一般在我们工作中,主要会涉及到 9 种文件下载的场景,每一种场景背后都使用不同的技术,其中也有很多细节需要我们额外注意。
在浏览器端处理文件的时候,我们经常会用到 Blob 。比如图片本地预览、图片压缩、大文件分块上传及文件下载。在浏览器端文件下载的场景中,比如我们今天要讲到的 a 标签下载、showSaveFilePicker API 下载、Zip 下载 等场景中,都会使用到 Blob ,所以我们有必要在学习具体应用前,先掌握它的相关知识,这样可以帮助我们更好地了解示例代码。
一、基础知识
1、什么是 Blob
Blob(Binary Large Object)表示二进制类型的大对象。在数据库管理系统中,将二进制数据存储为一个单一个体的集合。Blob 通常是影像、声音或多媒体文件。在 JavaScript 中 Blob 类型的对象表示一个不可变、原始数据的类文件对象。 它的数据可以按文本或二进制的格式进行读取,也可以转换成 ReadableStream 用于数据操作。
Blob 对象由一个可选的字符串 type(通常是 MIME 类型)和 blobParts 组成:
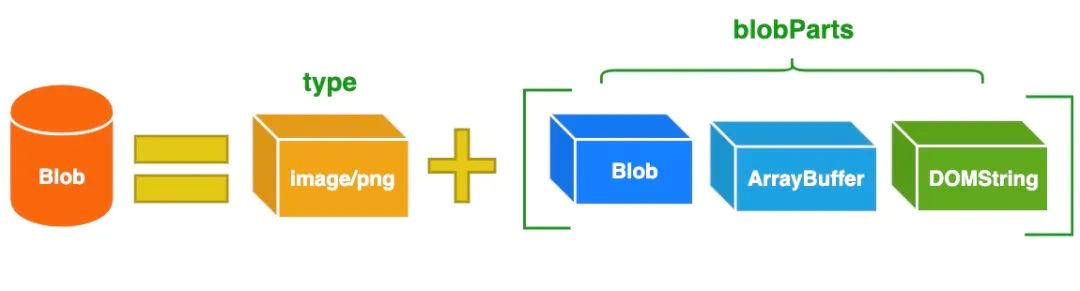
在 JavaScript 中你可以通过 Blob 的构造函数来创建 Blob 对象,Blob 构造函数的语法如下:
const aBlob = new Blob(blobParts, options);
相关的参数说明如下:
(1)blobParts:它是一个由 ArrayBuffer,ArrayBufferView,Blob,DOMString 等对象构成的数组。DOMStrings 会被编码为 UTF-8。
(2)options:一个可选的对象,包含以下两个属性:
- type —— 默认值为
"",它代表了将会被放入到 blob 中的数组内容的 MIME 类型。 - endings —— 默认值为
"transparent",用于指定包含行结束符"native",代表行结束符会被更改为适合宿主操作系统文件系统的换行符,或者"transparent",代表会保持 blob 中保存的结束符不变。
2、了解 Blob URL
Blob URL/Object URL 是一种伪协议,允许 Blob 和 File 对象用作图像、下载二进制数据链接等的 URL 源。在浏览器中,我们使用 URL.createObjectURL 方法来创建 Blob URL,该方法接收一个 Blob 对象,并为其创建一个唯一的 URL,其形式为 blob:<origin>/<uuid>,对应的示例如下:blob:http://localhost:3000/53acc2b6-f47b-450f-a390-bf0665e04e59
浏览器内部为每个通过 URL.createObjectURL 生成的 URL 存储了一个URL → Blob 映射。因此,此类 URL 较短,但可以访问 Blob。生成的 URL 仅在当前文档打开的状态下才有效。它允许引用 <img>、<a> 中的 Blob,但如果你访问的 Blob URL 不再存在,则会从浏览器中收到 404 错误。
上述的 Blob URL 看似很不错,但实际上它也有副作用。 虽然存储了 URL → Blob 的映射,但 Blob 本身仍驻留在内存中,浏览器无法释放它。映射在文档卸载时自动清除,因此 Blob 对象随后被释放。但是,如果应用程序寿命很长,那么 Blob 在短时间内将无法被浏览器释放。因此,如果你创建一个 Blob URL,即使不再需要该 Blob,它也会存在内存中。
针对这个问题,你可以调用 URL.revokeObjectURL(url) 方法,从内部映射中删除引用,从而允许删除 Blob(如果没有其他引用),并释放内存。
现在你已经了解了 Blob 和 Blob URL,下面我们开始介绍客户端文件下载的场景。随着 Web 技术的不断发展,浏览器的功能也越来越强大。这些年出现了很多在线 Web 设计工具,比如在线 PS、在线海报设计器或在线自定义表单设计器等。这些 Web 设计器允许用户在完成设计之后,把生成的文件保存到本地,其中有一部分设计器就是利用浏览器提供的 Web API 来实现客户端文件下载。
二、a 标签下载
需求:将 3 张图片合成为 1 张图片然后下载。整体的操作流程相对简单:图片合成 和 图片下载 。
1、图片合成
