Day 2(冯哲)
今天的内容主要分为一下几部分
二叉搜索树
二叉搜索树(BST)是用有根二叉树来存储的一种数据结构,在二叉树中每个节点代表一个数据。
每个节点包含一个指向父亲的指针,和两个指向儿子的指针。如果没有则为空。
每个节点还包含一个key值,代表他本身这个点的权值。
特征:
- 二叉搜索树的key值是决定树形态的标准。
- 每个点的左子树中,节点的key值都小于这个点。
- 每个点的右子树中,节点的key值都大于这个点。
PS:在接下来的介绍中,我们将以ls[x]表示x的左儿子,rs[x]表示x的右儿子,fa[x]表示x的父亲,key[x]表示x这个点的权值。
BST是一种支持对权值进行查询的数据结构,它支持:
(1)插入一个数,删除一个数,询问最大/最小值,询问第k大值。
(2)当然,在所有操作结束后,它还能把剩下的数从小到大输出来。
查询最大值/最小值:
注意到BST左边的值都比右边小,所以如果一个点有左儿子,就往左儿子走,否则这个点就是最小值啦。
形象点就是使劲往左找(白眼)
最小值伪代码 ↓:
int FindMin() { int x = root; while (ls[x]) { x = ls[x]; } return key[x]; }
对BST删除时,都需要对树进行维护
(1)若直接删除该点,则在查询时很困难
(2)对这个结点的儿子进行考虑:
1.若无儿子,则直接删除
2.若x有一个儿子,直接把x的儿子接到x的父亲下面就行了
3.如果x有两个儿子,这种情况就比较麻烦了
1>定义x的后继y,是x右子树中所有点里,权值最小的点
2>找这个点可以x先走一次右儿子,再不停走左儿子
3>如果y是x的右儿子,那么直接把y的左儿子赋成原来x的左儿子,然后用y替代x的位置
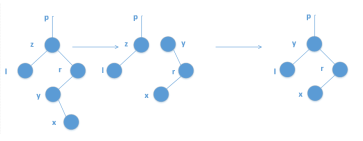
"找点"伪代码:
int Find(int x) { int now = root; while(key[now]! = x) if (key[now] < x) now = rs[now]; else now = ls[now]; return now; }
这里的总代码貌似很麻烦qwq【老师都不想写】
#include<cstdio> #include<algorithm> #include<cstring> #include<iostream> #include<cstring> #include<string> #include<cmath> #include<ctime> #include<set> #include<vector> #include<map> #include<queue> #define N 300005 #define M 8000005 #define mid ((l+r)>>1) #define mk make_pair #define pb push_back #define fi first #define se second using namespace std; int i,j,m,n,p,k,ls[N],rs[N],sum[N],size[N],a[N],root,tot,fa[N]; void ins(int x)//插入一个权值为x的数字 { sum[++tot]=x;//用tot来表示二叉树里的节点个数 size[tot]=1; if (!root) root=tot;//没有节点 else { int now=root; //从根开始 for (;;) { ++size[now]; if (sum[now]>sum[tot]) //判断和当前节点的大小 { if (!ls[now]) { ls[now]=tot; fa[tot]=now; break; } else now=ls[now]; } else { if (!rs[now]) { rs[now]=tot; fa[tot]=now; break; } else now=rs[now]; } } } } int FindMin() { int now=root; while (ls[now]) now=ls[now]; return sum[now]; } void build1()//暴力build的方法,每次插入一个值 { for (i=1;i<=n;++i) ins(a[i]); } int Divide(int l,int r) { if (l>r) return 0; ls[mid]=Divide(l,mid-1); rs[mid]=Divide(mid+1,r); fa[ls[mid]]=fa[rs[mid]]=mid; fa[0]=0; sum[mid]=a[mid]; size[mid]=size[ls[mid]]+size[rs[mid]]+1; return mid; } void build2()//精巧的构造,使得树高是log N的 { sort(a+1,a+n+1); root=Divide(1,n); tot=n; } int Find(int x)//查询值为x的数的节点编号 { int now=root; while (sum[now]!