1、项目环境
Python 3.7
MySQL 5.6
Pycharm 2020
2、项目目录

crawl_blogs.py 爬虫主文件
mysql_db.py mysql 连接 增删改工具
result.txt 爬取的内容 存储文件
uploads 下载的文件目录
3、数据库连接 mysql_db.py
import pymysql; readHost = '127.0.0.1' writeHost = '110.1.58.75' userName = 'root' passWord = 'abc@123456' dataBase = 'py_db' charset = 'utf8' #读写数据库 type 1 读库 2 写库 def run_sql(sql,dbtype=''): try: if dbtype == '': host = readHost else: host = writeHost db = pymysql.connect(host,userName,passWord,dataBase,3306,None,charset) except: print('数据库连接失败,请重试') # 使用 cursor() 方法创建一个游标对象 cursor cursor = db.cursor() result = () try: # 执行sql语句 cursor.execute(sql) if dbtype == 'fetchall': # 获取所有记录列表 result = cursor.fetchall() elif dbtype == 'fetchone': # 使用 fetchone() 方法获取单条数据. result = cursor.fetchone() elif dbtype == '': # 提交到数据库执行 增,删,改 db.commit() except: db.rollback()#发生错误时回滚 print("Error: unable to fetch data") # 关闭数据库连接 db.close() return result
4、爬取程序主文件 crawl_blogs.py (以爬取博客为例)
import json import requests from requests.exceptions import RequestException import re import time import mysql_db import urllib import os import random save_path = 'result.txt' #获取某一页的内容 def get_one_page(url): try: response = requests.get(url) if response.status_code == 200: return response.text return None except RequestException: return None #处理文件路径,相对路径转绝对 def get_file_path(file_url,prefix=''): if file_url.startswith('/https://') or file_url.startswith('/http://'): return file_url.lstrip('/') else: return prefix+file_url #解析当前页html def parse_one_page(html): pattern = re.compile('<div class="row b-one-article">.*?"col-xs-12 col-md-12 col-lg-12".*?<a class="b-oa-title".*?href="(.*?)".*?>(.*?)</a>.*?<li class="col-xs-7 col-md-3 col-lg-3">.*?<i class="fa fa-calendar"></i>(.*?)</li>.*?<div class="col-xs-12 col-md-12 col-lg-12">.*?<img class="bjy-lazyload".*?data-src="(.*?)".*?>.*?</div>', re.S) items = re.findall(pattern, html) if items: for item in items: yield { 'href': item[0], 'title': item[1], 'time': item[2].strip()[2:],#去除换行符 # 'img_url': item[3] if item[3].find('://') != -1 else 'https://baijunyao.com/'+item[3] 'img_url': get_file_path(item[3],'https://baijunyao.com/') } #写入数据到文件 def write_to_file(content): with open(save_path, 'a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) + ' ') #循环爬取 def main(offset): url = 'https://baijunyao.com/?page=' + str(offset) html = get_one_page(url) for item in parse_one_page(html): print(item) write_to_file(item) #读取文件并入库 def save_to_db(filepath): f = open(filepath,'rb') # lines = f.readlines()#读取全部内容 # for line in lines: date = time.strftime('%Y%m%d') save_dir = os.path.abspath('.')