图片合成的功能可以直接使用 Github 上 merge-images 这个第三方库来实现。利用该库提供的 mergeImages(images, [options]) 方法,我们可以轻松地实现图片合成的功能。调用该方法后,会返回一个 Promise 对象,当异步操作完成后,合成的图片会以 Data URLs 的格式返回。
const mergePicEle = document.querySelector("#mergedPic");
const images = ["/body.png", "/eyes.png", "/mouth.png"].map(
(path) => "../images" + path
);
async function merge() {
let imgDataUrl = await mergeImages(images);
mergePicEle.src = imgDataUrl;
}
2、图片下载
图片下载的功能是借助 dataUrlToBlob 和 saveFile 这两个函数来实现。它们分别用于实现 Data URLs => Blob 的转换和文件的保存,具体的代码如下所示:
function dataUrlToBlob(base64, mimeType) {
let bytes = window.atob(base64.split(",")[1]);
let ab = new ArrayBuffer(bytes.length);
let ia = new Uint8Array(ab);
for (let i = 0; i < bytes.length; i++) {
ia[i] = bytes.charCodeAt(i);
}
return new Blob([ab], { type: mimeType });
}
// 保存文件
function saveFile(blob, filename) {
const a = document.createElement("a");
a.download = filename;
a.href = URL.createObjectURL(blob);
a.click();
URL.revokeObjectURL(a.href)
}
当设置好 a 元素的 download 属性之后,我们会调用 URL.createObjectURL 方法来创建 Object URL,并把返回的 URL 赋值给 a 元素的 href属性。接着通过调用 a 元素的 click 方法来触发文件的下载操作,最后还会调用一次 URL.revokeObjectURL 方法,从内部映射中删除引用,从而允许删除 Blob(如果没有其他引用),并释放内存。
关于 a 标签下载 的内容就介绍到这,下面我们来介绍如何使用新的 Web API —— showSaveFilePicker 实现文件下载。
三、showSaveFilePicker API 下载
showSaveFilePicker API 是 Window 接口中定义的方法,调用该方法后会显示允许用户选择保存路径的文件选择器。该方法如下所示:
let FileSystemFileHandle = Window.showSaveFilePicker(options);
showSaveFilePicker 方法支持一个对象类型的可选参数,可包含以下属性:
(1)excludeAcceptAllOption:布尔类型,默认值为 false。
默认情况下,选择器应包含一个不应用任何文件类型过滤器的选项(由下面的types 选项启用)。将此选项设置为 true 意味着 types 选项不可用。
(2)types:数组类型,表示允许保存的文件类型列表。数组中的每一项是包含以下属性的配置对象:
description(可选):用于描述允许保存文件类型类别。accept:是一个对象,该对象的key是 MIME 类型,值是文件扩展名列表。
调用 showSaveFilePicker 方法之后,会返回一个 FileSystemFileHandle 对象。有了该对象,你就可以调用该对象上的方法来操作文件。比如调用该对象上的 createWritable 方法之后,就会返回 FileSystemWritableFileStream 对象,就可以把数据写入到文件中。具体的使用方式如下所示:
async function saveFile(blob, filename) {
try {