=x&&now) if (sum[now]<x) now=rs[now]; else now=ls[now]; return now; } int Findkth(int now,int k) { if (size[rs[now]]>=k) return Findkth(rs[now],k); else if (size[rs[now]]+1==k) return sum[now]; else Findkth(ls[now],k-size[rs[now]]-1);//注意到递归下去之后右侧的部分都比它要大 } void del(int x)//删除一个值为x的点 { int id=Find(x),t=fa[id];//找到这个点的编号 if (!ls[id]&&!rs[id]) { if (ls[t]==id) ls[t]=0; else rs[t]=0; //去掉儿子边 for (i=id;i;i=fa[i]) size[i]--; } else if (!ls[id]||!rs[id]) { int child=ls[id]+rs[id];//找存在的儿子的编号 if (ls[t]==id) ls[t]=child; else rs[t]=child; fa[child]=t; for (i=id;i;i=fa[i]) size[i]--; } else { int y=rs[id]; while (ls[y]) y=ls[y]; //找后继 if (rs[id]==y) { if (ls[t]==id) ls[t]=y; else rs[t]=y; fa[y]=t; ls[y]=ls[id]; fa[ls[id]]=y; for (i=id;i;i=fa[i]) size[i]--; size[y]=size[ls[y]]+size[rs[y]];//y的子树大小需要更新 } else //最复杂的情况 { for (i=fa[y];i;i=fa[i]) size[i]--;//注意到变换完之后y到root路径上每个点的size都减少了1 int tt=fa[y]; //先把y提出来 if (ls[tt]==y) { ls[tt]=rs[y]; fa[rs[y]]=tt; } else { rs[tt]=rs[y]; fa[rs[y]]=tt; } //再来提出x if (ls[t]==x) { ls[t]=y; fa[y]=t; ls[y]=ls[id]; rs[y]=rs[id]; } else { rs[t]=y; fa[y]=t; ls[y]=ls[id]; rs[y]=rs[id]; } size[y]=size[ls[y]]+size[rs[y]]+1;//更新一下size } } } int main() { scanf("%d",&n); for (i=1;i<=n;++i) scanf("%d",&a[i]); build1(); printf("%d ",Findkth(root,2));//查询第k大的权值是什么 del(4); printf("%d ",Findkth(root,2)); }
插入就相对简单了,使得根结点的左子树严格小于他,右子树严格大于他,这样就再插入时比较就可以了。
课件是这么说的:

伪代码:
void insert(intval) { key[+ + tot] = val; ls[tot] = rs[tot] = 0; int now = root;//当前访问的节点为now. for(; ; ) { if (val < key[now]) if (!ls[now]) ls[now] = x, fa[x] = now, break; else now =ls[now]; else if (!rs[now]) rs[now] = x, fa[x] =now, break; else now = rs[now]; } }
下面讲一个小扩展的例题(说说思路就行辽)
求第k大的值(如果不能求的话它将会被堆完爆)
对每个节点在多记一个size[x]表示x这个节点子树里节点的个数。
从根开始,如果右子树的size ≥ k,就说明第k大值在右侧,
往右边走,如果右子树size + 1 = k,那么说明当前这个点就是第k大值。
否则,把k减去右子树size + 1,然后递归到左子树继续操作。
来个伪代码叭:
int Findth(int now, int k) { if (size[rs[now]] >= k) { return Findth(rs[now], k); } else if (size[rs[now]] + 1 == k) { return key[now]; } else { return Findth(ls[now], k - size[rs[now]] - 1); } }
还有就是有关遍历的问题;
注意到权值在根的左右有明显的区分。
做一次中序遍历就可以从小到大把所有树排好了。
中序遍历:不停的访问左儿子,直到最后再退回父结点(递归),再走右儿子【类似于我们教练讲的左头右】
遍历伪代码:
inline int DFS(int now) { if (ls[now]) { DFS(ls[now]); } print(key[now]); if (rs[now]) { DFS(rs[now]); } }
还有一个良好的总结:

二叉堆
堆是一种特殊的二叉树,并且是一棵满二叉树。
第i个节点的父亲是i/2,这样我们就不用存每个点的父亲和儿子了。
二叉搜索树需要保持树的中序遍历不变,而堆则要保证每个点比两个儿子的权值都小。
对于二叉堆来说,主要有这么几个步骤:
建堆:
首先是要建出这么一个堆,最快捷的方法就是直接O(N log N)排一下序。
反正堆的所有操作几乎都是O(log N)的(qwq)。之后可以对这个建堆进行优化。
求最小值:
可以发现每个点都比两个儿子小,那么最小值显然就是a[1]
插入:
首先我们先把新加入的权值放入到n + 1的位置。
然后把这个权值一路往上比较,如果比父亲小就和父亲交换。
注意到堆的性质在任何一次交换中都满足。
而删除最小值只要把一个权值改到无穷大就能解决
解决定位问题
一般来说,堆的写法不同,操作之后堆的形态不同.