+'/uploads/article/'+str(date)+'/' #目录不存在 则创建目录 if not os.path.exists(save_dir): os.makedirs(save_dir) begin_time = time.time() i = 0 for line in f: i+=1 item = line.decode() item = json.loads(item) href = item['href'] title = item['title'] insert_time = item['time'] timeArray = time.strptime(insert_time, "%y-%m-%d %H:%M:%S")# 转换成时间数组 insert_time = int(time.mktime(timeArray))# 转换成时间戳 img_url = item['img_url'] #下载图片 img_suffix = os.path.splitext(img_url)[-1] #获取文件后缀 file_name = str(int(time.time()))+'_'+str(random.randint(1000,9999))+img_suffix urllib.request.urlretrieve(img_url,save_dir+file_name) sql = "INSERT INTO blogs(title,href,insert_time,update_time,img_url) values('%s','%s',%d,%d,'%s')" %(title,href,insert_time,insert_time,img_url) print(sql) mysql_db.run_sql(sql) end_time = time.time() use_time = end_time-begin_time print('入库完毕,共计'+(str)(i)+'条,耗时:'+str(use_time)+'秒') if __name__ == '__main__': #爬取数据并保存到文件 begin_time = time.time() for i in range(1,28): main(i) #time.sleep(1) #读取文件并入库 end_time = time.time() use_time = end_time-begin_time print('爬取完毕,共耗时:'+str(use_time)+'秒') save_to_db(save_path)
5、爬取结果
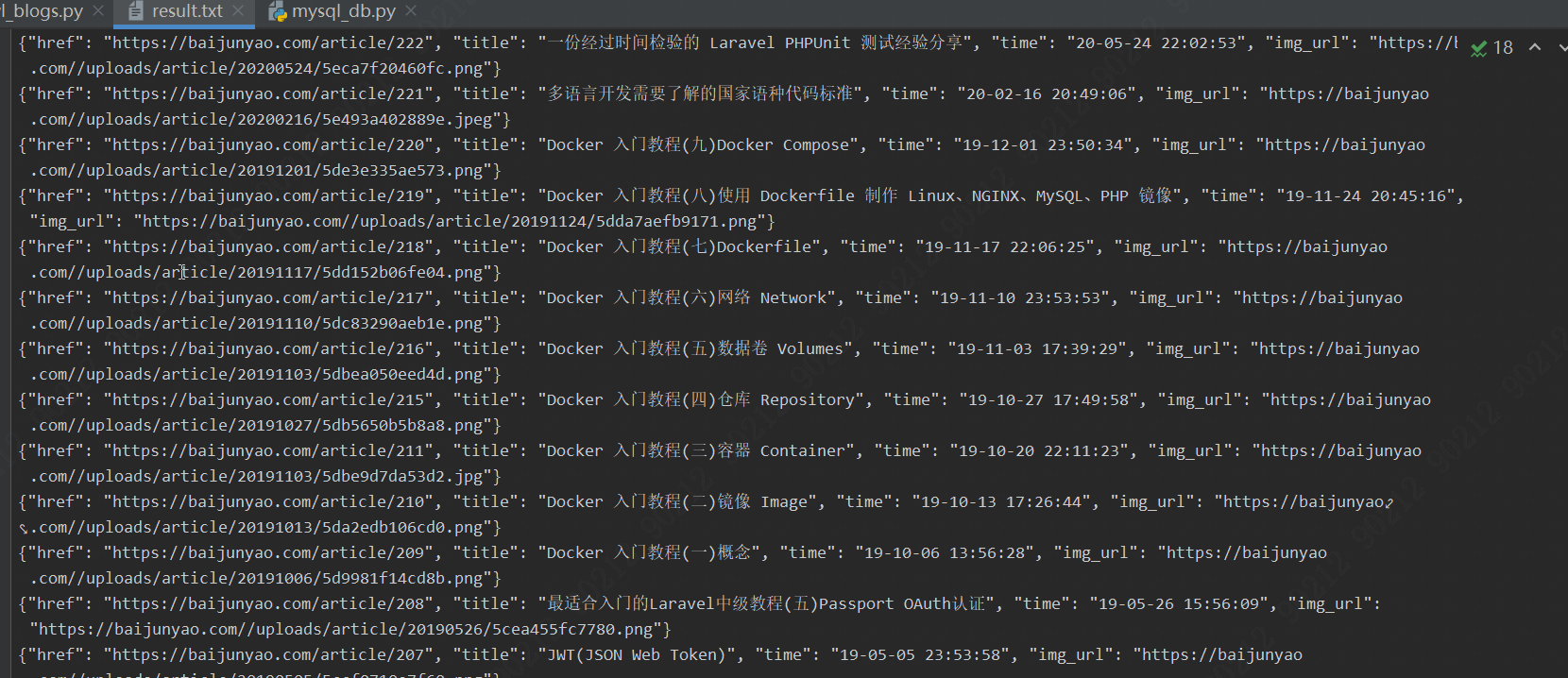
6、下载的博客封面图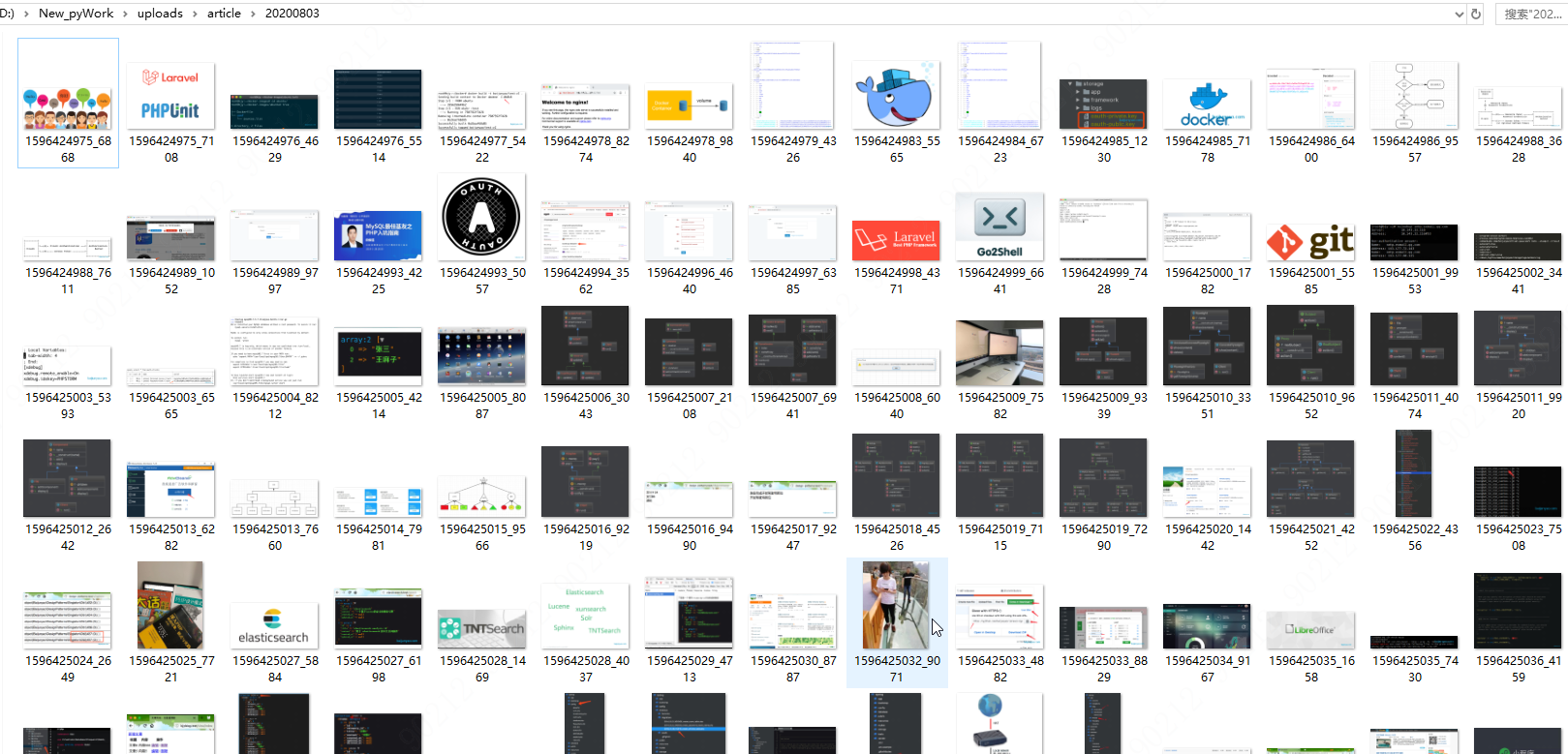
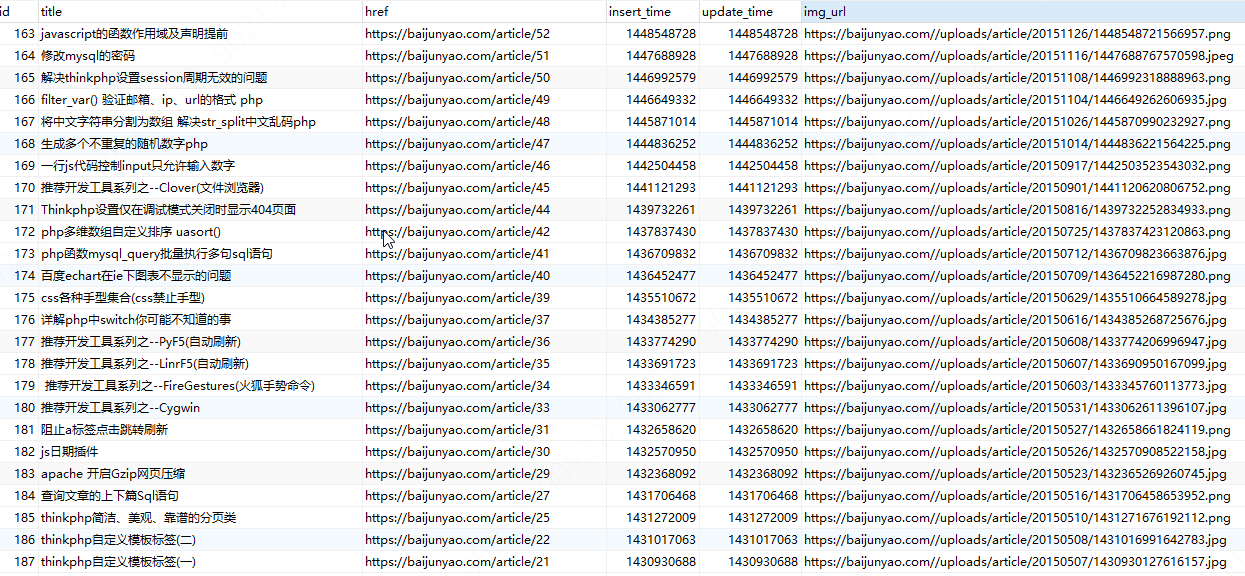
7、数据表存储