Logistic回归:一种最优化算法。用于分类,其实就是对分类边界线建立回归公式。啥?啥叫回归?就是用一条直线对数据点进行拟合,拟合的过程称作回归。。。。。说白了就是找一条线把数据点分开
最优化算法:梯度上升算法和改进的梯度上升算法。。。一听到改进,感觉肯定比原算法牛逼
sigmoid函数
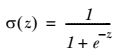 z为输入值
z为输入值
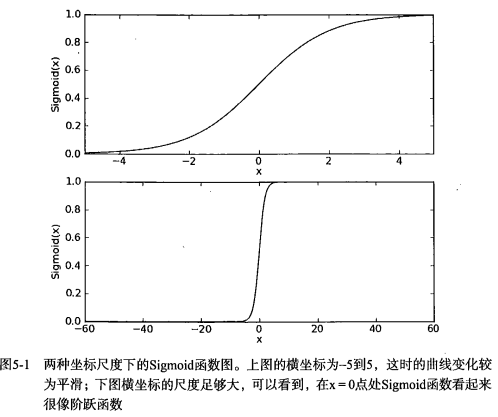
下图给出了sigmoid函数在不同坐标尺度下的两条曲线图
因此,为了实现 Logistic 回归分类器,我们可以在每个特征上都乘以一个回归系数(如下公式所示),然后把所有结果值相加,将这个总和代入 Sigmoid 函数中,进而得到一个范围在 0~1 之间的数值。任何大于 0.5 的数据被分入 1 类,小于 0.5 即被归入 0 类
Sigmoid函数的输入记为z,有下面公式得到:
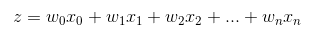

梯度上升算法
函数 f(x, y) 的梯度由下式表示: 条件是:函数f(x, y)必须要在待计算的点上有定义并且可微
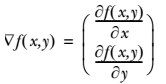
梯度上升算法的迭代公式如下:

Logistic 回归 工作原理
每个回归系数初始化为 1
重复 R 次:
计算整个数据集的梯度
使用 步长 x 梯度 更新回归系数的向量
返回回归系数
Logistic 回归 算法特点
优点: 计算代价不高,易于理解和实现。
缺点: 容易欠拟合,分类精度可能不高。
适用数据类型: 数值型和标称型数据。
1. 加载数据
def loadDataSet(file_name): """ Desc: 加载并解析数据 Args: file_name -- 文件名称,要解析的文件所在磁盘位置 Returns: dataMat -- 原始数据的特征 labelMat -- 原始数据的标签,也就是每条样本对应的类别 """ # dataMat为原始数据, labelMat为原始数据的标签 dataMat = [] labelMat = [] fr = open(file_name) for line in fr.readlines(): lineArr = line.strip().split() if len(lineArr) == 1: continue # 这里如果就一个空的元素,则跳过本次循环 # 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0 dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) labelMat.append(int(lineArr[2])) return dataMat, labelMat
2. 梯度上升算法
def sigmoid(inX): return 1.0/(1+exp(-inX)) def gradAscent(dataMatIn, classLabels): # 转化成Numpy矩阵 dataMatrix = mat(dataMatIn) # dataMatrix 是一个100*3的矩阵 labelMat = mat(classLabels).transpose() # labelMat 是一个100*1的矩阵 m, n = shape(dataMatrix) alpha = 0.001 maxCycles = 500 weights = ones((n, 1)) # 3*1 for k in range(maxCycles): h = sigmoid(dataMatrix * weights) # 100*3 * 3*1=100*1 error = (labelMat - h) # error 100*1 weights = weights + alpha * dataMatrix.transpose()* error return weights
3. 随机梯度上升算法,只使用一个样本点来更新回归系数
# 随机梯度上升算法 只使用一个样本点来更新回归系数 def stocGradAscent0(dataMatrix, classLabel): """ Args: dataMatrix--输入数据的数据特征(除去最后一列) classlables--输入数据的类别标签(最后一列数据) retrurns: weights -- 得到最佳回归系数 """ m, n = shape(dataMatrix) # m = 100, n=2 alpha = 0.01 weights = ones(n) # 初始化长度为n的数组,元素全部为1 n*1 for i in range(m): h = sigmoid(sum(dataMatrix[i] * weights)) #1*2 *2*1 是个数 # 计算真实类别与预测类别之间的差值,然后按照该差值调整回归系数 error = classLabel[i] - h # 0.01*(1*1) * (1*n) weights = weights + alpha * error * dataMatrix[i] return weights
4. 改进的随机梯度上升算法
# 改进的随机梯度算法 def stocGradAscent1(dataMatrix, classLabels, numIter=150): """ Asc: 改进版的随机梯度下降,使用随机的一个样本来更新回归系数 Args: dataMatrix -- 输入数据的数据特征(除去最后一列数据) classLabels -- 输入数据的类别标签(最后一列数据) numIter=150 -- 迭代次数 Returns: weights -- 得到的最佳回归系数 """ m, n = shape(dataMatrix) weights = ones(n) for j in range(numIter): # [0, 1, 2 .. m-1] dataIndex = list(range(m)) for i in range(m): # i和j的不断增大,导致alpha的值不断减少,但是不为0 alpha = 4 / ( 1.0 + j + i ) + 0.0001 # alpha 会随着迭代不断减小,但永远不会减小到0,因为后边还有一个常数项0.0001 # 随机产生一个 0~len()之间的一个值 # random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。 