1、http://www.oschina.net/project/tag/64/spider?lang=0&os=0&sort=view&
-
搜索引擎 Nutch
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 尽管Web搜索是漫游Internet的基本要求, 但是现有web搜索引擎的数目却在下降. 并且这很有可能进一步演变成为一个公司垄断了几乎所有的web...
 更多Nutch信息
更多Nutch信息
最近更新:【每日一博】Nutch 的 url 的正则过滤机制研究 发布于 20天前
-
网站爬虫 Grub Next Generation
Grub Next Generation 是一个分布式的网页爬虫系统,包含客户端和服务器可以用来维护网页的索引。
 更多Grub Next Generation信息
更多Grub Next Generation信息最近更新:Grub Next Generation 1.0 发布 发布于 3年前
-
网站数据采集软件 网络矿工采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中唯一一款开源软件。尽管Soukey采摘开源,但并不会 影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。Soukey采摘当前提供的主要功能如下: 1. 多任务多线... 更多网络矿工采集器(原soukey采摘)信息
-
PHP的Web爬虫和搜索引擎 PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引建立一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并能够索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化 更... 更多PhpDig信息
-
网站内容采集器 Snoopy
Snoopy是一个强大的网站内容采集器(爬虫)。提供获取网页内容,提交表单等功能。 更多Snoopy信息
-
Java网页爬虫 JSpider
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下: jspider [URL] [ConfigName] URL一定要加上协议名称,如:http://,否则会报错。如果省掉ConfigName,则采用默认配置。 JSpider 的行为是由配置文件具体配置的,比如采用什么插件,结果存储方... 更多JSpider信息
-
网络爬虫程序 NWebCrawler
NWebCrawler是一款开源的C#网络爬虫程序
 更多NWebCrawler信息
更多NWebCrawler信息 -
web爬虫 Heritrix
Heritrix是一个开源,可扩展的web爬虫项目。用户可以使用它来从网上抓取想要的资源。Heritrix设计成严格按照robots.txt文件 的排除指示和META robots标签。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。 Heritrix是一个爬虫框架,其组织结...
 更多Heritrix信息
更多Heritrix信息 -
Web爬虫框架 Scrapy
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便~ 更多Scrapy信息
最近更新:使用 Scrapy 建立一个网站抓取器 发布于 6个月前
-
垂直爬虫 webmagic
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(new SimplePageProcessor("http://my.oschina.net/", "http://my.oschina.net/*/blog/*")).t...
 更多webmagic信息
更多webmagic信息
最近更新:WebMagic 0.5.2发布,Java爬虫框架 发布于 1个月前
-
OpenWebSpider
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
 更多OpenWebSpider信息
更多OpenWebSpider信息 -
Java多线程Web爬虫 Crawler4j
Crawler4j是一个开源的Java类库提供一个用于抓取Web页面的简单接口。可以利用它来构建一个多线程的Web爬虫。 示例代码: import java.util.ArrayList; import java.util.regex.Pattern; import edu.uci.ics.crawler4j.crawler.Page; import edu.uci.ics.cr... 更多Crawler4j信息
-
网页抓取/信息提取软件 MetaSeeker
网页抓取/信息提取/数据抽取软件工具包MetaSeeker (GooSeeker) V4.11.2正式发布,在线版免费下载和使用,源代码可阅读。自推出以来,深受喜爱,主要应用领域: 垂直搜索(Vertical Search):也称为专业搜索,高速、海量和精确抓取是定题网络爬虫DataScrap... 更多MetaSeeker信息
-
Java网络蜘蛛/网络爬虫 Spiderman
Spiderman - 又一个Java网络蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式架构的网络蜘蛛,它的目标是通过简单的方法就能将复杂的目标网页信息抓取并解析为自己所需要的业务数据。 主要特点 * 灵活、可扩展性强,微内核+插件式架构,Spiderman提供了多达 ... 更多Spiderman信息
-
网页爬虫 Methanol
Methanol 是一个模块化的可定制的网页爬虫软件,主要的优点是速度快。 更多Methanol信息
-
网络爬虫/网络蜘蛛 larbin
larbin是一种开源的网络爬虫/网络蜘蛛,由法国的年轻人 Sébastien Ailleret独立开发。larbin目的是能够跟踪页面的url进行扩展的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于如何parse的事情则由用户自己... 更多larbin信息
-
爬虫小新 Sinawler
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。 登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系搜集用户基本信息、微博数据、评论数据。 该应用获取的数据可作为科研、与新浪微博相关的研发等的数据支持,但请勿用于商... 更多Sinawler信息
-
【免费】死链接检查软件 Xenu
Xenu Link Sleuth 也许是你所见过的最小但功能最强大的检查网站死链接的软件了。你可以打开一个本地网页文件来检查它的链接,也可以输入任何网址来检查。它可以分别列出网站 的活链接以及死链接,连转向链接它都分析得一清二楚;支持多线程 ,可以把检查结...
 更多Xenu信息
更多Xenu信息 -
Web-Harvest
Web-Harvest是一个Java开源Web数据抽取工具。它能够收集指定的Web页面并从这些页面中提取有用的数据。Web-Harvest主要是运用了像XSLT,XQuery,正则表达式等这些技术来实现对text/xml的操作。
 更多Web-Harvest信息
更多Web-Harvest信息 -
网页抓取工具 PlayFish
-
playfish 是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工 具 应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。 这个
-
易得网络数据采集系统
本系统采用主流编程语言php和mysql数据库,您可以通过自定义采集规则,或者到我的网站下载共享的规则,针对网站或者网站群,采集您所需的数据,您 也可以向所有人共享您的采集规则哦。通过数据浏览和编辑器,编辑您所采集的数据。 本系统所有代码完全开源,...
