Spark的安装基于HDFS,所以我们要设置hadoop的配置文件,所以spark的存储不是其主要的功能点,而spark作为分布式生态中的角色是一种计算模式(其他 的计算
模式,比如MR,Storm,spark,tez)。
vim spark-env.sh
export SCALA_HOME=/path/to/scala-2.10.4
export JAVA_HOME=/usr/java/jdk
export HADOOP_HOME=/usr/local/hadoop-2.7.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_WORKER_MEMORY=7g
export SPARK_MASTER_IP=172.16.0.140
export MASTER=spark://172.16.0.140:7077
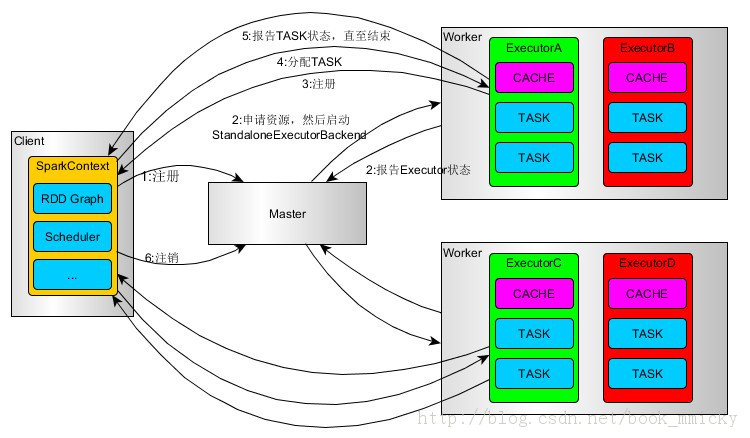
一端是构建driver,另一端就是excutor运行,而mater主要就是完成driver的调度。
运行模式:client cluster 模式
client模式: sparkContext、Driver在客户端构建
clust模式:sparkContext、Driver在不在客户端构建。
DAGScheduler与TaskScheduler全部在Driver端构建完成、最后讲Task调度到不同的Work上运行

===========================================================================
1.RDD类似于数据库中的视图,缓存RDD类似于物化视图,数据库像DSM系统一样,允许典型地读写所有记录,通过记录操作和数据的日志来实现容错,还需要花费额外的开销来维护一致性。RDD编程模型通过增加更多限制来避免这些开销。
2.RDD借鉴了DryadLINQ、Pig和FlumeJava的“并行收集”编程模型,通过允许用户显式地将未序列化的对象保存在内存中,以此来控制分区和基于key随机查找,从而有效地支持基于工作集的应用。RDD保留了那些数据流系统更高级别的编程特性,这对那些开发人员来说也比较熟悉,而且,RDD也能够支持更多类型的应用。
3.DSM通过检查点[19]实现容错,而Spark使用Lineage重建RDD分区,这些分区可以在不同的节点上重新并行处理,而不需要将整个程序回退到检查点再重新运行。RDD能够像MapReduce一样将计算推向数据[12],并通过推测执行来解决某些任务计算进度落后的问题,推测执行在一般的DSM系统上是很难实现的。