所以一般给的都是改变一个权值为多少的点.
假设权值两两不同,再记录一下某个权值现在哪个位置。
在交换权值的时候顺便交换位置信息。
删除权值:
理论上来说删除一个点的权值就只需要把这个点赋成inf 然后down一次。
但是这样堆里的元素只会越来越多.
我们可以把堆里第n号元素跟这个元素交换一下。
然后n--,把堆down一下就行了。
(PS:up(上浮)。down(下沉)。)
那么现在来考虑一种新的建堆方法。
倒序把每个节点都down一下.
正确性肯定没有问题。
复杂度n/2 + n/4 * 2 + n/8 * 3 + .... = O(n)
搞一个手写堆代码:
#include<cstdio> #include<algorithm> #include<cstring> #include<iostream> #include<cstring> #include<string> #include<cmath> #include<ctime> #include<set> #include<vector> #include<map> #include<queue> #define N 300005 #define M 8000005 #define ls (t<<1) #define rs ((t<<1)|1) #define mid ((l+r)>>1) #define mk make_pair #define pb push_back #define fi first #define se second using namespace std; int i,j,m,n,p,k,a[N]; int FindMin() { return a[1]; } void build1() { sort(a+1,a+n+1); } void up(int now) { while (now&&a[now]<a[now/2]) swap(a[now],a[now/2]),now/=2; } void ins(int x) { a[++n]=x; up(n); } void down(int now) { while (now*2<=n) { if (now*2==n) { if (a[now]>a[now*2]) swap(a[now],a[now*2]),now*=2; } else { if (a[now]<=a[now*2]&&a[now]<=a[now*2+1]) break; if (a[now*2]<a[now*2+1]) swap(a[now],a[now*2]),now*=2; else swap(a[now],a[now*2+1]),now=now*2+1; } } } void del(int x) { swap(a[x],a[n]); --n; up(x); down(x); } void change(int x,int val) { if (a[x]>val) { a[x]=val; up(x); } else { a[x]=val; down(x); } } void build2() { for (i=n/2;i>=1;--i) down(i); } int main() { scanf("%d",&n); for (i=1;i<=n;++i) scanf("%d",&a[i]); build2(); }
这里介绍一下<set>的几个库函数:
C++ Sets(操作库)
集合(Set)是一种包含已排序对象的关联容器
begin( )
返回指向第一个元素的迭代器
clear( )
清除所有元素
count( )
返回某个值元素的个数
empty( )
如果集合为空,返回true
end( )
返回指向最后一个元素的迭代器
equal_range( )
返回集合中与给定值相等的上下限的两个迭代器
erase( )
删除集合中的元素
find( )
返回一个指向被查找到元素的迭代器
get_allocator( )
返回集合的分配器
insert( )
在集合中插入元素
lower_bound( )
返回指向大于(或等于)某值的第一个元素的迭代器
key_comp( )
返回一个用于元素间值比较的函数
max_size( )
返回集合能容纳的元素的最大限值
rbegin( )
返回指向集合中最后一个元素的反向迭代器
rend( )
返回指向集合中第一个元素的反向迭代器
size( )
集合中元素的数目
swap( )
交换两个集合变量
upper_bound( )
返回大于某个值元素的迭代器
value_comp( )
返回一个用于比较元素间的值的函数
【优点:set可以实时维护有序的数组】

丑数
丑数指的是质因子中仅包含2, 3, 5, 7的数,最小的丑数
是1,求前k个丑数。
K ≤ 6000.
