SMO:序列最小优化
SMO算法:将大优化问题分解为多个小优化问题来求解
SMO算法的目标是求出一系列的alpha和b,一旦求出这些alpha,就很容易计算出权重向量w,并得到分隔超平面
工作原理:每次循环选择两个alpha进行优化处理,一旦找出一对合适的alpha,那么就增大一个同时减少一个
这里指的合适必须要符合一定的条件
a. 这两个alpha必须要在间隔边界之外
b. 这两个alpha还没有进行过区间化处理或者不在边界上
SMO 伪代码大致如下:
创建一个 alpha 向量并将其初始化为0向量
当迭代次数小于最大迭代次数时(外循环):
对数据集中的每个数据向量(内循环):
如果该数据向量可以被优化
随机选择另外一个数据向量
同时优化这两个向量
如果这两个向量都不能被优化,退出内循环
如果所有向量都没被优化,增加迭代数目,继续下一次循环
案例:对小规模数据点进行分类(代码在Jupyter上实现)
1. 准备数据
def loadDataSet(fileName): """ 对文件进行逐行解析,从而得到第行的类标签和整个特征矩阵 Args: fileName 文件名 Returns: dataMat 特征矩阵 labelMat 类标签 """ dataMat = [] labelMat = [] fr = open(fileName) for line in fr.readlines(): lineArr = line.strip().split(' ') dataMat.append([float(lineArr[0]), float(lineArr[1])]) labelMat.append(float(lineArr[2])) return dataMat, labelMat
2. 辅助函数
def selectJrand(i, m): """ 随机选择一个整数 Args: i 第一个alpha的下标 m 所有alpha的数目 Returns: j 返回一个不为i的随机数,在0~m之间的整数值 """ j = i while j == i: j = int(random.uniform(0, m)) return j
def clipAlpha(aj, H, L): """clipAlpha(调整aj的值,使aj处于 L<=aj<=H) Args: aj 目标值 H 最大值 L 最小值 Returns: aj 目标值 """ if aj > H: aj = H if L > aj: aj = L return aj
dataArr, labelArr = loadDataSet('F:/迅雷下载/machinelearninginaction/Ch06/testSet.txt') labelArr
[-1.0, -1.0, 1.0, -1.0, 1.0, 1.0, 1.0,]
可以看的出来,这里采用的类别标签是-1和1,而不是0和1
3. 简化版SMO算法
这个函数很长,可以说是机器学习实战里最长的一个函数了,不过谁让他是SVM呢,忍了!花巨大的勇气看下去吧!
说实在的,看代码之前先看看《统计学习方法》里面的公式,对照着看会好很多。
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
"""smoSimple
Args:
dataMatIn 数据集
classLabels 类别标签
C 松弛变量(常量值),允许有些数据点可以处于分隔面的错误一侧。
控制最大化间隔和保证大部分的函数间隔小于1.0这两个目标的权重。
可以通过调节该参数达到不同的结果。
toler 容错率(是指在某个体系中能减小一些因素或选择对某个系统产生不稳定的概率。)
maxIter 退出前最大的循环次数
Returns:
b 模型的常量值
alphas 拉格朗日乘子
"""
dataMatrix = mat(dataMatIn)
# 矩阵转置 和 .T 一样的功能
labelMat = mat(classLabels).transpose()
m, n = shape(dataMatrix)
# 初始化 b和alphas(alpha有点类似权重值。)
b = 0
alphas = mat(zeros((m, 1)))
# 没有任何alpha改变的情况下遍历数据的次数
iter = 0
while (iter < maxIter):
# w = calcWs(alphas, dataMatIn, classLabels)
# print("w:", w)
# 记录alpha是否已经进行优化,每次循环时设为0,然后再对整个集合顺序遍历
alphaPairsChanged = 0
for i in range(m):
# print 'alphas=', alphas
# print 'labelMat=', labelMat
# print 'multiply(alphas, labelMat)=', multiply(alphas, labelMat)
# 我们预测的类别 y = w^Tx[i]+b; 其中因为 w = Σ(1~n) a[n]*lable[n]*x[n]
fXi = float(multiply(alphas, labelMat).T*(dataMatrix*dataMatrix[i, :].T)) + b
# 预测结果与真实结果比对,计算误差Ei
Ei = fXi - float(labelMat[i])
# 约束条件 (KKT条件是解决最优化问题的时用到的一种方法。我们这里提到的最优化问题通常是指对于给定的某一函数,求其在指定作用域上的全局最小值)
# 0<=alphas[i]<=C,但由于0和C是边界值,我们无法进行优化,因为需要增加一个alphas和降低一个alphas。
# 表示发生错误的概率:labelMat[i]*Ei 如果超出了 toler, 才需要优化。至于正负号,我们考虑绝对值就对了。
'''
# 检验训练样本(xi, yi)是否满足KKT条件
yi*f(i) >= 1 and alpha = 0 (outside the boundary)
yi*f(i) == 1 and 0<alpha< C (on the boundary)
yi*f(i) <= 1 and alpha = C (between the boundary)
'''
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
# 如果满足优化的条件,我们就随机选取非i的一个点,进行优化比较
j = selectJrand(i, m)
# 预测j的结果
fXj = float(multiply(alphas, labelMat).T*(dataMatrix*dataMatrix[j, :].T)) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
# L和H用于将alphas[j]调整到0-C之间。如果L==H,就不做任何改变,直接执行continue语句
# labelMat[i] != labelMat[j] 表示异侧,就相减,否则是同侧,就相加。
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
# 如果相同,就没发优化了
if L == H:
print("L==H")
continue
# eta是alphas[j]的最优修改量,如果eta==0,需要退出for循环的当前迭代过程
# 参考《统计学习方法》李航-P125~P128<序列最小最优化算法>
eta = 2.0 * dataMatrix[i, :]*dataMatrix[j, :].T - dataMatrix[i, :]*dataMatrix[i, :].T - dataMatrix[j, :]*dataMatrix[j, :].T