const handle = await window.showSaveFilePicker({
suggestedName: filename,
types: [
{
description: "PNG file",
accept: {
"image/png": [".png"],
},
},
{
description: "Jpeg file",
accept: {
"image/jpeg": [".jpeg"],
},
},
],
});
const writable = await handle.createWritable();
await writable.write(blob);
await writable.close();
return handle;
} catch (err) {
console.error(err.name, err.message);
}
}
function download() {
if (!imgDataUrl) {
alert("请先合成图片");
return;
}
const imgBlob = dataUrlToBlob(imgDataUrl, "image/png");
saveFile(imgBlob, "face.png");
}
当你使用以上更新后的 saveFile 函数,来保存已合成的图片时,会显示以下保存文件选择器:
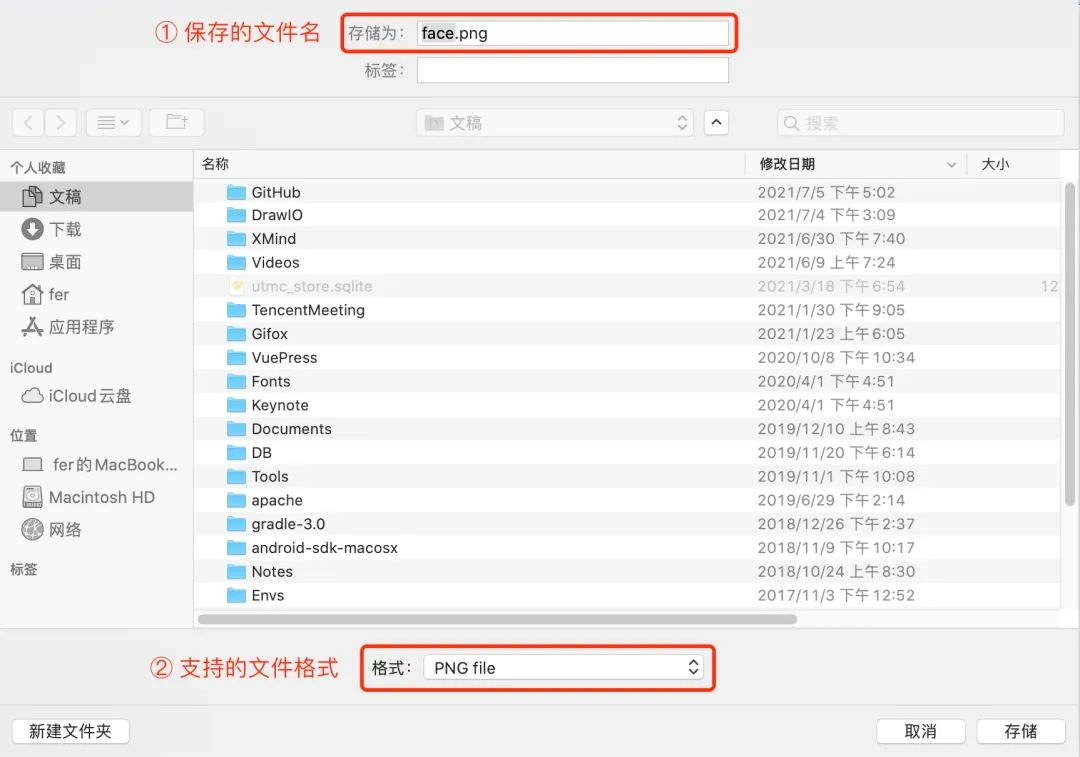
由上图可知,相比 a 标签下载 的方式,showSaveFilePicker API 允许你选择文件的下载目录、选择文件的保存格式和更改存储的文件名称。看到这里是不是觉得 showSaveFilePicker API 功能挺强大的,不过可惜的是该 API 目前的兼容性还不是很好。
其实 showSaveFilePicker 是 File System Access API 中定义的方法,除了 showSaveFilePicker 之外,还有 showOpenFilePicker 和 showDirectoryPicker 等方法。如果你想在实际项目中使用这些 API 的话,可以考虑使用 GoogleChromeLabs 开源的 browser-fs-access 这个库,该库可以让你在支持平台上更方便地使用 File System Access API,对于不支持的平台会自动降级使用 <input type="file"> 和 <a download> 的方式。
可能大家对 browser-fs-access 这个库会比较陌生,但是如果换成是 FileSaver.js 这个库的话,应该就比较熟悉了。接下来,我们来介绍如何利用 FileSaver.js 这个库实现客户端文件下载。
四、FileSaver 下载
FileSaver.js 是在客户端保存文件的解决方案,非常适合在客户端上生成文件的 Web 应用程序。它是 HTML5 版本的 saveAs() FileSaver 实现,支持大多数主流的浏览器。在引入 FileSaver.js 这个库之后,我们就可以使用它提供的 saveAs 方法来保存文件。该方法对应的签名如下所示:
FileSaver saveAs(
Blob/File/Url,
optional DOMString filename,
optional Object { autoBom }
)
saveAs 方法支持 3 个参数,第 1 个参数表示它支持 Blob/File/Url 三种类型,第 2 个参数表示文件名(可选),而第 3 个参数表示配置对象(可选)。如果你需要 FlieSaver.js 自动提供 Unicode 文本编码提示(参考:字节顺序标记),则需要设置 { autoBom: true}。
了解完 saveAs 方法之后,我们来举 3 个具体的使用示例:
1、保存文本
let blob = new Blob(["大家好,我是***"], { type: "text/plain;charset=utf-8" });
saveAs(blob, "hello.txt");
2、保存线上资源
saveAs("https://httpbin.org/image", "image.jpg");
如果下载的 URL 地址与当前站点是同域的,则将使用 a[download] 方式下载。否则,会先使用 同步的 HEAD 请求 来判断是否支持 CORS 机制,若支持的话,将进行数据下载并使用 Blob URL 实现文件下载。如果不支持 CORS 机制的话,将会尝试使用 a[download] 方式下载。