主要分两种思路解题
- 打表大法好!没有什么是打表解决不了的 (大误)
- 考虑递增的来构造序列.x被选中之后,接下来塞进去x * 2, x * 3, x * 5, x * 7.如果当前最小的数和上一次选的一样,就跳过.
复杂度O(K log N). 【还靠谱点qwq】
区间RMQ问题
区间RMQ问题是指这样一类问题。
给出一个长度为N的序列,我们会在区间上干的什么(比如单点加,区间加,区间覆盖),并且询问一些区间有关的信息(区间的和,区间的最大值)等。
这里介绍几种方法:
ST表
ST表是一种处理静态区间可重复计算问题的数据结构,一般也就求求最大最小值 。(没有其余多的用处)
ST表的思想是先求出每个[i, i + 2k)的最值。注意到这样区间的总数是O(N log N)的.
预处理(十分重要的一步)
不妨令fi,j为[i, i + 2j)的最小值。
那么首先fi,0的值都是它本身。
而fi,j = min(fi,j-1, fi+2j-1,j-1)【玄学操作qwq】
这样在O(N log N)的时间内就处理好了整个ST表

询问:
比如我们要询问[l, r]这个区间的最小值.
找到最大的k满足2k ≤ r - l + 1.
取[l, l + 2k), [r - 2k + 1, r + 1)这两个区间。
注意到这两个区间完全覆盖了[l, r],所以这两个区间最小值较小的一个就是[l, r]的最小值。
因为注意到每次询问只要找区间就行了,所以复杂度是O(1).
ST表代码:
#include <cstdio> #include <algorithm> #include <cstring> #include <iostream> #include <cstring> #include <string> #include <cmath> #include <ctime> #include <set> #include <vector> #include <map> #include <queue> #define N 300005 #define M 8000005 #define K 18 #define ls (t << 1) #define rs ((t << 1) | 1) #define mid ((l + r) >> 1) #define mk make_pair #define pb push_back #define fi first #define se second using namespace std; int i, j, m, n, p, k, ST[K + 1][N], a[N], Log[N]; int Find(int l, int r) { int x = Log[r - l + 1]; return max(ST[x][l], ST[x][r - (1 << x) + 1]); } int main() { scanf("%d", &n); for (i = 1; i <= n; ++i) scanf("%d", &a[i]); for (i = 1; i <= n; ++i) ST[0][i] = a[i]; for (i = 1; i <= K; ++i) for (j = 1; j + (1 << i) - 1 <= n; ++j) ST[i][j] = max(ST[i - 1][j], ST[i - 1][j + (1 << (i - 1))]); for (i = 1; (1 << i) < N; ++i) Log[1 << i] = i; for (i = 1; i < N; ++i) if (!Log[i]) Log[i] = Log[i - 1]; printf("%d ", Find(1, 3)); }
PS:ST表确实是一个询问O(1)的数据结构,但是它的功效相对也较弱.
例如每次求一个区间的和,利用前缀(布吉岛)可以做到O(N) - O(1).而ST表却无法完成。
据说好像做题有个这样的步骤: (蕴含哲学qwq)
(蕴含哲学qwq)
给出一个序列,支持对某个点的权值修改,或者询问某个区间的最大值.
N, Q ≤ 100000.
我们会十分快乐的发现:ST表不行(妈耶那我凉了呀)
这就引入一个名叫线段树的东西
其实线段树被称为区间树比较合适 ,本质是一棵不会改变形态的二叉树
树上的每个节点对应于一个区间[a, b](也称线段),a,b通常为整数.

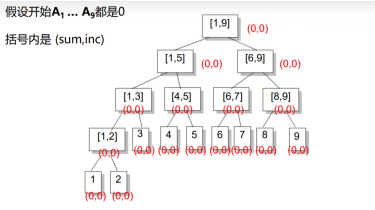
来几个实例: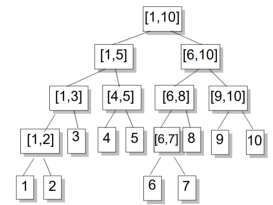 (n=10)
(n=10)
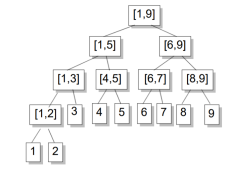 (n=9)
(n=9)
我们注意到线段树的结构有点像分治结构,深度也是O(log N)的.
