数据库面试题
2019年05月04日 21:29:19 李先森 阅读数 260
Section 1:小常识
1.union 和union all的区别?
union 会去重
2. 游标
游标(Cursor)是处理数据的一种方法,可以把游标当作一个指针,它可以指定结果表中的任何位置,对指定位置的数据进行处理。
显示游标:自己打开关闭
隐式游标:自动打开关闭
3用户管理
#查看用户拥有的权限
select * from mysql.user;
select * from information_schema.USER_PRIVILEGES;
#删除用户
drop role admin;
#创建用户
create user admin identified by 'first_pd';
#给与权限
grant all privileges on *.* to admin ;
#改该用户密码
ALTER USER 'admin'@'%' IDENTIFIED WITH mysql_native_password BY 'Ldd123456';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Section 1: DW Essential:
1.什么是DW?
就是一个集成的,面向主题,经过处理,基于OLAP的数据库。DW主要用于数据分析决策。
(
数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合。
数据仓库是为了便于多维分析和多角度展现而将数据按特定的模式进行存储所建立起来的关系型数据库,它的数据基于OLTP源系统。
首先,用于支持决策,面向分析型数据处理,它不同于企业现有的操作型数据库;)
2.OLTP与OLAP的区别
两种数据源模型
On line Transaction Processing On line analysis process
OLTP OLAP
用户 操作人员 决策人员
功能 日常操作 分析决策
DB设计 面积应用 面向主题
数据 当前的,最新的,细节的,二维的 | 历史的,概括的,多维集成的,统一的
存取及规模 读取少 | 大规模读取
实时性: 实时 | 非实时
维度 : 单一 | 多维
3.Structure of DW
Initail Data Source >>ETL>> Target Data Source (ODS Operational Data Store)>> DW data warehouse >> DM DataMart>>
Data Front 前端工具 or BI tool
4.Difference between DW and DB
- 数据库面对事务transaction,用于日常更新,DB面对主题,用于数据决策分析;
- DB会存储当前交易数据,DW储存历史数据;
- DB主要用于insert ,DW主要用于select;
5 How to structure DW
确定业务主题,确定字段,确定维度和粒度,建表
6 星形模型与雪花模型的区别?
查询速度快,数据冗余高
1.星星的中心是一个大的事实表,发散出来的是维度表,每一个维度表用一个PK-FK连接到事实表,维度表之间彼此并不关联。一个事实表又包括一些度量值和维度。
查询速度慢,数据冗余少
2.雪花模型通过规范维度表来减少冗余度,也就是说,维度表数据已经被分组成一个个的表而不是使用一个大表。例如产品表被分成了产品大类和产品小类两个表。尽管这样做可以节省了空间,但是却增加了维度表的数量和关联的外键的个数。这就导致了更复杂的查询并降低了数据库的效率
7 数据仓库项目最重要或需要注意的是什么,以及如何处理?
数据仓库有两个重要目的,一是数据集成,二是服务BI
数据质量(数据的一致性,正确性,稳定性…)写定时监测脚本,去周期监测数据的异常,及时反馈。
数据效率(查询效率)
1.分区分表分库。
2.避免全表扫描,首先应考虑在 where 及 orderby 涉及的列上建立索引
3 尽量不做 <> null的判断
4.避免大表之间的join。(join之前作限定,对大表做分页jion)
5 IO
6 存储过程 比select 快
8 Btree B-tree B+tree
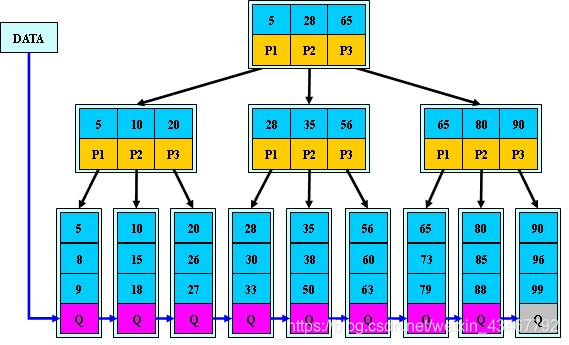
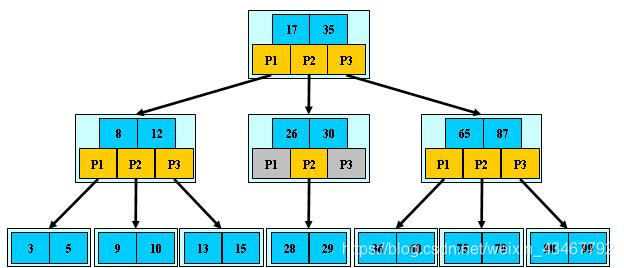
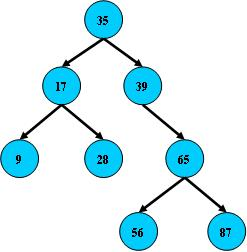
三类索引(a:B树索引b:文本索引c:位图索引)
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;在二叉树的基础上,加入平衡算法,防止出现一侧节点过多。
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Section 2 :pertain concept
事实表