3、保存 canvas 画布内容
let canvas = document.getElementById("my-canvas");
canvas.toBlob(function(blob) {
saveAs(blob, "abao.png");
});
需要注意的是 canvas.toBlob() 方法并非在所有浏览器中都可用,对于这个问题,你可以考虑使用 canvas-toBlob.js 来解决兼容性问题。
介绍完 saveAs 方法的使用示例之后,我们来更新前面示例中的 download 方法:
function download() {
if (!imgDataUrl) {
alert("请先合成图片");
return;
}
const imgBlob = dataUrlToBlob(imgDataUrl, "image/png");
saveAs(imgBlob, "face.png");
}
很明显,使用 saveAs 方法之后,下载已合成的图片就很简单了。如果你对 FileSaver.js 的工作原理感兴趣的话,可以阅读 聊一聊 15.5K 的 FileSaver,是如何工作的? 这篇文章。前面介绍的场景都是直接下载单个文件,其实我们也可以在客户端同时下载多个文件,然后把已下载的文件压缩成 Zip 包并下载到本地。
五、Zip 下载
利用 JSZip 这个库提供的 API,把待上传目录下的所有文件压缩成 ZIP 文件,然后再把生成的 ZIP 文件上传到服务器。同样利用 JSZip 这个库,我们可以实现在客户端同时下载多个文件,然后把已下载的文件压缩成 Zip 包,并下载到本地的功能。
const images = ["body.png", "eyes.png", "mouth.png"];
const imageUrls = images.map((name) => "../images/" + name);
async function download() {
let zip = new JSZip();
Promise.all(imageUrls.map(getFileContent)).then((contents) => {
contents.forEach((content, i) => {
zip.file(images[i], content);
});
zip.generateAsync({ type: "blob" }).then(function (blob) {
saveAs(blob, "material.zip");
});
});
}
// 从指定的url上下载文件内容
function getFileContent(fileUrl) {
return new JSZip.external.Promise(function (resolve, reject) {
// 调用jszip-utils库提供的getBinaryContent方法获取文件内容
JSZipUtils.getBinaryContent(fileUrl, function (err, data) {
if (err) {
reject(err);
} else {
resolve(data);
}
});
});
}
在以上代码中,当用户点击 打包下载 按钮时,就会调用 download 函数。在该函数内部,会先调用 JSZip 构造函数创建 JSZip 对象,然后使用 Promise.all 函数来确保所有的文件都下载完成后,再调用 file(name, data [,options]) 方法,把已下载的文件添加到前面创建的JSZip 对象中。最后通过 zip.generateAsync 函数来生成 Zip 文件并使用 FileSaver.js 提供的 saveAs 方法保存 Zip 文件。
六、附件形式下载
在服务端下载的场景中,附件形式下载是一种比较常见的场景。在该场景下,我们通过设置 Content-Disposition 响应头来指示响应的内容以何种形式展示,是以内联(inline)的形式,还是以附件(attachment)的形式下载并保存到本地。
Content-Disposition: inline
Content-Disposition: attachment
Content-Disposition: attachment; filename="mouth.png"