区间拆分:
区间拆分是线段树的核心操作,我们可以将一个区间[a, b]拆分成若干个节点,使得这些节点代表的区间加起来是[a, b],并且相互之间不重叠.
所有我们找到的这些节点就是”终止节点”.
区间拆分的步骤:
从根节点[1, n]开始,考虑当前节点是[L, R].如果[L, R]在[a, b]之内,那么它就是一个终止节点.否则,分别考虑[L, Mid],[Mid + 1, R]与[a, b]是否有交,递归两边继续找终止节点.
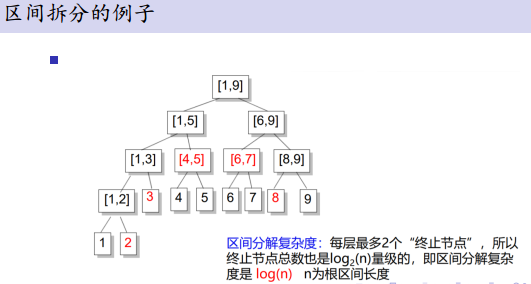
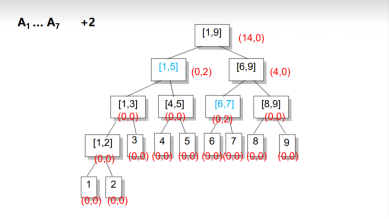
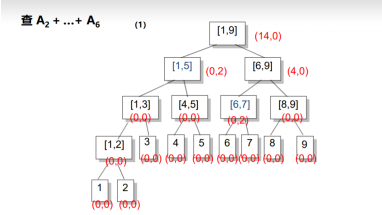
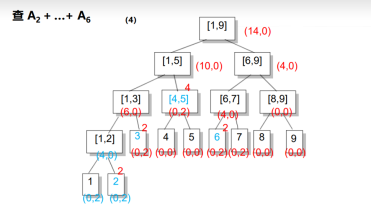
延迟更新:(标记-lazy标记)

类似于线段树,向下传值更新。
向下传值时(代码):inc+=inc【t】
相对加的inc就是祖先的和和自己原本的inc



线段树的代码:
#include <cstdio> #include <algorithm> #include <cstring> #include <iostream> #include <cstring> #include <string> #include <cmath> #include <ctime> #include <set> #include <vector> #include <map> #include <queue> #define N 300005 #define M 8000005 #define ls (t * 2) #define rs (t * 2 + 1) #define mid ((l + r) / 2) #define mk make_pair #define pb push_back #define fi first #define se second using namespace std; int i, j, m, n, p, k, add[N * 4], sum[N * 4], a[N], ans, x, c, l, r; void build(int l, int r, int t) { if (l == r) sum[t] = a[l]; else { build(l, mid, ls); build(mid + 1, r, rs); sum[t] = max(sum[ls], sum[rs]); } } void modify(int x, int c, int l, int r, int t) { if (l == r) sum[t] = c; else { if (l <= x && x <= mid) modify(x, c, l, mid, ls); else modify(x, c, mid + 1, r, rs); sum[t] = max(sum[ls], sum[rs]); } } void ask(int ll, int rr, int l, int r, int t) { if (ll <= l && r <= rr) ans = max(ans, sum[t]); else { if (ll <= mid) ask(ll, rr, l, mid, ls); if (rr > mid) ask(ll, rr, mid + 1, r, rs); } } int main() { scanf("%d", &n); for (i = 1; i <= n; ++i) scanf("%d", &a[i]); build(1, n, 1); modify(1, 5, 1, n, 1); ask(1, 5, 1, n, 1); }
树状数组
树状数组是一种用来求前缀和的数据结构
记lowbit(x)为x的二进制最低位.
例子:lowbit(8) = 8, lowbit(6) = 2
求lowbit:
int lowbit(int x) { return x&-x; }
对于原始数组A,我们设一个数组C.
C[i]=a[i-lowbit(i)+1]+...+a[i]
i > 0的时候C[i]才有用.C就是树状数组.