randIndex = int(random.uniform(0, len(dataIndex))) # sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn h = sigmoid(sum(dataMatrix[dataIndex[randIndex]] * weights)) error = classLabels[dataIndex[randIndex]] - h # print weights, '__h=%s' % h, '__'*20, alpha, '__'*20, error, '__'*20, dataMatrix[randIndex] weights = weights + alpha * error * dataMatrix[dataIndex[randIndex]] del(dataIndex[randIndex]) return weights
5. 画出数据集和 Logistic 回归最佳拟合直线的函数
# 可视化展示 def plotBestFit(dataArr, labelMat, weights): """ 将我们得到的数据可视化展示出来 Args: dataArr:样本数据的特征 labelMat:样本数据的类别标签,即目标变量 weights:回归系数 Returns: None """ n = shape(dataArr)[0] xcord1 = [] ycord1 = [] xcord2 = [] ycord2 = [] for i in range(n): if int(labelMat[i]) == 1: xcord1.append(dataArr[i, 1]) ycord1.append(dataArr[i, 2]) else: xcord2.append(dataArr[i, 1]) ycord2.append(dataArr[i, 2]) fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(xcord1, ycord1, s=30, c='red', marker='s') ax.scatter(xcord2, ycord2, s=30, c='green') x = arange(-3.0, 3.0, 0.1)
y = (-weights[0] - weights[1] * x) / weights[2] ax.plot(x, y) plt.xlabel('X') plt.ylabel('Y') plt.show()
6. 测试模块
def simpleTest(): dataMat, labelMat = loadDataSet('testSet.txt') dataArr = array(dataMat) weights = stocGradAscent1(dataArr, labelMat) plotBestFit(dataArr, labelMat, weights)
8. 示例
def classifyVector(inX, weights): """ Desc: 最终的分类函数,根据回归系数和特征向量来计算 Sigmoid 的值,大于0.5函数返回1,否则返回0 Args: inX -- 特征向量,features weights -- 根据梯度下降/随机梯度下降 计算得到的回归系数 Returns: 如果 prob 计算大于 0.5 函数返回 1 否则返回 0 """ prob = sigmoid(sum(inX * weights)) if prob > 0.5 : return 1.0 else : return 0.0
def colicTest(): """ Desc: 打开测试集和训练集,并对数据进行格式化处理 Args: None Returns: errorRate -- 分类错误率 """ frTrain = open('horseColicTraining.txt') frTest = open('horseColicTest.txt') trainingSet = [] trainingLabels = [] # 解析训练数据集中的数据特征和Labels # trainingSet 中存储训练数据集的特征,trainingLabels 存储训练数据集的样本对应的分类标签 for line in frTrain.readlines(): currLine = line.strip().split(' ') lineArr = [] for i in range(21): lineArr.append(float(currLine[i])) trainingSet.append(lineArr) trainingLabels.append(float(currLine[21])) # 使用 改进后的 随机梯度下降算法 求得在此数据集上的最佳回归系数 trainWeights trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 300) errorCount = 0 numTestVec = 0.0 # 读取 测试数据集 进行测试,计算分类错误的样本条数和最终的错误率 for line in frTest.readlines(): numTestVec += 1.0 currLine = line.strip().split(' ') lineArr = [] for i in range(21): lineArr.append(float(currLine[i])) if int(classifyVector(array(lineArr), trainWeights)) != int(currLine[21]): errorCount += 1 errorRate = (float(errorCount) / numTestVec) print("the error rate of this test is: %f" % errorRate) return errorRate