事实表是包含大量数据值的一种结构。事实数据表可能代表某次银行交易,包含一个顾客的来访次数,并且这些数字信息可以汇总,以提供给有关单位作为历史的数据。
每个数据仓库都包含一个或者多个事实数据表。事实数据表只能包含数字度量字段和使事实表与维度表中对应项的相关索引字段.,该索引包含作为外键的所有相关性维度表的主键。
事实数据表中的“度量值”有两中:一种是可以累计的度量值,另一种是非累计的度量值。用户可以通过累计度量值获得汇总信息。
索引(Mysql为例)
#1.索引类型:
①primary: 唯一性,且一张表只有一个主键,且not null
②unique:唯一性:可以为null ,一张表可以有多个unique,
③normal
④fulltext 用于较长的文本索引
#2.索引方法
①Btree :树结构算法;支持范围查找;非全表扫描;
(从根节点一步步扫描到叶节点)
②hash算法: hash算法;不支持范围,只能做=,in,等价于的计算;全表扫描‘’
( 简单地说,哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。)
维度表
用来描述事实表的某个重要方面,维度表中包含事实表中事实记录的特性:有些特性提供描述性信息,有些特性指定如何汇总事实数据表数据,以便为分析者提供有用的信息,维度表包含帮助汇总数据的特性的层次结构
缓慢变化维:
在实际情况下,维度的属性并不是静态的,它会随着时间的流失发生缓慢的变化。
处理方法: 1新信息直接覆盖旧信息,2,保存多条记录,并添加字段加以区分(用y,n;0,1,2或用时间来区别新旧记录)
3.保存多条记录,并添加字段加以区分4.另外建表保存历史记录.5混合模式
粒度:(granularity)
是指数据仓库的数据单位中保存数据的细化或综合程度的级别,细化程度越高,粒度就越小。
钻取:
首先从某一个汇总数据出发,查看组成该数据的各个成员数据。
KPI(Key Performance Indication)关键业绩指标用来衡量业绩好坏比如销售这个主题,销售增长率、销售净利润就是一个KPI
E T L&抽取方式
extract/transformation/load寻找数据,整合数据,并将它们装入数据仓库的过程。
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析的依据。
抽取方式(增量抽,全量抽):
如何实现增量抽取
业务系统会记录业务发生的时间,我们可以用来做增量的标志,每次抽取之前首先判断ODS中记录最大的时间,然后根据这个时>间去业务系统取大于这个时间所有的记录。
游标 cursor
可以把游标当作一个指针,它可以指定结果表中的任何位置
Section 3 :工作中常见问题
1.备份
#1.备份类型
①根据是否需要数据库离线
冷备(cold backup):需要关mysql服务,读写请求均不允许状态下进行;
温备(warm backup): 服务在线,但仅支持读请求,不允许写请求;
热备(hot backup):备份的同时,业务不受影响。
(注:
1、这种类型的备份,取决于业务的需求,而不是备份工具
2、MyISAM不支持热备,InnoDB支持热备,但是需要专门的工具)
#2.根据要备份的数据集合的范围
完全备份:full backup,备份全部字符集。
增量备份: incremental backup 上次完全备份或增量备份以来改变了的数据,不能单独使用,要借助完全备份,备份的频率取决于数据的更新频率。
差异备份:differential backup 上次完全备份以来改变了的数据。
建议的恢复策略:
完全+增量+二进制日志
完全+差异+二进制日志
#3[具体备份操作](https://www.cnblogs.com/fengzhongzhuzu/p/9101782.html)
2.mysql大表建立索引
可以将表中数据转移到临时表,然后在空表上建立索引,完成之后再将数据重新insert到索引表中
3.数据库优化
- 加服务器配置 语句优化;
- 减少sql代码的计算量。尽量不用子查询,in/not in/LIKE ,若用子查询尽量在里面加限制条件;
- 储存过程快于sql代码,编译过的 I/O,
- 网速等
- optimize 清理表delete碎片
- 建立索引,
- ETL分层
- 插入大量记录 alter table 表名 disable keys
- 建立查询缓存
show variables like "%query_cache%";#0关 1开 2限定sql_cache
select sql_cache * from table ;
- 1
- 2
4.declare 和 set 的区别
局部变量和全局变量
declare @x int default 3 ;
set @x=3;
5存储过程与事物区别
存储过程针对某段经常调用的程序,里面可以包含事务但是无法回滚,(若某个存储过程有三句sql,前两句执行正确,第三局保存,前两句结果会执行成功);
事务强调整体性,里面可有多段sql代码,可以有调用存储过程,但是代码要么全部执行,要么全部不执行。