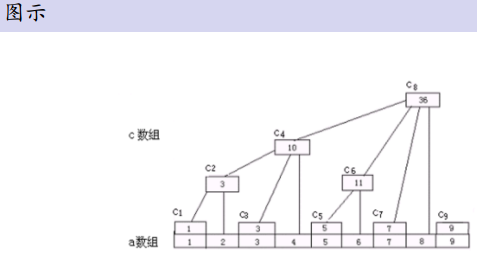
求和与更新:
求和:
树状数组只能够支持询问前缀和。我们先找到C[n],然后我们发现现在,下一个要找的点是n - lowbit(n),然后我们不断的减去lowbit(n)并累加C数组.
我们可以用前缀和相减的方式来求区间和.
询问的次数和n的二进制里1的个数相同.则是O(log N).
更新:
现在我们要修改Ax的权值,考虑所有包含x这个位置的区间个数.
从C[x]开始,下一个应该是C[y = x + lowbit(x)],再下一个是C[z = y + lowbit(y)]...
注意到每一次更新之后,位置的最低位1都会往前提1.总复杂度也为O(log N).
留一个树状数组的题:
TLE25分代码(果然是我太天真qwq)
#include<iostream> #include<cstdio> #include<algorithm> #include<cmath> using namespace std; long long s[500001]; int main() { int n,a; scanf("%d",&n); for(int i=1;i<=n;i++) { scanf("%Ld",&s[i]); } for(int i=1;i<=n;i++) { for(int j=1;j<i;j++) { if(s[j]>s[i]) { a++; } } } printf("%d",a); return 0; }
后来用了个离散化qwq还是TLE25分【还是吸了氧气qwq】
// luogu-judger-enable-o2 #include <iostream> #include <cstdio> #include <algorithm> using namespace std; struct m { int x,y,z; }s[500001]; int qwq(m a,m b) { return a.x<b.x; } int QWQ(m a,m b) { return a.y<b.y; } int main() { int n,k=1,c=1; scanf("%d",&n); for(int i=1;i<=n;i++) { scanf("%d",&s[i].x); s[i].y=i; } sort(s+1,s+1+n,qwq); for(int i=1;i<=n;i++) { if(s[i].x==s[i-1].x) { s[i].z=s[i-1].z; } else { s[i].z=c; c++; } } sort(s+1,s+1+n,QWQ); c=0; for(int i=1;i<=n;i++) { for(int j=1;j<i;j++) { if(s[j].x>s[i].x) { c++; } } } printf("%d",c); }
最后最后终于用树状数组AC了
#include <cstdio> #include <algorithm> #include <cstring> #include <iostream> #include <cstring> #include <string> #include <cmath> #include <ctime> #include <set> #include <vector> #include <map> #include <queue> #define N 500005 #define M 8000005 #define ls (t << 1) #define rs ((t << 1) | 1) #define mid ((l + r) >> 1) #define mk make_pair #define pb push_back #define fi first #define se second using namespace std; int i, j, m, n, p, k, C[N], a[N], b[N]; long long ans; int lowbit(int x) { return x & -x; } void ins(int x, int y) //修改a[x]的值,a[x]+=y; { for (; x <= n; x += lowbit(x)) C[x] += y; //首先需要修改的区间是以x为右端点的,然后下一个区间是x+lowbit(x),以此类推 } int ask(int x) //查询[1,x]的值 { int ans = 0; for (; x; x -= lowbit(x)) ans += C[x]; //我们询问的]是[x-lowbit(x)+1,x,然后后面一个区间是以x-lowbit(x)为右端点的,依次类推 return ans; } int main() { scanf("%d", &n); for (i = 1; i <= n; ++i) scanf("%d", &a[i]), b[++b[0]] = a[i]; sort(b + 1, b + b[0] + 1); b[0] = unique(b + 1, b + b[0] + 1) - (b + 1); for (i = 1; i <= n; ++i) a[i] = lower_bound(b + 1, b + b[0] + 1, a[i]) - b; for (i = 1; i <= n; ++i) ans += (i - 1) - ask(a[i]), ins(a[i], 1); printf("%lld ", ans); }