而在 HTTP 表单的场景下, Content-Disposition 也可以作为multipart body 中的消息头:
Content-Disposition: form-data
Content-Disposition: form-data; name="fieldName"
Content-Disposition: form-data; name="fieldName"; filename="filename.jpg"
第 1 个参数总是固定不变的 form-data;附加的参数不区分大小写,并且拥有参数值,参数名与参数值用等号(=)连接,参数值用双引号括起来。参数之间用分号(;)分隔。
了解完 Content-Disposition 的作用之后,我们来看一下如何实现以附件形式下载的功能。Koa 是一个简单易用的 Web 框架,它的特点是优雅、简洁、轻量、自由度高。所以我们选择它来搭建文件服务,并使用 @koa/router 中间件来处理路由:
// attachment/file-server.js
const fs = require("fs");
const path = require("path");
const Koa = require("koa");
const Router = require("@koa/router");
const app = new Koa();
const router = new Router();
const PORT = 3000;
const STATIC_PATH = path.join(__dirname, "./static/");
// http://localhost:3000/file?filename=mouth.png
router.get("/file", async (ctx, next) => {
const { filename } = ctx.query;
const filePath = STATIC_PATH + filename;
const fStats = fs.statSync(filePath);
ctx.set({
"Content-Type": "application/octet-stream",
"Content-Disposition": `attachment; filename=${filename}`,
"Content-Length": fStats.size,
});
ctx.body = fs.createReadStream(filePath);
});
// 注册中间件
app.use(async (ctx, next) => {
try {
await next();
} catch (error) {
// ENOENT(无此文件或目录):通常是由文件操作引起的,这表明在给定的路径上无法找到任何文件或目录
ctx.status = error.code === "ENOENT" ? 404 : 500;
ctx.body = error.code === "ENOENT" ? "文件不存在" : "服务器开小差";
}
});
app.use(router.routes()).use(router.allowedMethods());
app.listen(PORT, () => {
console.log(`应用已经启动:http://localhost:${PORT}/`);
});
以上的代码被保存在 attachment 目录下的 file-server.js 文件中,该目录下还有一个 static 子目录用于存放静态资源。目前 static 目录下包含以下 3 个 png 文件。
├── file-server.js
└── static
├── body.png
├── eyes.png
└── mouth.png
当你运行 node file-server.js 命令成功启动文件服务器之后,就可以通过正确的 URL 地址来下载 static 目录下的文件。比如在浏览器中打开 http://localhost:3000/file?filename=mouth.png 这个地址,你就会开始下载 mouth.png 文件。而如果指定的文件不存在的话,就会返回文件不存在。
