该内容大部分来自<<百面机器学习算法工程师>>
1.特征工程
1.1为什么需要对数值类型进行归一化?
使各个指标处于同一数值量级,消除数据之间的量纲影响。
比如分析一个人的身高和体重对健康的影响。
1.2补充知识点
结构化数据:关系数据库的一张表,每列都有清晰的定义,包含了数值型和类别型
非结构化数据:文本,图像,音频,无法使用简单的数值表示,也没有清晰的类别定义,并且每条数据的大小各不相同
1.3方法
线性归一化(Min-Max Scaling)
它对原始数据进行线性变换,使结果映射到[0,1]的范围,实现对原始数据的等比缩放。

零均值归一化(Z-Score Normalization)
它使原始数据映射到均值为0,标准差为1的正太分布
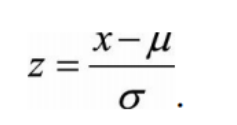
1.4注意
通过梯度下降算法通常需要归一化,包括线性回归,逻辑回归,SVM,神经网络等模型但是决策树模型不需要归一化
1.2在对数据进行预处理时,应该怎样处理类别型特征?
序号编码(Ordinal Encoding)
通常用于处理类别间具有大小关系的数据。
比如成绩可以分为低中高三个档那么高表示为3,中表示2,低表示为1
独热编码(One-hot Encoding)
处理类别间不具有大小关系的特征。
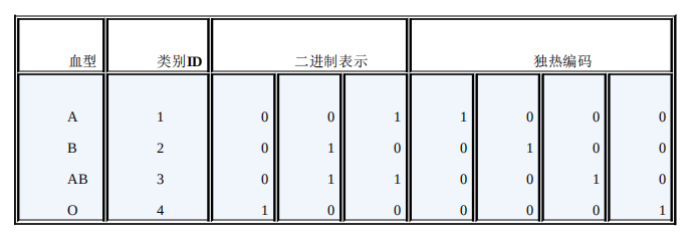
例如血型(A型血,B型血,AB型血,O型血)
A型血(1,0,0,0),B型血(0,1,0,0),AB型血(0,0,1,0),O型血(0,0,0,1)
注意对于类别取值较多的情况下
1.使用稀疏向量类节省空间
2.配合特征选择来降低维度
二进制编码(Binary Encoding)
先用序号编码给每个类别赋予一个类别ID,然后将类别ID对应的二进制
编码作为结果。
1.3什么是组合特征?如何处理高维组合特征?
为了提高复杂关系的拟合能力,在特征工程中经常会把一阶离散特征两两组合,构成高阶组合特征。


注意
当引入ID类型的特征时,问题就出现了。
解决办法矩阵分解

1.4怎么有效的找到组合特征?
一种方法是基于决策树的方法
1.5有哪些文本表示模型? 它们各有什么优缺点?
文本表示模型
词袋模型(Bag of Words)
TF-IDF
主题模型 (Topic Mode)
词嵌入模型(Word Embedding)
词袋模型(Bag of Words)和N-gram模型
就是将每篇文章看成一袋子词,忽略每个词出现的顺序。
权重计算公式
IDF如果一个单词在非常多的文章里面都出现那么它可能是一个比较通用的词汇,对于区分谋篇文章特殊语义的贡献较小,因此对权重做一定惩罚

N-gram
将文章用单次级别进行划分不好,所以可以通过词组来划分。一般会对单词进行词干抽取(Word Steamming)处理,即将不同词性的单词统一成为同一词干的形式
主题模型
从文本库中发现有代表性的主题(得到每个主题上面词的分布特效),并且能够计算
出每篇文章的主题分布
词嵌入与深度学习模型
词嵌入就是将词向量化的模型的统称,核心思想是将每个词都映射成低纬空间(通常
k=50~300维)上的一个稠密向量(Dense Vector),K维空间的每一维度都可以看作一个
隐含的主题,只不过不像主题模型中的主题那样直观。
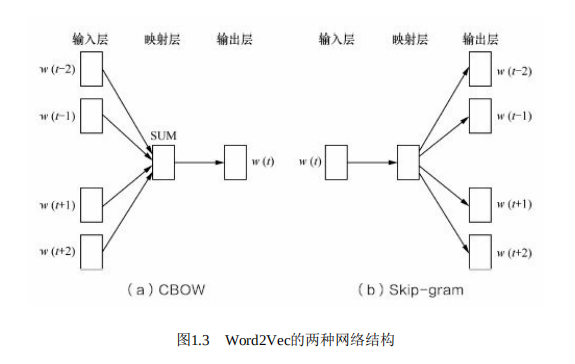
Word2Vec
CBOW SKip-gram
1.6图像数据不足时的处理方法
迁移学习(Transfer Learning),GNN,图像处理,上采样技术,数据扩充
1.7在图像分类任务中,训练数据不足会带来什么问题?如何缓解数据量不足带来的问题?
带来过拟合问题
解决方法
一是基于模型的方法,
简化模型(如将非线性模型简化为线性模型)
添加约束项以缩小假设空间(L1/L2正则项)
集成学习
Dropout超参数等
二是基于数据的方法
数据扩充(Data Augmentation)

除了直接在图像空间进行变换,还可以先对图像进行特征提取,然后
在图像的特征空间内进行变换,利用一些通用的数据扩充或上采样技术。
例如SMOTE
迁移学习进行微调(fine-tune)
