Natural Language Processing with Python
Charpter 6.1
1 import nltk 2 from nltk.corpus import brown 3 4 def pos_features(sentence,i,history): 5 features = {"suffix(1)":sentence[i][-1:], 6 "suffix(2)":sentence[i][-2:], 7 "suffix(3)":sentence[i][-3:]} 8 if i == 0: 9 features["prev-word"]="<STAR>" 10 features["prev_tag"] ="<STAR>" 11 else: 12 features["prev_word"]=sentence[i-1] 13 features["prev_tag"]=history[i-1] 14 return features 15 16 class ConsecutivePosTagger(nltk.TaggerI): 17 def __init__(self,train_sents): 18 train_set=[] 19 for tagged_sent in train_sents: 20 history=[] 21 untagged_sent = nltk.tag.untag(tagged_sent) 22 for i,(word,tag) in enumerate(tagged_sent): 23 featureset=pos_features(untagged_sent,i,history) 24 train_set.append((featureset,tag)) 25 history.append(tag) 26 self.classifier=nltk.NaiveBayesClassifier.train(train_set) 27 28 def tag(self,sentence): 29 history=[] 30 for i,word in enumerate(sentence): 31 featureset=pos_features(sentence,i,history) 32 tag=self.classifier.classify(featureset) 33 history.append(tag) 34 return zip(sentence,history) 35 36 def test_ConsecutivePosTagger(): 37 tagged_sents=brown.tagged_sents(categories='news') 38 size = int(len(tagged_sents) * 0.1) 39 train_sents, test_sents = tagged_sents[size:], tagged_sents[:size] 40 tagger = ConsecutivePosTagger(train_sents) 41 42 print tagger.evaluate(test_sents)
流程为:
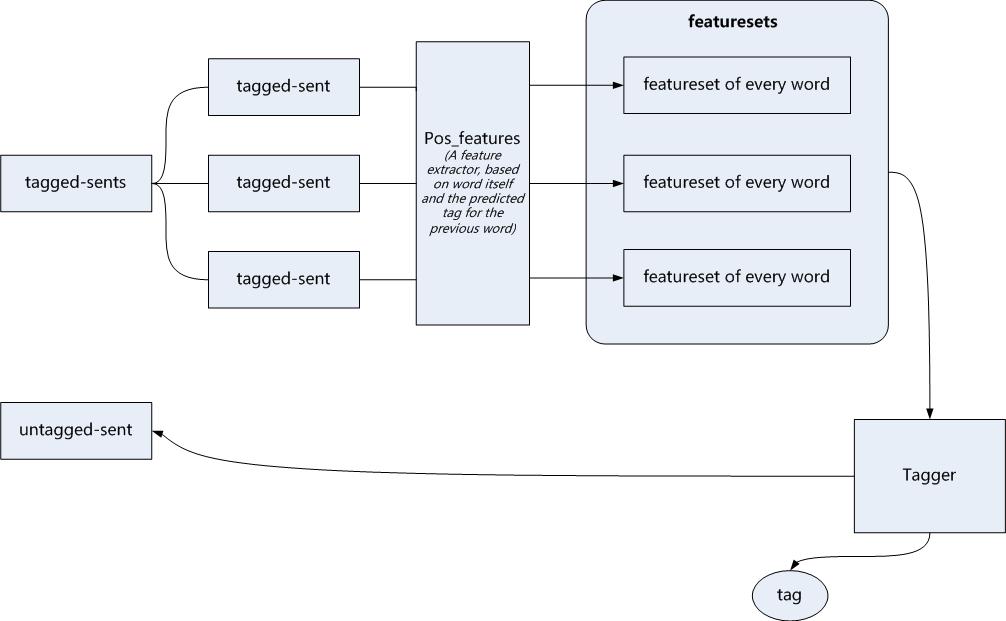
结果为:
0.796940194715