前言
一直没有完整的看完一本关于java虚拟机的书,最近工作量稍微小了一些,打算从头到尾学习一本关于java虚拟机的书。本想着看《深入理解java虚拟机》,考虑再三,由于这本书是基于jdk1.7,便放弃了这一本,最后选择了《实战java虚拟机——JVM故障诊断与性能优化》
一、Java虚拟机的基本结构图
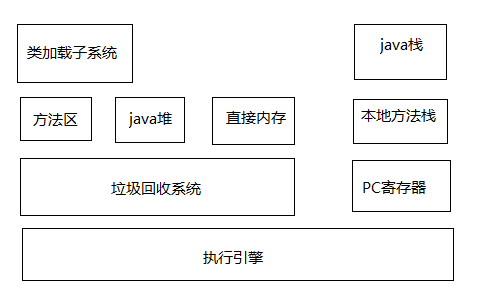
Java虚拟机的基本结构图如上所示
1.类加载子系统:负责从文件系统或网络中加载Class信息
2.方法区:存放加载的类信息,jdk1.7之前称为永久代(Perm),1.8之后为元数据区(Metaspace)
3.Java堆:在虚拟机启动时建立,几乎所有的Java对象实例都存在堆中,所有线程共享
4.直接内存:系统的直接内存区域,访问该部分的速度优于Java堆,在NIO被广泛使用后,直接内存的使用也非常普遍,直接内存使得Java程序可以跳过Java堆直接访问原生堆空间
5.垃圾回收系统:对方法区,Java堆和直接内存的垃圾对象进行回收
6.Java栈:每个线程都有一个私有的栈,栈中保存着帧信息,局部变量,方法参数,与方法调用和返回密切相关
7.本地方法栈:与Java栈类似,用于调用本地方法
8.PC寄存器:每个线程私有,任意时刻Java线程总在执行一个方法,如果是本地方法,PC寄存器的值是undefined,如果不是本地方法,PC寄存器会指向当前执行的指令
9.执行引擎:执行虚拟机的字节码
二、虚拟机的常用操作参数
1.虚拟机日志参数
-XX:+PrintGC(在jdk9.jdk10中建议使用-Xlog:gc),使用这个参数启动java虚拟机,则在GC时就会打印相应日志
-XX:+PrintGCDetails, 该参数可以打印堆的详细信息,描述各个区间的使用情况(jdk9,jdk10中使用-Xlog:gc*)
-XX:+PrintGCApplicationStoppedTime,可以打印应用程序由于GC产生的停顿时间
-Xloggc:log/gc.log,该命令可以在当前目录的log文件夹下gc.log文件中记录所有GC日志
2.类加载/卸载跟踪
-verbose:class可跟踪类的加载、卸载
-XX:+TraceClassLoading(jdk9,jdk10中使用-Xlog:class+load=info)跟踪类的加载
-XX:+TraceClassUnloading(jdk9,jdk10中使用-Xlog:class+unload=info)跟踪类的卸载
3.查看虚拟机参数
-XX:+PrintCommandLineFlags,可以打印传递给虚拟机的显式和隐式参数,隐式参数可能是虚拟机启动时自行设置
3.堆的配置参数
-Xms指定初始堆,-Xmx指定最大堆(示例:-Xmx20m -Xms5m,代表初始化堆5M,堆最大可用20M)
-Xmn指定新生代大小,一般建议设置为整个堆空间的1/3到1/4
-XX:SurvivorRatio,(示例:-XX:SurvivorRatio=2,代表eden:from=2:1)指定新生代中eden区和from/to区的比例。新生代区中,总可用新生代大小为(eden+from)或(eden+to),正常情况下from和to区的大小相同
-XX:NewRatio,老年代/新生代的比例
4.堆溢出处理
程序运行过程中,若堆空间不足,则会抛出OOM异常(Out Of Memory),Java虚拟机提供了两个参数
-XX:+HeapDumpOnOutOfMemoryError可以在内存溢出时导出整个堆的信息
-XX:HeapDumpPath,可以指定导出堆的存放路径(绝对路径)
5.方法区配置
jdk1.6和jdk1.7可以使用-XX:PermSize和-XX:MaxPermSize配置永久区的大小和最大永久区的大小
上文也提到过,jdk8开始,永久区已经彻底移除,使用元数据区存放类的元数据,默认情况下,元数据区只受系统可用内存限制,但是依旧可以用-XX:MaxMetaspaceSize指定最大可用值
6.栈配置
-Xss:指定线程的栈大小
7.虚拟机的工作模式
(1)Client模式
使用-client可以指定使用Client模式,该模式下启动较快,系统最大堆MaxHeapSize约为256MB,CompliThreshold默认为1500,即函数被调用1500次后,会进行JIT编译
(2)Server模式
使用-server可以指定使用server模式,该模式启动较慢,会尝试收集更多系统性能信息,使用更复杂的优化算法对程序进行优化,因此在系统完全启动后,Server模式会远快于Client模式。
该模式下系统最大堆MaxHeapSize约为1GB,CompliThreshold默认为10000