# 调用 colicTest() 10次并求结果的平均值 def multiTest(): numTest = 10 errorSum = 0.0 for k in range(numTest): errorSum += colicTest() print("after %d iterations the average error rate is: %f" % (numTest, errorSum / float(numTest)))
9. 所有代码
#!F:PyCharm-projects # coding : utf-8 # author : 葛壮壮 from __future__ import print_function from numpy import * import matplotlib.pyplot as plt def loadDataSet(file_name): """ Desc: 加载并解析数据 Args: file_name -- 文件名称,要解析的文件所在磁盘位置 Returns: dataMat -- 原始数据的特征 labelMat -- 原始数据的标签,也就是每条样本对应的类别 """ # dataMat为原始数据, labelMat为原始数据的标签 dataMat = [] labelMat = [] fr = open(file_name) for line in fr.readlines(): lineArr = line.strip().split() if len(lineArr) == 1: continue # 这里如果就一个空的元素,则跳过本次循环 # 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0 dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) labelMat.append(int(lineArr[2])) return dataMat, labelMat def sigmoid(inX): return 1.0/(1+exp(-inX)) def gradAscent(dataMatIn, classLabels): # 转化成Numpy矩阵 dataMatrix = mat(dataMatIn) # dataMatrix 是一个100*3的矩阵 labelMat = mat(classLabels).transpose() # labelMat 是一个100*1的矩阵 m, n = shape(dataMatrix) alpha = 0.001 maxCycles = 500 weights = ones((n, 1)) # 3*1 for k in range(maxCycles): h = sigmoid(dataMatrix * weights) # 100*3 * 3*1=100*1 error = (labelMat - h) # error 100*1 weights = weights + alpha * dataMatrix.transpose()* error return weights # 随机梯度上升算法 只使用一个样本点来更新回归系数 def stocGradAscent0(dataMatrix, classLabel): """ Args: dataMatrix--输入数据的数据特征(除去最后一列) classlables--输入数据的类别标签(最后一列数据) retrurns: weights -- 得到最佳回归系数 """ m, n = shape(dataMatrix) # m = 100, n=2 alpha = 0.01 weights = ones(n) # 初始化长度为n的数组,元素全部为1 n*1 for i in range(m): h = sigmoid(sum(dataMatrix[i] * weights)) #1*2 *2*1 是个数 # 计算真实类别与预测类别之间的差值,然后按照该差值调整回归系数 error = classLabel[i] - h # 0.01*(1*1) * (1*n) weights = weights + alpha * error * dataMatrix[i] return weights # 改进的随机梯度算法 def stocGradAscent1(dataMatrix, classLabels, numIter=150): """ Asc: 改进版的随机梯度下降,使用随机的一个样本来更新回归系数 Args: dataMatrix -- 输入数据的数据特征(除去最后一列数据) classLabels -- 输入数据的类别标签(最后一列数据) numIter=150 -- 迭代次数 Returns: weights -- 得到的最佳回归系数 """ m, n = shape(dataMatrix) weights = ones(n) for j in range(numIter): # [0, 1, 2 .. m-1] dataIndex = list(range(m)) for i in range(m): # i和j的不断增大,导致alpha的值不断减少,但是不为0 alpha = 4 / ( 1.0 + j + i ) + 0.0001 # alpha 会随着迭代不断减小,但永远不会减小到0,因为后边还有一个常数项0.0001 # 随机产生一个 0~len()之间的一个值 # random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。 