缓存由于其高并发和高性能的特性,已经在项目中被广泛使用,在缓存的使用中,通常会面临一个更新的问题,当数据源产生变化,如何去更新到数据库与缓存之中,并且尽量保证安全与性能。
你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
更新缓存的的 Design Pattern 有四种:Cache aside、Read through、Write through、Write behind caching,我们下面一一来看一下这四种 Pattern。
一、Cache Aside Pattern
最经典的 缓存+数据库读写 的模式,就是 Cache Aside Pattern。
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,先更新数据库,然后再删除缓存。
标准的Pattern,facebook就是使用这种方式,具体流程图如下:
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
命中:应用程序从cache中取数据,取到后返回。
更新:先把数据存到数据库中,成功后,再让缓存失效。
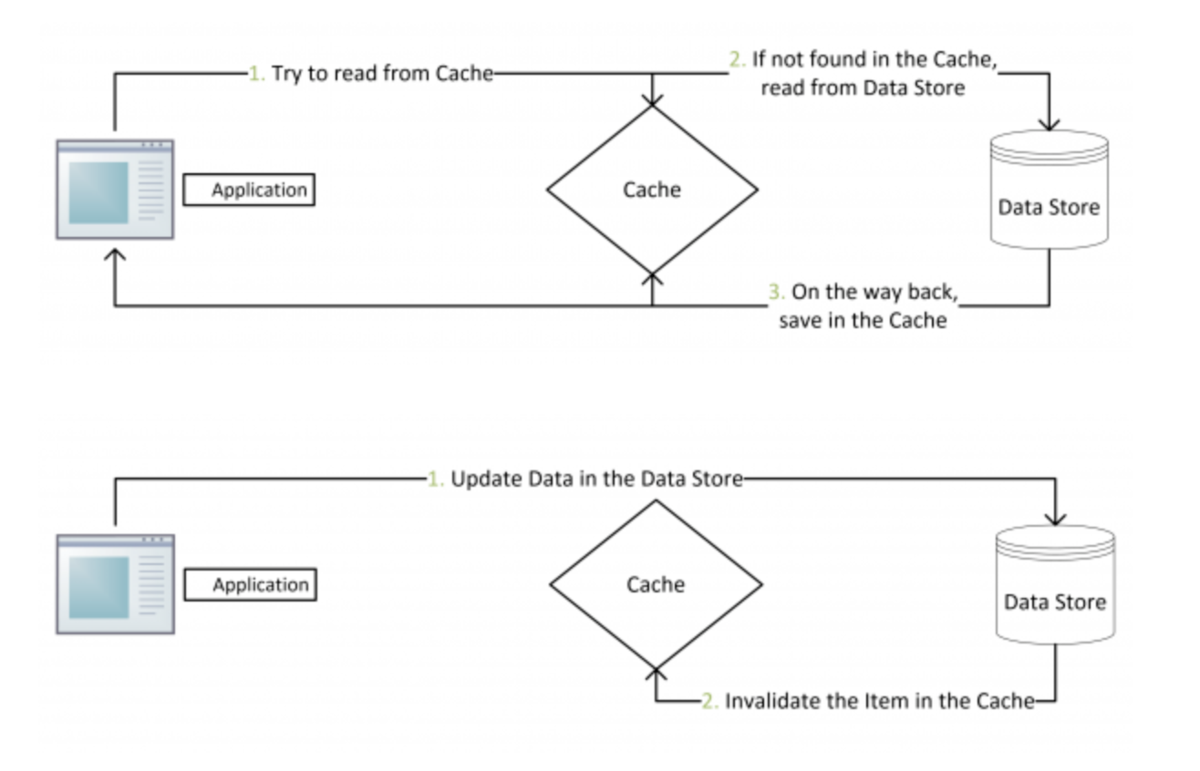
读的部分大家都很熟悉,先读 cache,如果 cache 中没有命中,去读底层数据库等存储介质,返回数据,并且设置缓存。
写的部分有一些争议,网上流传很多种做法,简单分析几种:
1、先更新缓存,再写数据库
同时有请求A和请求B进行更新操作,那么会出现
(1)线程A更新了数据库
(2)线程B更新了数据库
(3)线程B更新了缓存
(4)线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。
2、先删除缓存,再更新数据库
该方案会导致不一致的原因是。同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
(1)请求A进行写操作,删除缓存
(2)请求B查询发现缓存不存在
(3)请求B去数据库查询得到旧值
(4)请求B将旧值写入缓存
(5)请求A将新值写入数据库
这种线程安全问题需要通过延时双删等方案解决,大概的策略是:
(1)先淘汰缓存
(2)再写数据库(这两步和原来一样)
(3)休眠x秒,再次淘汰缓存
也不考虑
3、先更新数据库,再更新缓存 —— 即 Cache Aside
那么,是不是Cache Aside这个就不会有并发问题了?不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
这个case理论上会出现,不过实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
4、先更新数据库,再删除缓存 —— 为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。用到缓存才去算缓存。
其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。像 mybatis,hibernate,都有懒加载思想。查询一个部门,部门带了一个员工的 list,没有必要说每次查询部门,都里面的 1000 个员工的数据也同时查出来啊。80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了。先查部门,同时要访问里面的员工,那么这个时候只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。
二:Read/Write Through Pattern
在 Cache Aside 中,应用层需要和两个数据源打交道:缓存、数据库,这增加了应用层的复杂度,能否只和一个数据源打交道?