紧赶慢赶终于到了并查集了
N个不同的元素分布在若干个互不相交集合中,需要多次进行以下3个操作:
1. 合并a,b两个元素所在的集合 Merge(a,b)
2. 查询一个元素在哪个集合
3. 查询两个元素是否属于同一集合 Query(a,b)
并查集的总代码:
#include<cstdio> #include<algorithm> #include<cstring> #include<iostream> #include<cstring> #include<string> #include<cmath> #include<ctime> #include<set> #include<vector> #include<map> #include<queue> #define N 300005 #define M 8000005 #define ls (t<<1) #define rs ((t<<1)|1) #define mid ((l+r)>>1) #define mk make_pair #define pb push_back #define fi first #define se second using namespace std; int i,j,m,n,p,k,fa[N],deep[N]; int get(int x) //不加任何优化的暴力 { while (fa[x]!=x) x=fa[x]; return x; } //路径压缩 /* int get(int x) { return fa[x]==x?fa[x]:fa[x]=get(fa[x]); } //按秩合并 void Merge(int x,int y) { x=get(x); y=get(y); 使用的是最暴力的get if (deep[x]<deep[y]) fa[x]=y; else if (deep[x]>deep[y]) fa[y]=x; else deep[x]++,fa[y]=x; } */ void Merge(int x,int y) { x=get(x); y=get(y); //找到x,y所在连通块的顶点 fa[x]=y; } int Ask(int x,int y) { x=get(x); y=get(y); if (x==y) return 1;//表示连通 return 0; } int main() { scanf("%d",&n); for (i=1;i<=n;++i) fa[i]=i,deep[i]=1; Merge(2,3);//合并2,3所在的连通块 printf("%d ",Ask(2,3));//询问2,3是否在同一个连通块里 }
这里用一个例题带大家看看(自己理解叭)
#include<bits/stdc++.h> using namespace std; int n,m; int x,y,z; int a,b; int fa[200001]; int find(int x) { if(fa[x]!=x) { fa[x]=find(fa[x]); } return fa[x]; } void unionn(int r1,int r2) { fa[r2]=r1; } int main() { cin>>n>>m; for(int i=1;i<=n;i++) { fa[i]=i; } for(int i=1;i<=m;i++) { cin>>x>>y>>z; a=find(y); b=find(z); if(x==1) { if(a!=b) { unionn(a,b); } } if(x==2) { if(a==b) { cout<<"Y"<<endl; } else { cout<<"N"<<endl; } } } }
还讲到了路径压缩和按秩合并
路径压缩:
第一种优化看起来很玄学,我们在寻找一个点的顶点的时候,显然可以把这个点的父亲赋成他的顶点,也不会有什么影响.
看起来玄学,但是他的复杂度是O(N log N)的。
证明非常复杂,有兴趣的同学可以自行翻阅论文。
路径压缩的修改部分主要在Getroot部分
就一行代码:
int get(int x) { return fa[x]==x?fa[x]:fa[x]=get(fa[x]); }
按秩合并:
对每个顶点,再多记录一个当前整个结构中最深的点到根的深度deepx.
注意到两个顶点合并时,如果把比较浅的点接到比较深的节点上.
如果两个点深度不同,那么新的深度是原来较深的一个.
只有当两个点深度相同时,新的深度是原来的深度+1.
注意到一个深度为x的顶点下面至少有2x个点,所以x至多为log N.
那么在暴力向上走的时候,要访问的节点至多只有log个
按秩合并的修改部分在于Merge,其他部分都与暴力相同
伪代码:
void Merge(int x,int y) { x=get(x); y=get(y); 使用的是最暴力的get if (deep[x]<deep[y]) fa[x]=y; else if (deep[x]>deep[y]) fa[y]=x; else deep[x]++,fa[y]=x; }
将两者进行比较:
无论是时间,空间,还是代码复杂度,路径压缩都比按秩合并优秀.
值得注意的是,路径压缩中,复杂度只是N次操作的总复杂度为O(N log N)。按秩合并每一次的复杂度都是严格O(log N)的.
两种方式可以一起用,复杂度会降的更低.
最后的最后LCA
在一棵有根树中,树上两点x, y的LCA指的是x, y向根方向遇到到第一个相同的点 我们记每一个点到根的距离为deepx.