randIndex = int(random.uniform(0, len(dataIndex))) # sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn h = sigmoid(sum(dataMatrix[dataIndex[randIndex]] * weights)) error = classLabels[dataIndex[randIndex]] - h # print weights, '__h=%s' % h, '__'*20, alpha, '__'*20, error, '__'*20, dataMatrix[randIndex] weights = weights + alpha * error * dataMatrix[dataIndex[randIndex]] del(dataIndex[randIndex]) return weights # 可视化展示 def plotBestFit(dataArr, labelMat, weights): """ 将我们得到的数据可视化展示出来 Args: dataArr:样本数据的特征 labelMat:样本数据的类别标签,即目标变量 weights:回归系数 Returns: None """ n = shape(dataArr)[0] xcord1 = [] ycord1 = [] xcord2 = [] ycord2 = [] for i in range(n): if int(labelMat[i]) == 1: xcord1.append(dataArr[i, 1]) ycord1.append(dataArr[i, 2]) else: xcord2.append(dataArr[i, 1]) ycord2.append(dataArr[i, 2]) fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(xcord1, ycord1, s=30, c='red', marker='s') ax.scatter(xcord2, ycord2, s=30, c='green') x = arange(-3.0, 3.0, 0.1) y = (-weights[0] - weights[1] * x) / weights[2] ax.plot(x, y) plt.xlabel('X') plt.ylabel('Y') plt.show() def simpleTest(): dataMat, labelMat = loadDataSet('testSet.txt') dataArr = array(dataMat) weights = stocGradAscent1(dataArr, labelMat) plotBestFit(dataArr, labelMat, weights) # -------------------------------------------------------------------------------- # 从疝气病症预测病马的死亡率 # 分类函数,根据回归系数和特征向量来计算 Sigmoid的值 def classifyVector(inX, weights): """ Desc: 最终的分类函数,根据回归系数和特征向量来计算 Sigmoid 的值,大于0.5函数返回1,否则返回0 Args: inX -- 特征向量,features weights -- 根据梯度下降/随机梯度下降 计算得到的回归系数 Returns: 如果 prob 计算大于 0.5 函数返回 1 否则返回 0 """ prob = sigmoid(sum(inX * weights)) if prob > 0.5 : return 1.0 else : return 0.0 # 打开测试集和训练集,并对数据进行格式化处理 def colicTest(): """ Desc: 打开测试集和训练集,并对数据进行格式化处理 Args: None Returns: errorRate -- 分类错误率 """ frTrain = open('horseColicTraining.txt') frTest = open('horseColicTest.txt') trainingSet = [] trainingLabels = [] # 解析训练数据集中的数据特征和Labels # trainingSet 中存储训练数据集的特征,trainingLabels 存储训练数据集的样本对应的分类标签 for line in frTrain.readlines(): currLine = line.strip().split(' ') lineArr = [] for i in range(21): lineArr.append(float(currLine[i])) trainingSet.append(lineArr) trainingLabels.append(float(currLine[21])) # 使用 改进后的 随机梯度下降算法 求得在此数据集上的最佳回归系数 trainWeights trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 300) errorCount = 0 numTestVec = 0.0 # 读取 测试数据集 进行测试,计算分类错误的样本条数和最终的错误率 for line in frTest.readlines(): numTestVec += 1.0 currLine = line.strip().split(' ') lineArr = [] for i in range(21): lineArr.append(float(currLine[i])) if int(classifyVector(array(lineArr), trainWeights)) != int(currLine[21]): errorCount += 1 errorRate = (float(errorCount) / numTestVec) print("the error rate of this test is: %f" % errorRate) return errorRate # 调用 colicTest() 10次并求结果的平均值 def multiTest(): numTest = 10 errorSum = 0.0 for k in range(numTest): errorSum += colicTest() print("after %d iterations the average error rate is: %f" % (numTest, errorSum / float(numTest))) if __name__ == '__main__': #simpleTest() multiTest()