Read/Write Through 就是用来解决这个问题的,该模式下应用层只和缓存打交道,由缓存去操作和维护数据库。该模式会让应用层变得更加简单,同时代码也会更简洁。
1、Read Through —— Read Through 就是在查询操作中更新缓存
应用层查询数据时,当缓存未命中时(过期或LRU换出),由缓存去查询数据库,并且将结果写入缓存中,最后返回结果给应用层。
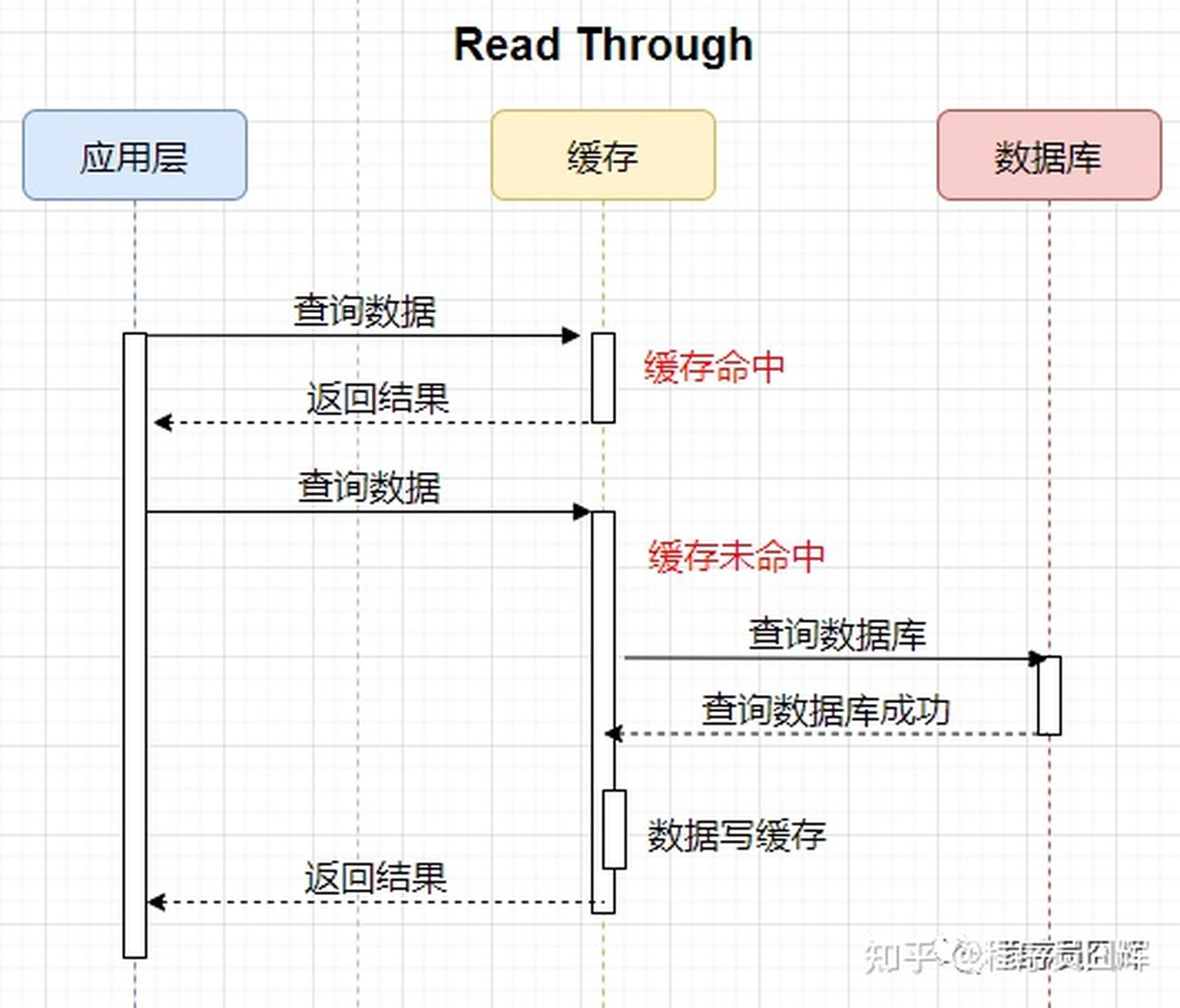
2、Write Through —— Write Through 就是双写
应用层更新数据时,由缓存去更新数据库。同时,当缓存命中时,写缓存和写数据库需要同步控制,保证同时成功。

三:Write Behind Caching Pattern
Write Behind 又称为 Write Back,从应用层的视角来看和 Write Through 类似,在该模式下应用层也是只需要和缓存一个数据源打交道,不同点在于:
Write Through 会立刻把数据同步写入数据库中,这样做的优点是操作简单,缺点是数据修改需要同时写入数据库,数据写入速度会比较慢。
