一、经典的有监督学习算法
KNN算法:判断进来的样本与哪个样本类的距离最近,那么这个样本就属于这个类。


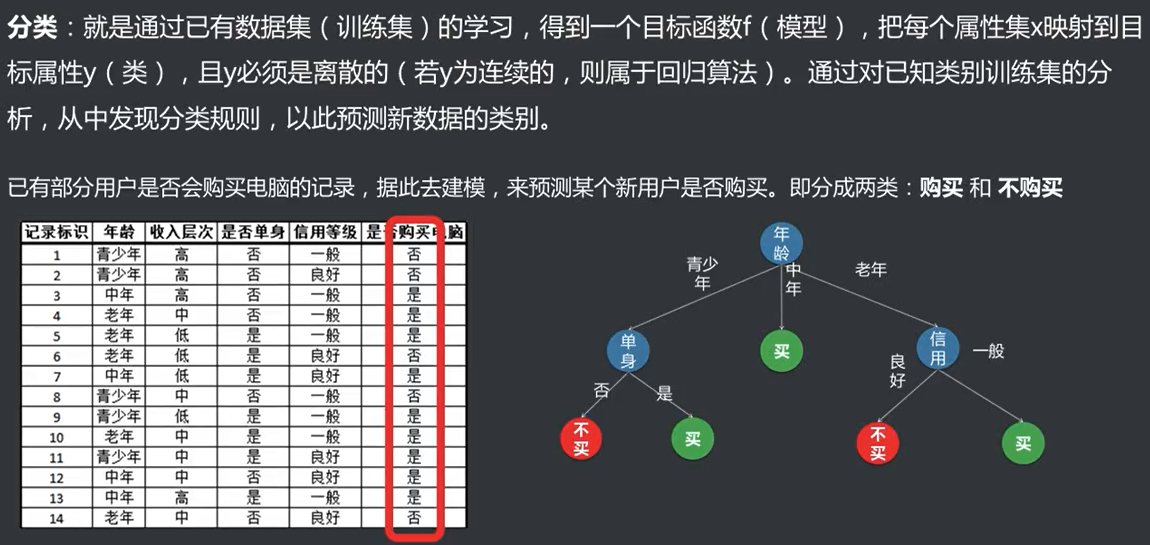
决策树算法:通过熵增量确定哪个条件对结果的影响最大,就确定这个条件为第一特征,在第一特征的基础上再通过熵增量确定哪个条件对结果的影响最大来确定第二特征,以此类推下去,直到熵为零,或者没有影响条件为止。

二、无监督学习算法
K-Means算法:指定分成K类,随机生成K个类别中心坐标,使用这个k个中心坐标聚类,计算聚类后的每类集合的中心坐标,更新这k个中心坐标,再使用更新后的k个中心坐标再重新聚类,再计算聚类后的中心坐标,再更新这k个中心坐标。以此反复,直到中心坐标不再变化或者变化不大。

Apriori规则关联算法:先计算一系列频繁集的出现的概率,然后计算规则的支持度和置信度。(主要是我没学很明白这个算法只能简要说一下)