在编写 HTML 网页时,对于一些简单图片,通常会选择将图片内容直接内嵌在网页中,从而减少不必要的网络请求,但是图片数据是二进制数据,该怎么嵌入呢?绝大多数现代浏览器都支持一种名为 Data URLs 的特性,允许使用 Base64 对图片或其他文件的二进制数据进行编码,将其作为文本字符串嵌入网页中。所以文件也可以通过 Base64 的格式进行传输,接下来我们将介绍如何下载 Base64 格式的图片。
七、base64 格式下载
因为是 base64 格式的图片,所以在调用 FileSaver 提供的 saveAs 方法前,我们需要将 base64 字符串转换成 blob 对象,该转换是通过以下的 base64ToBlob 函数来完成,该函数的具体实现如下所示:
function base64ToBlob(base64, mimeType) {
let bytes = window.atob(base64);
let ab = new ArrayBuffer(bytes.length);
let ia = new Uint8Array(ab);
for (let i = 0; i < bytes.length; i++) {
ia[i] = bytes.charCodeAt(i);
}
return new Blob([ab], { type: mimeType });
}
八、chunked 下载
分块传输编码主要应用于如下场景,即要传输大量的数据,但是在请求在没有被处理完之前响应的长度是无法获得的。例如,当需要用从数据库中查询获得的数据生成一个大的 HTML 表格的时候,或者需要传输大量的图片的时候。
要使用分块传输编码,则需要在响应头配置 Transfer-Encoding 字段,并设置它的值为 chunked 或 gzip, chunked:
Transfer-Encoding: chunked
Transfer-Encoding: gzip, chunked
响应头 Transfer-Encoding 字段的值为 chunked,表示数据以一系列分块的形式进行发送。需要注意的是 Transfer-Encoding 和 Content-Length 这两个字段是互斥的,也就是说响应报文中这两个字段不能同时出现。下面我们来看一下分块传输的编码规则:
- 每个分块包含分块长度和数据块两个部分;
- 分块长度使用 16 进制数字表示,以
- 数据块紧跟在分块长度后面,也使用
- 终止块是一个常规的分块,表示块的结束。不同之处在于其长度为 0,即
0。
了解完分块传输的编码规则,我们来看如何利用分块传输编码实现文件下载。
const chunkedUrl = "http://localhost:3000/file?filename=file.txt";
function download() {
return fetch(chunkedUrl)
.then(processChunkedResponse)
.then(onChunkedResponseComplete)
.catch(onChunkedResponseError);
}
function processChunkedResponse(response) {
let text = "";
let reader = response.body.getReader();
let decoder = new TextDecoder();
return readChunk();
function readChunk() {
return reader.read().then(appendChunks);
}
function appendChunks(result) {
let chunk = decoder.decode(result.value || new Uint8Array(), {
stream: !result.done,
});
console.log("已接收到的数据:", chunk);
console.log("本次已成功接收", chunk.length, "bytes");
text += chunk;
console.log("目前为止共接收", text.length, "bytes
");
if (result.done) {
return text;
} else {
return readChunk();
}
}
}
function onChunkedResponseComplete(result) {
let blob = new Blob([result], {
type: "text/plain;charset=utf-8",