Write Behind 会在一段时间之后异步的把数据批量写入数据库,这样的做的优点是:
(1)应用层操作只写缓存,应用层会觉得操作飞快无比;
(2)缓存在异步的写入数据库时,会将多个 I/O 操作合并成一个,减少 I/O 次数。
缺点是:(1)复杂度高;(2)更新后的数据还未写入数据库时,如果此时出现系统断电的情况,数据将无法找回。
Write Behind 的核心流程图如下:
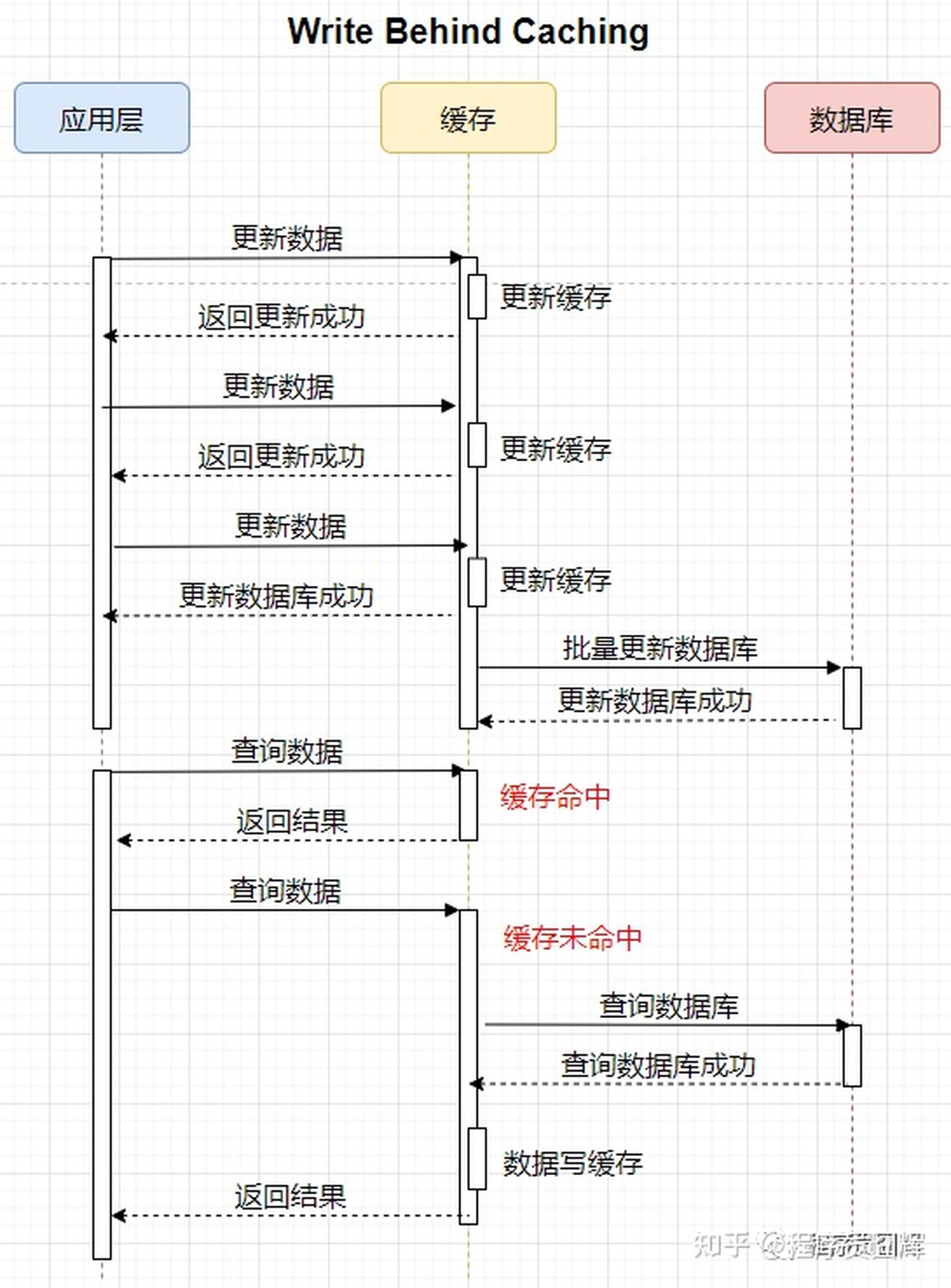
Write Back 缓存模式由于其复杂性比较高,所以在业务应用中使用的比较少,但是由于其带来的性能提升,还是有不少优秀的软件采用了该设计模式,例如:linux 中的页缓存、MySQL 中的 InnoDB 存储引擎。
linux 中的 page cache(页缓存)采用的就是 write back 机制:用户 write 时只是将数据写到 page cache,并标记为 dirty,并没有真正写到硬盘上 。内核在某个时刻会将 page cache 里的 dirty 数据 wirteback 到硬盘上。
流程图来源于文章:https://zhuanlan.zhihu.com/p/357650051