storm分布式流式计算框架。
nimbus:主进程服务(职责就是任务的分配的,程序的分发)
supervisor:工作进程服务(职责就是启动线程池,接受任务,运行任务,报告任务的运行状态)
注意容错:supervisor与nimbus都是基于zookeeper来实现容错,任务运行的元数据存储的zk里面,如果工作节点宕机,zk可以发现,执行触发机制,通知nimbus,对任务进行重新的分发。
===================================================================================
1.Bolt任务crash引起的消息未被应答。此时,acker中所有与此Bolt任务关联的消息都会因为超时而失败,对应的Spout的fail方法将被调用
2.acker任务失败。如果acker任务本身失败了,它在失败之前持有的所有消息都将超时而失败。Spout的fail方法将被调用
3.Spout任务失败。在情况下,与Spout任务对接的外部设备(如MQ)负责消息的完整性。例如,当客户端异常时,kestrel队列会将处于pending状态的所有消息重新放回队列中
任务槽(slot)故障
Worker失败。每个Worker中包含数个Bolt(或Spout)任务。Supervisor负责监控这些任务,当worker失败后会尝试在本机重启它,如果它在启动时连续失败了一定的次数,无法发送心跳信息到Nimbus,Nimbus将在另一台主机上重新分配worker
Supervisor失败。Supervisor是无状态(所有的状态都保存在Zookeeper或者磁盘上)和快速失败(每当遇到任何意外的情况,进程自动毁灭)的,因此Supervisor的失败不会影响当前正在运行的任务,只要及时将他们重新启动即可。
Nimbus失败。Nimbus也是无状态和快速失败的,因此Nimbus的失败不会影响当前正在运行的任务,但是当Nimbus失败时,无法提交新的任务,只要及时将它重新启动即可。
为了管理Spout的可靠性,可以在发射元组的时候,在元组里面包含一个消息ID
===================================================================================
下面看一下提供的编程模型
===================================
实现IRichSpout接口(BaseRichSpout),表示此处就是数据的源(1.设置数据格式-字段,2.初始化业务对象,3.处理完数据之后发送数据到下游) []
@Override public void declareOutputFields(OutputFieldsDeclarer arg0) { //设置输出的数据格式字段 } @Override public void open(Map arg0, TopologyContext arg1,SpoutOutputCollector arg2) { //首先获取到SpoutOutputCollector //初始化相关的参数数据 } @Override public void nextTuple() { //开始处理数据 }
实现IRichBolt接口(BaseBasicBolt ),表示对数据的处理逻辑接口(初始化对象,处理数据,发送到下游继续处理)
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector arg2) {
//初始化相关的参数对象OutputCollector
}
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
//声明处理输出的字段数据
}
@Override
public void execute(Tuple arg0) {
//处理业务数据接口
}
组装通过Topology实现,设置spout,bolt的pie流程关系,设置任务的名称以及并行度等参数,此类里面有个main函数就是执行的入口函数。
==================================================================================================
storm的操作算子:
Tident提供了 joins, aggregations, grouping, functions, 以及 filters等能力,所以使用它既可以完成聚合计算,连接计算,我们可以把它嵌入到blot里面,所以blot是处理逻辑,而Tident主要的作用就是提聚合操作的算子。
Trident的topology会被编译成尽可能高效的Storm topology。只有在需要对数据进行repartition的时候(如groupby或者shuffle)才会把tuple通过network发送出去,如果你有一个trident如下
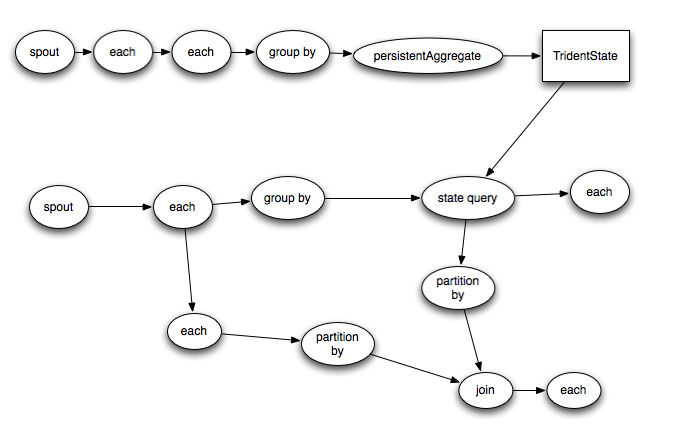

上图就是编译前与编译之后的运行图,也就是说,为了可以并发执行,尽量保证本地计算,编写生成新的拓扑运行。而需要网络传输的数据则进行shuffle操作(网络传输数据)。