});
saveAs(blob, "hello.txt");
}
function onChunkedResponseError(err) {
console.error(err);
}
当用户点击下载按钮时,就会调用以上代码中的 download 函数。在该函数内部,我们会使用 Fetch API 来执行下载操作。因为服务端的数据是以一系列分块的形式进行发送,所以在浏览器端我们是通过流的形式进行接收。即通过 response.body 获取可读的 ReadableStream,然后用 ReadableStream.getReader() 创建一个读取器,最后调用 reader.read 方法来读取已返回的分块数据。
因为 file.txt 文件的内容是普通文本,且 result.value 的值是 Uint8Array 类型的数据,所以在处理返回的分块数据时,我们使用了 TextDecoder 文本解码器。一个解码器只支持一种特定文本编码,例如utf-8、iso-8859-2、koi8、cp1261,gbk 等等。

如果收到的分块非 终止块,result.done 的值是 false,则会继续调用 readChunk 方法来读取分块数据。而当接收到 终止块 之后,表示分块数据已传输完成。此时,result.done 属性就会返回 true。从而会自动调用 onChunkedResponseComplete 函数,在该函数内部,我们以解码后的文本作为参数来创建 Blob 对象。之后,继续使用 FileSaver 库提供的 saveAs 方法实现文件下载。
这里我们用 Wireshark 网络包分析工具,抓了个数据包。具体如下图所示:
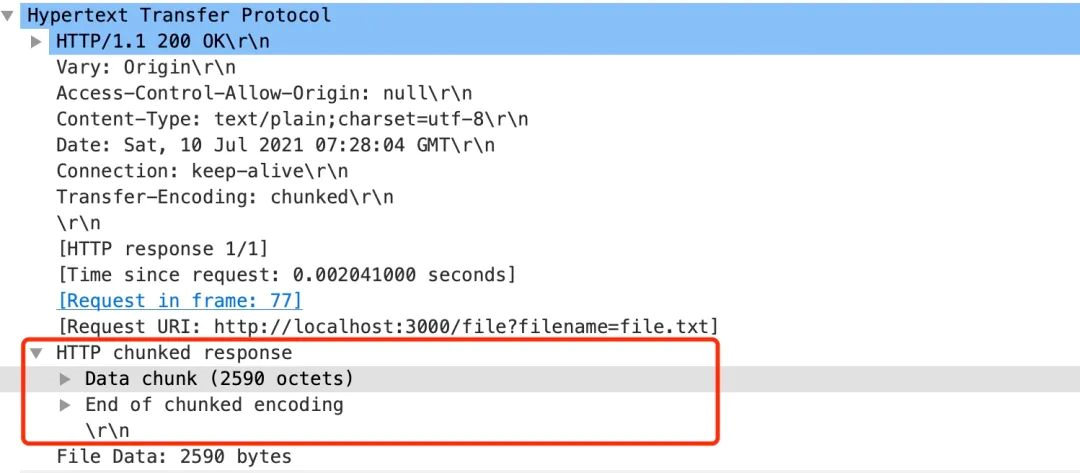
从图中我们可以清楚地看到在 HTTP chunked response 下面包含了Data chunk(数据块) 和 End of chunked encoding(终止块)。
现在我们已经知道可以利用分块传输编码(Transfer-Encoding)实现数据的分块传输,那么有没有办法获取指定范围内的文件数据呢?对于这个问题,我们可以利用 HTTP 协议的范围请求。接下来,我们将介绍如何利用 HTTP 范围请求来下载指定范围的数据。
九、范围下载
HTTP 协议范围请求允许服务器只发送 HTTP 消息的一部分到客户端。范围请求在传送大的媒体文件,或者与文件下载的断点续传功能搭配使用时非常有用。如果在响应中存在 Accept-Ranges 首部(并且它的值不为 “none”),那么表示该服务器支持范围请求。
在一个 Range 首部中,可以一次性请求多个部分,服务器会以 multipart 文件的形式将其返回。如果服务器返回的是范围响应,需要使用 206 Partial Content 状态码。假如所请求的范围不合法,那么服务器会返回 416 Range Not Satisfiable 状态码,表示客户端错误。服务器允许忽略 Range 首部,从而返回整个文件,状态码用 200 。
// Range 语法:
Range: <unit>=<range-start>-
Range: <unit>=<range-start>-<range-end>
Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>
Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>, <range-start>-<range-end>
// unit:范围请求所采用的单位,通常是字节(bytes)。
// <range-start>:一个整数,表示在特定单位下,范围的起始值。
// <range-end>:一个整数,表示在特定单位下,范围的结束值。这个值是可选的,如果不存在,表示此范围一直延伸到文档结束
// 单一范围
$ curl http://i.imgur.com/z4d4kWk.jpg -i -H "Range: bytes=0-1023"
// 多重范围
$ curl http://www.example.com -i -H "Range: bytes=0-50, 100-150"
了解完 Range 语法之后,我们来看一下实际的使用示例:
async function download() {
try {
