储.
- AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大.
- 如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.
- 你也可以同时开启两种持久化方式, 在这种情况下, 当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
aof备份处理
- config set appendonly yes 开启持久化
- appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
- appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘(推荐)
- appendfsync no #让操作系统决定何时进行同步
命令:
- bgsave异步保存数据到磁盘(快照保存)
- lastsave返回上次成功保存到磁盘的unix的时间戳
- shutdown同步保存到服务器并关闭redis服务器
- bgrewriteaof文件压缩处理(命令)
// 备份
127.0.0.1:6379> save // RDB 阻塞方式备份
18951:M 10 Dec 2019 15:10:22.409 * DB saved on disk
OK
127.0.0.1:6379> bgsave // RDB 后台备份
18951:M 10 Dec 2019 15:10:32.446 * Background saving started by pid 2026
Background saving started
127.0.0.1:6379> 2026:C 10 Dec 2019 15:10:32.449 * DB saved on disk
18951:M 10 Dec 2019 15:10:32.456 * Background saving terminated with success
// 恢复
// 如果需要恢复数据,只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可
127.0.0.1:6379> CONFIG GET dir
1) "dir"
2) "/Users/gerunfeng/redis-5.0.5"
2. RDB和AOF持久化对比
RDB原理
fork和cow。fork是指redis通过创建子进程来进行RDB操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
RDB的优点
- RDB是一个非常紧凑的文件,它保存了某个时间点得数据集,非常适用于数据集的备份,比如你可以在每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集.
- RDB是一个紧凑的单一文件,很方便传送到另一个远端数据中心或者亚马逊的S3(可能加密),非常适用于灾难恢复.
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些.
RDB的缺点
- 如果你希望在redis意外停止工作(例如电源中断)的情况下丢失的数据最少的话,那么RDB不适合你.虽然你可以配置不同的save时间点(例如每隔5分钟并且对数据集有100个写的操作),是Redis要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存,万一在Redis意外宕机,你可能会丢失几分钟的数据.
- RDB 需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求.如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续1秒,AOF也需要fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度.
AOF 优点
- 使用AOF 会让你的Redis更加耐久: 你可以使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync.使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据.
- AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题.
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
- AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 缺点
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
如何选择使用哪种持久化方式?
-
一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。
-
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
-
有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 除此之外, 使用 RDB 还可以避免之前提到的 AOF 程序的 bug 。
七、安全(密码设置)
我们可以通过 redis 的配置文件设置密码参数,这样客户端连接到 redis 服务就需要密码验证,这样可以让你的 redis 服务更安全
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) ""
127.0.0.1:6379> config set requirepass 123
OK
127.0.0.1:6379> keys *
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 123
OK
127.0.0.1:6379> keys *
1) "mathtest"
2) "user1"
3) "user5"
九、客户端连接
//client kill 关闭客户端连接
//client list 列出所有的客户端
//给客户端设置一个名称
client setname myclient1
client getname
config get port
//configRewrite 对redis的配置文件进行改写
十、面试问题
1. 假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用keys指令可以扫出指定模式的key列表。
如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
Redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长
2. 缓存穿透
什么是缓存穿透?
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。下面用图片展示一下(这两张图片不是我画的,为了省事直接在网上找的,这里说明一下):
正常缓存处理流程:
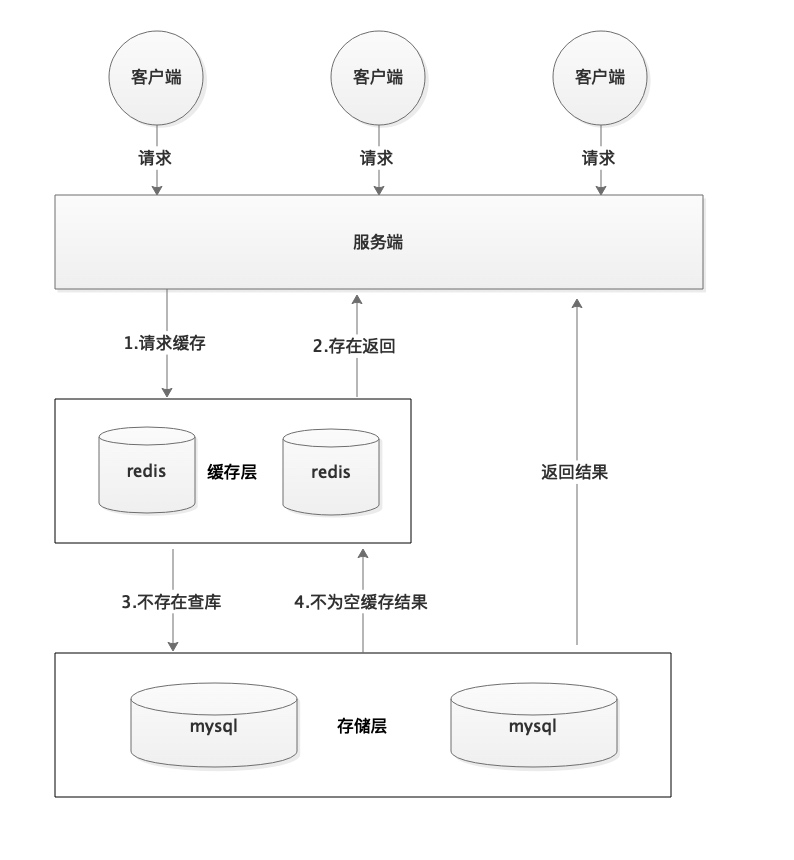
缓存穿透情况处理流程:

有哪些解决办法?
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
1)缓存无效 key : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:SET key value EX 10086。这种方式可以解决请求的 key 变化不频繁的情况,如何黑客恶意攻击,每次构建的不同的请求key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
另外,这里多说一嘴,一般情况下我们是这样设计 key 的: 表名:列名:主键名:主键值。