整两天再看调优分析的部分,发现实际运行环境下,还是要考虑配置垃圾回收器,所以这里就加一小章介绍一下。
首先来看一下HotSpot所支持回收期的关系图:
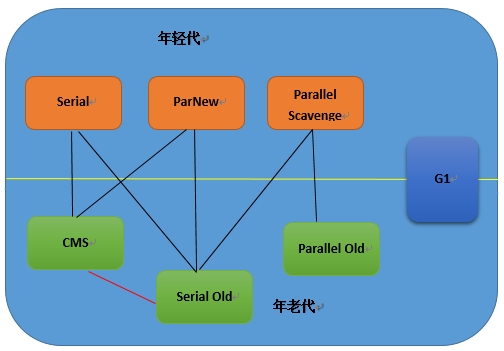
图中可以看到一共有7中垃圾回收器,以中间绿线为界,上边三个用于年轻代,下边三个用在年老代,而G1则老少通吃,黑线线表示两个回收器可搭配使用,红线则表示两者可以在同一区域交替使用。由于G1在JDK1.7才达到商用级别,而且目前线上环境也很少使用,在此不再介绍。下面我们来介绍一下其他六种:
Serial:从名字就能看出是串行的意思,该回收器是最早实现的,基于单线程,实现简单且效率高,但是进行垃圾回收是会造成“Stop-the-World”(STW),当回收内存区域较大时,就会造成程序响应时间变长。
ParNew:全名Parallel New Generation,也就是并行新生代垃圾回收期,该回收器实现与Serial基本上一样,只是采用多线程执行回收。
Parallel Scavenge:并行清理,也就是并行垃圾回收器。该回收器与ParNew的最大区别在于ParNew通常与CMS搭配,一般注重于减少垃圾回收的停顿时间,提高响应速度,而Parallel Scavenge则侧重于吞吐量的控制,又名"吞吐量优先"回收器(吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间);响应时间影响用户体验,而吞吐量则影响CPU利用率,进而影响程序程序运算效率)。此外需注意,该回收器不能够和CMS搭配使用。
CMS:Concurrent Mark Sweep,是一个并发回收器,旨在减少垃圾回收的停顿时间。我们可以从其处理过程分析一下:
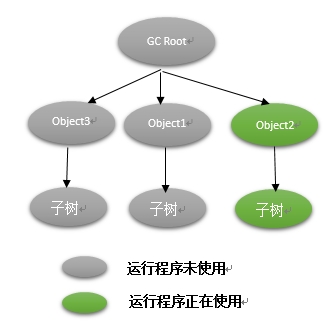
- 初始标记:该阶段只标记GC Root节点(见上一篇)直接引用的节点,会造成STW,但是时间很短。图中该阶段Object1、Object3、Object2标记
- 并发标记:该阶段是整个回收过程最耗时阶段,对于程序正在使用的对象,程序运行和标记交替进行,而程序未占用的则可以直接标记,这样程序整体对外停顿时间缩短(可以了解下并发的概念),减少了响应时间。该阶段图中Object1、Object3子树正常标记,而Object2子树并发标记。
- 重新标记:由于被程序占用的对象在一段时间后可能死掉,因此在并发标记结束后,可能有新对象死掉而未被标记,因此需要对这一部分重新标记。该阶段图中Object2子树需要重新标记。
- 并发清理:该阶段过程与并发标记类似。
CMS回收器的缺点主要在三方面:1、占用一部分CPU资源,导致吞吐量下降;2、由于并发过程是回收和程序运行交替进行,会产生一些新垃圾进入年老代而未被清理 ,当年老代满时引起Full GC(因此一般年老代要预留一部分空间供程序使用);3、标记-清理的缺点——空间碎片,因此要适时进行压缩。
Serial Old:没啥好说Serial的年老代版。
Parallel Old:Parallel Scavenge的年老代版。
下边我们来看一下几个垃圾回收器的各方面对比:
| 名称 |
|
区域 | 算法 | 适用情况 |
|
Serial |
串行 | 年轻代 |
复制 |
单CPU(或CPU较少)、小型客户端应用 |
|
Parallel Scavenge |
并行 |
年轻代 |
复制 |
多CPU、吞吐量优先(后台处理、科学计算) |
| ParNew |
并行 |
年轻代 |
复制 |
多CPU、响应优先(web服务器等) |
| CMS | 并发 | 年老代 | 标记-清除 |
响应优先(web服务器等) |
|
Serial Old |
串行 |
年老代 |
标记-整理 |
单CPU、小型客户端应用 |
|
Parallel Old |
并行 |
年老代 |
标记-整理 |
多CPU、吞吐量优先(后台处理、科学计算) |
从上表我们可以总结:对于小型应用或是单CPU机上跑的应用,可采用Serial+Serial Old;对于web服务器等响应优先的应用:ParNew(Serial)+CMS;对于后台处理、科学运算之类的,可采用Parallel Scavenge+Parallel Old;当然,具体采用什么样的搭配,还是要结合具体使用环境确定。
到此结束,睡觉喽!