let rangeContent = await getBinaryContent(
"http://localhost:3000/file.txt",
0, 100, "text"
);
const blob = new Blob([rangeContent], {
type: "text/plain;charset=utf-8",
});
saveAs(blob, "hello.txt");
} catch (error) {
console.error(error);
}
}
function getBinaryContent(url, start, end, responseType = "arraybuffer") {
return new Promise((resolve, reject) => {
try {
let xhr = new XMLHttpRequest();
xhr.open("GET", url, true);
xhr.setRequestHeader("range", `bytes=${start}-${end}`);
xhr.responseType = responseType;
xhr.onload = function () {
resolve(xhr.response);
};
xhr.send();
} catch (err) {
reject(new Error(err));
}
});
}
当用户点击下载按钮时,就会调用 download 函数。在该函数内部会通过调用 getBinaryContent 函数来发起范围请求。对应的 HTTP 请求报文如下所示:
GET /file.txt HTTP/1.1
Host: localhost:3000
Connection: keep-alive
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36
Accept: */*
Accept-Encoding: identity
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,id;q=0.7
Range: bytes=0-100
而当服务器接收到该范围请求之后,会返回对应的 HTTP 响应报文:
HTTP/1.1 206 Partial Content
Vary: Origin
Access-Control-Allow-Origin: null
Accept-Ranges: bytes
Last-Modified: Fri, 09 Jul 2021 00:17:00 GMT
Cache-Control: max-age=0
Content-Type: text/plain; charset=utf-8
Date: Sat, 10 Jul 2021 02:19:39 GMT
Connection: keep-alive
Content-Range: bytes 0-100/2590
Content-Length: 101
从以上的 HTTP 响应报文中,我们见到了前面介绍的 206 状态码和Accept-Ranges 首部。此外,通过 Content-Range 首部,我们就知道了文件的总大小。在成功获取到范围请求的响应体之后,我们就可以使用返回的内容作为参数,调用 Blob 构造函数创建对应的 Blob 对象,进而使用 FileSaver 库提供的 saveAs 方法来下载文件了。
十、大文件分块下载
我们经常使用大文件分片上传的解决方案:在上传大文件时,为了提高上传的效率,我们一般会使用 Blob.slice 方法对大文件按照指定的大小进行切割,然后在进行并行分块上传,等所有分块都成功上传后,再通知服务端进行分块合并。
那么对大文件下载来说,我们能否采用类似的思想呢?其实在服务端支持 Range 请求首部的条件下,我们也是可以实现大文件分块下载的功能,具体处理方案如下图所示:
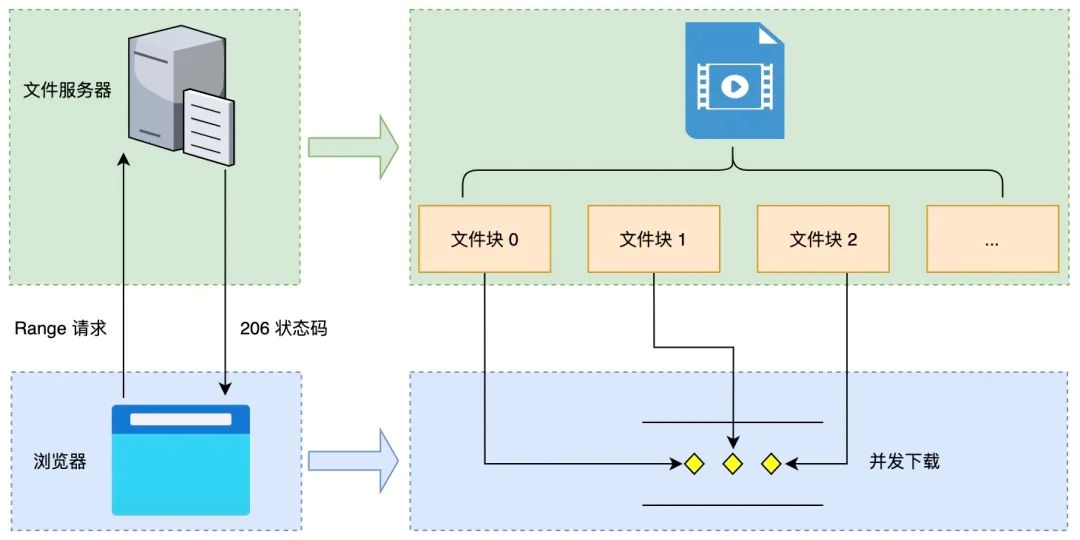
大文件并发下载的完整流程:
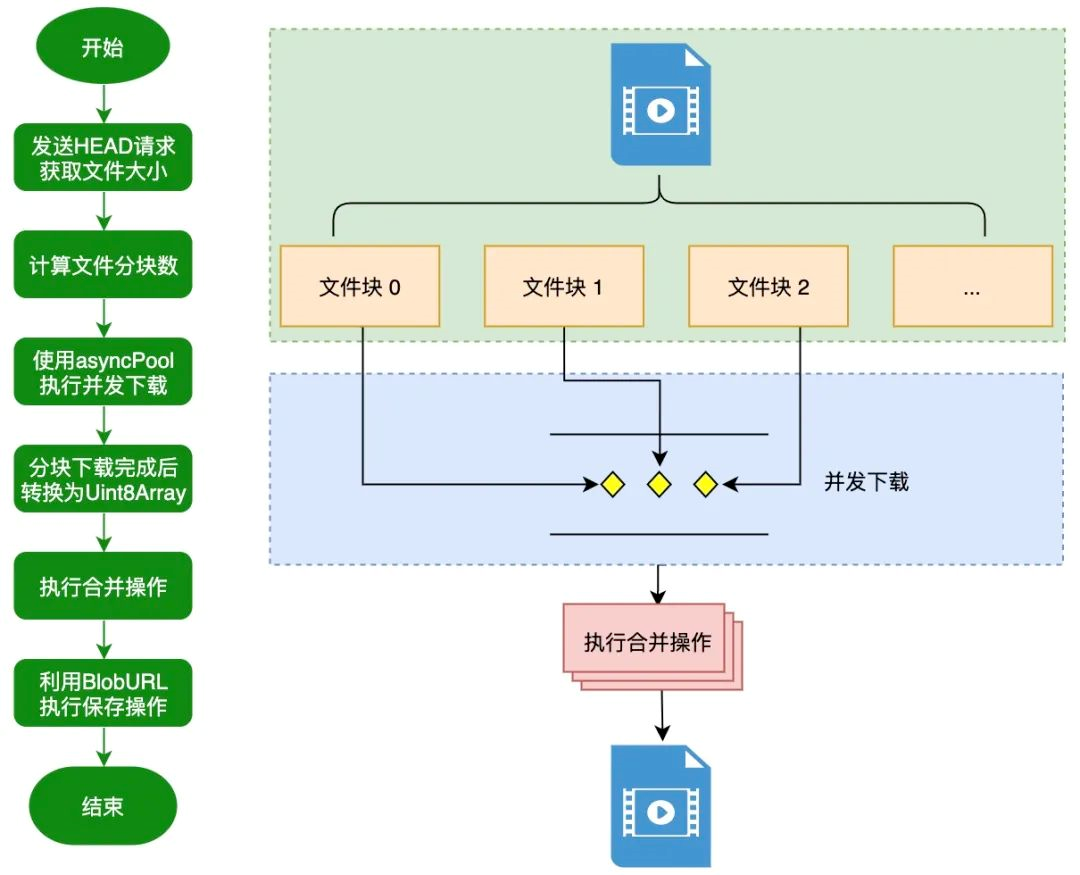
详细流程见这篇文章:《JavaScript 中如何实现大文件并行下载?》- https://mp.weixin.qq.com/s/E4SdYEkEzurfrnJrBu3bjA
原文链接:https://mp.weixin.qq.com/s/7Cz4n-9OY8DgMRNSKV-R9g