if eta >= 0:
print("eta>=0")
continue
# 计算出一个新的alphas[j]值
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
# 并使用辅助函数,以及L和H对其进行调整
alphas[j] = clipAlpha(alphas[j], H, L)
# 检查alpha[j]是否只是轻微的改变,如果是的话,就退出for循环。
if (abs(alphas[j] - alphaJold) < 0.00001):
print("j not moving enough")
continue
# 然后alphas[i]和alphas[j]同样进行改变,虽然改变的大小一样,但是改变的方向正好相反
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
# 在对alpha[i], alpha[j] 进行优化之后,给这两个alpha值设置一个常数b。
# w= Σ[1~n] ai*yi*xi => b = yj- Σ[1~n] ai*yi(xi*xj)
# 所以: b1 - b = (y1-y) - Σ[1~n] yi*(a1-a)*(xi*x1)
# 为什么减2遍? 因为是 减去Σ[1~n],正好2个变量i和j,所以减2遍
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i, :]*dataMatrix[i, :].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i, :]*dataMatrix[j, :].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i, :]*dataMatrix[j, :].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j, :]*dataMatrix[j, :].T
if (0 < alphas[i]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2)/2.0
alphaPairsChanged += 1
print("iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
# 在for循环外,检查alpha值是否做了更新,如果在更新则将iter设为0后继续运行程序
# 知道更新完毕后,iter次循环无变化,才推出循环。
if (alphaPairsChanged == 0):
iter += 1
else:
iter = 0
print("iteration number: %d" % iter)
return b, alphas
测试一下实际效果:
# 惩罚因子C = 0.6 # 容错率toler = 0.001 # 退出前最大循环次数maxIter=40 b, alphas = smoSimple(dataArr, labelArr, 0.6, 0.001, 40)
iteration number: 36 j not moving enough iteration number: 37 j not moving enough iteration number: 38 j not moving enough iteration number: 39 j not moving enough iteration number: 40
对结果进行观察:
b
matrix([[-3.78600593]])
观察alpha矩阵本身,其中零元素太多,观察大于0的元素的数量
alphas[alphas>0]
matrix([[1.28007834e-01, 2.37729033e-01, 6.76418633e-05, 3.65804509e-01]])
为了得到支持向量的个数:
shape(alphas[alphas>0])
(1, 4)
为了解哪些数据点是支持向量
for i in range(100): if(alphas[i] > 0.0): print(dataArr[i], labelArr[i])
[4.658191, 3.507396] -1.0 [3.457096, -0.082216] -1.0 [2.893743, -1.643468] -1.0 [6.080573, 0.418886] 1.0
3. 基于alpha计算w值
def calcWs(alphas, dataArr, classLabels): """ 基于alpha计算w值 Args: alphas 拉格朗日乘子 dataArr feature数据集 classLabels 目标变量数据集 Returns: wc 回归系数 """ X = mat(dataArr) labelMat = mat(classLabels).transpose() m, n = shape(X) w = zeros((n, 1)) # w= Σ[1~n] ai*yi*xi for i in range(m): w += multiply(alphas[i] * labelMat[i], X[i, :].T) return w
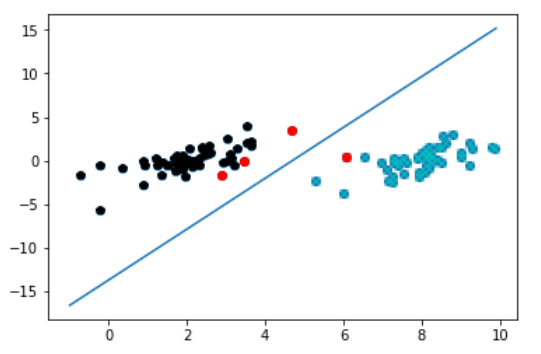
4. 对这些支持向量画圈显示的图
def plotfig_SVM(xMat, yMat, ws, b, alphas): """ 参考地址: http://blog.csdn.net/maoersong/article/details/24315633 http://www.cnblogs.com/JustForCS/p/5283489.html http://blog.csdn.net/kkxgx/article/details/6951959 """ xMat = mat(xMat) yMat = mat(yMat) # b原来是矩阵,先转为数组类型后其数组大小为(1,1),所以后面加[0],变为(1,) b = array(b)[0] fig = plt.figure() ax = fig.add_subplot(111) # 注意flatten的用法 ax.scatter(xMat[:, 0].flatten().A[0], xMat[:, 1].flatten().A[0]) # x最大值,最小值根据原数据集dataArr[:, 0]的大小而定 x = arange(-1.0, 10.0, 0.1) # 根据x.w + b = 0 得到,其式子展开为w0.x1 + w1.x2 + b = 0, x2就是y值 y = (-b-ws[0, 0]*x)/ws[1, 0] ax.plot(x, y) for i in range(shape(yMat[0, :])[1]): if yMat[0, i] > 0: ax.plot(xMat[i, 0], xMat[i, 1], 'cx') else: ax.plot(xMat[i, 0], xMat[i, 1], 'kp') # 找到支持向量,并在图中标红 for i in range(100): if alphas[i] > 0.0: ax.plot(xMat[i, 0], xMat[i, 1], 'ro') plt.show() # 画图 ws = calcWs(alphas, dataArr, labelArr) plotfig_SVM(dataArr, labelArr, ws, b, alphas)
5. 总结
对于几百个点组成的小规模数据集,简化的SMO算法是没有问题的,但是大的数据集上运行速度就会很慢。下一篇将会讨论完整版SMO算法