 更多易得网络数据采集系统信息
更多易得网络数据采集系统信息 -
网页爬虫 YaCy
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是构建基于p2p Web索引网络的一个新方法.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等. 更多YaCy信息
最近更新: YaCy 1.4 发布,分布式Web搜索引擎 发布于 1年前
-
Web爬虫框架 Smart and Simple Web Crawler
Smart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接数组开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回来的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularE... 更多Smart and Simple Web Crawler信息
-
Web爬虫程序 CrawlZilla
crawlzilla 是一個幫你輕鬆建立搜尋引擎的自由軟體,有了它,你就不用依靠商業公司的收尋引擎,也不用再煩惱公司內部網站資料索引的問題 由 nutch 專案為核心,並整合更多相關套件,並開發設計安裝與管理UI,讓使用者更方便上手。 crawlzilla 除了爬取基本...
更多CrawlZilla信息
-
简易HTTP爬虫 HttpBot
HttpBot 是对 java.net.HttpURLConnection类的简单封装,可以方便的获取网页内容,并且自动管理session,自动处理301重定向等。虽 然不能像HttpClient那样强大,支持完整的Http协议,但却非常地灵活,可以满足我目前所有的相关需求。... 更多HttpBot信息
-
新闻采集器 NZBGet
NZBGet是一个新闻采集器,其中从新闻组下载的资料格式为nzb文件。它可用于单机和服务器/客户端模式。在独立模式中通过nzb文件作为参数的命令 行来下载文件。服务器和客户端都只有一个可执行文件”nzbget”。 功能和特点 控制台界面,使用纯文本,彩色文字或... 更多NZBGet信息
-
网页爬虫 Ex-Crawler
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部分,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库存储网页信息。 更多Ex-Crawler信息
-
招聘信息爬虫 JobHunter
JobHunter旨在自动地从一些大型站点来获取招聘信息,如chinahr,51job,zhaopin等等。JobHunter 搜索每个工作项目的邮件地址,自动地向这一邮件地址发送申请文本。 更多JobHunter信息
-
网页爬虫框架 hispider
HiSpider is a fast and high performance spider with high speed 严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist). 特征... 更多hispider信息
-
Perl爬虫程序 Combine
Combine 是一个用Perl语言开发的开放的可扩展的互联网资源爬虫程序。 更多Combine信息
-
web爬虫 jcrawl
jcrawl是一款小巧性能优良的的web爬虫,它可以从网页抓取各种类型的文件,基于用户定义的符号,比如email,qq. 更多jcrawl信息
-
分布式网页爬虫 Ebot
Ebot 是一个用 ErLang 语言开发的可伸缩的分布式网页爬虫,URLs 被保存在数据库中可通过 RESTful 的 HTTP 请求来查询。
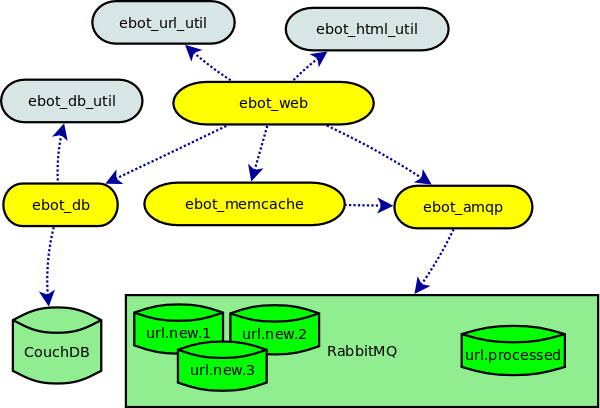 更多Ebot信息
更多Ebot信息 -
多线程web爬虫程序 spidernet
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件. 源码中TODO:标记描述了未完成功能, 希望提交你的代码....
 更多spidernet信息
更多spidernet信息 -
ItSucks
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
 更多ItSucks信息
更多ItSucks信息 -
网页搜索爬虫 BlueLeech
BlueLeech是一个开源程序,它从指定的URL开始,搜索所有可用的链接,以及链接之上的链接。它在搜索的同时可以下载遇到的链接所指向的所有的或预定义的范围的内容。 更多BlueLeech信息
-
URL监控脚本 urlwatch
urlwatch 是一个用来监控指定的URL地址的 Python 脚本,一旦指定的 URL 内容有变化时候将通过邮件方式通知到。 基本功能 配置简单,通过文本文件来指定URL,一行一个URL地址; Easily hackable (clean Python implementation) Can run as a cronjob and m... 更多urlwatch信息
最近更新: urlwatch 1.8 发布 发布于 4年前
-
Methabot
Methabot 是一个经过速度优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。 更多Methabot信息
-
web 搜索和爬虫 Leopdo
用JAVA编写的web 搜索和爬虫,包括全文和分类垂直搜索,以及分词系统 更多Leopdo信息
-
Web爬虫工具 NCrawler
NCrawler 是一个Web Crawler 工具,它可以让开发人员很轻松的发展出具有Web Crawler 能力的应用程式,并且具有可以延展的能力,让开发人员可以扩充它的功能,以支援其他类型的资源(例如PDF /Word/Excel 等档案或其他资料来源)。 NCrawler 使用多执行绪(... 更多NCrawler信息
-
Ajax爬虫和测试 Crawljax
Crawljax: java编写,开放源代码。 Crawljax 是一个 Java 的工具用于自动化的爬取和测试现在的 Ajax Web 应用。
- 收藏贴!!!