注意到x, y之间的路径长度就是deepx + deepy - 2 * deepLCA.
int Find_LCA(int x,int y) //求x,y的LCA { int i,k; if (deep[x]<deep[y]) swap(x,y); x=Kth(x,deep[x]-deep[y]); //把x和y先走到同一深度 if (x==y) return x; for (i=K;i>=0;--i) //注意到x到根的路径是xa1a2...aic1c2...ck //y到根的路径是 yb1b2...bic1c2...ck 我们要做的就是把x和y分别跳到a_i,b_i的位置,可以发现这段距离是相同的. if (fa[x][i]!=fa[y][i]) x=fa[x][i],y=fa[y][i]; return fa[x][0]; }
原始求法:
两个点到根路径一定是前面一段不一样,后面都一样.
注意到LCA的深度一定比x, y都要小.
利用deep,把比较深的点往父亲跳一格,直到x, y跳到同一个点上.
这样做复杂度是O(len).
倍增法
考虑一些静态的预处理操作.
像ST表一样,设fa i,j为i号点的第2j个父亲。
自根向下处理,容易发现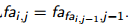
求第K个祖先
首先,倍增可以求每个点向上跳k步的点.
利用类似快速幂的想法.
每次跳2的整次幂,一共跳log次.
求LCA:
首先不妨假设deepx < deepy.
为了后续处理起来方便,我们先把x跳到和y一样深度的地方.
如果x和y已经相同了,就直接退出.
否则,由于x和y到LCA的距离相同,倒着枚举步长,如果x, y的第2^j个父亲不同,就跳上去.样,最后两个点都会跳到离LCA距离为1的地方,在跳一步就行了.
时间复杂度O(N log N)
#include<cstdio> #include<algorithm> #include<cstring> #include<iostream> #include<cstring> #include<string> #include<cmath> #include<ctime> #include<set> #include<vector> #include<map> #include<queue> #define N 300005 #define M 8000005 #define K 18 #define ls (t<<1) #define rs ((t<<1)|1) #define mid ((l+r)>>1) #define mk make_pair #define pb push_back #define fi first #define se second using namespace std; int i,j,m,n,p,k,fa[N][K+1],deep[N]; vector<int>v[N]; void dfs(int x) //dfs求出树的形态,然后对fa数组进行处理 { int i; for (i=1;i<=K;++i) //fa[x][i]表示的是x向父亲走2^i步走到哪一个节点 fa[x][i]=fa[fa[x][i-1]][i-1]; //x走2^i步相当于走2^(i-1)步到一个节点fa[x][i-1],再从fa[x][i-1]走2^(i-1)步 for (i=0;i<(int)v[x].size();++i) { int p=v[x][i]; if (fa[x][0]==p) continue; fa[p][0]=x; deep[p]=deep[x]+1; //再记录一下一个点到根的深度deep_x dfs(p); } } int Kth(int x,int k) //求第k个父亲,利用二进制位来处理 { for (i=K;i>=0;--i) //k可以被拆分成logN个2的整次幂 if (k&(1<<i)) x=fa[x][i]; return x; } int Find_LCA(int x,int y) //求x,y的LCA { int i,k; if (deep[x]<deep[y]) swap(x,y); x=Kth(x,deep[x]-deep[y]); //把x和y先走到同一深度 if (x==y) return x; for (i=K;i>=0;--i) //注意到x到根的路径是xa1a2...aic1c2...ck //y到根的路径是 yb1b2...bic1c2...ck 我们要做的就是把x和y分别跳到a_i,b_i的位置,可以发现这段距离是相同的. if (fa[x][i]!=fa[y][i]) x=fa[x][i],y=fa[y][i]; return fa[x][0]; } int main() { scanf("%d",&n); for (i=1;i<n;++i) { int x,y; scanf("%d%d",&x,&y); v[x].pb(y); v[y].pb(x); } dfs(1); printf("%d ",Find_LCA(3,5)); }
总结:
LCA能发挥很大的用处
倍增这一算法的时空复杂度分别为O(N log N) - O(log N) O(N log N).
对于求第K个祖先,利用长链剖分以及倍增算法,可以做到O(N log N) - O(1) O(N log N).
对于求LCA,利用ST表以及欧拉序可以做到O(N log N) - O(1) O(N log N)
qwq,终于整完了
例题会少一些(望谅解)