Hive本身是建立在Hadoop之上的用于处理结构化数据的数据仓库基础工具。它提供一系列的工具用于数据提取、转化、分析、加载。其提供类SQL语言HQL用于处理存储在Hadoop上的海量数据。所以,数据是在HDFS上,计算是MR/Spark,Hive自身并没有承担过多的压力。Hive不需要做集群。
1、软件环境:
centos6.8:sparknode1、sparknode2、sparknode3、sparknode4
hadoop版本:2.7.5
zookeeper版本:3.4.11
hbase版本:1.4.0
2、搭建了4台Hadoop+hdfs+hbase,名称分别是Sparknode1(master),Sparknode2,Sparknode3,Sparknode4。搭建了三台zookeeper集群,名称分别是zookeeper1,zookeeper2,zookeeper3。这里我没有使用hbase自带的zookeeper集群,而是自己搭建了另外一套zookeeper集群。
3、下载Hive安装包:
http://www.trieuvan.com/apache/hive/hive-2.3.2/
4、用RZ命令上传至centos后将其解压:
tar -zxvf apache-hive-2.3.2-bin.tar.gz

5、配置环境变量:
vim /etc/profile
export HIVE_HOME=/usr/soft/apache-hive-2.3.2-bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export CLASSPATH=$CLASSPATH:$HIVE_HOME/lib
export PATH=$PATH:$HIVE_HOMW/bin

source /etc/profile
6、配置Mysql:
(1)、查看已安装的mysql服务:
rpm -qa | grep mysql

(2)、卸载Centos自带的mysql:
rpm -e mysql-5.1.73-8.el6_8.x86_64 --nodeps
(3)、下载mysql:
yum -y install mysql-server
(4)、初始化mysql
a.修改mysql的密码(root权限执行)
cd /usr/bin
./mysql_secure_installation
b.输入当前MySQL数据库的密码为root, 初始时root是没有密码的,所以直接回车
Enter current password for root (enter for none):
c.设置MySQL中root用户的密码(应与下面Hive配置一致,下面设置为123456)
Set root password? [Y/n] Y
New password:
Re-enter new password:
Password updated successfully!
Reloading privilege tables..
... Success!
d.删除匿名用户
Remove anonymous users? [Y/n] Y
... Success!
e.是否不允许用户远程连接,选择N
Disallow root login remotely? [Y/n] N
... Success!
f.删除test数据库
Remove test database and access to it? [Y/n] Y
Dropping test database...
... Success!
Removing privileges on test database...
... Success!
g.重装
Reload privilege tables now? [Y/n] Y
... Success!
h.完成
All done! If you've completed all of the above steps, your MySQL
installation should now be secure.
Thanks for using MySQL!
i.登陆mysql
mysql -uroot -p
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123' WITH GRANT OPTION;
FLUSH PRIVILEGES;
exit;
7、配置Hive
(1)、将hive-env.sh.template文件复制为hive-env.sh, 编辑hive-env.sh文件,配置如下:
cp hive-env.sh.template hive-env.sh
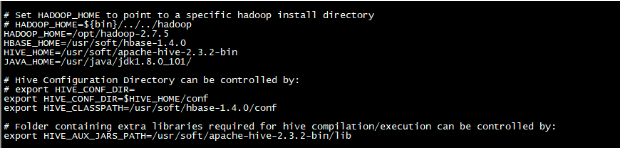
(2)、将hive-default.xml.template文件拷贝为hive-site.xml, 并编辑hive-site.xml文件(删除所有内容,只留一个<configuration></configuration>)
cp hive-default.xml.template hive-site.xml
配置如下:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>mysql</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateColumns</name>
<value>true</value>
</property>
<!-- 设置 hive仓库的HDFS上的位置 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive</value>
<description>location of default database for the warehouse</description>
</property>
<!--资源临时文件存放位置 -->
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/soft/apache-hive-2.3.2-bin/tmp_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<!-- Hive在0.9版本之前需要设置hive.exec.dynamic.partition为true, Hive在0.9版本之后默认为true -->
<property>
<name>hive.exec.dynamic.partition</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<!-- 修改日志位置 -->
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/soft/apache-hive-2.3.2-bin/log/HiveJobsLog</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/soft/apache-hive-2.3.2-bin/log/ResourcesLog</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/usr/soft/apache-hive-2.3.2-bin/log/HiveRunLog</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
...skipping...
<value>/usr/soft/apache-hive-2.3.2-bin/log/OpertitionLog</value>
<description>Top level directory where operation tmp are stored if logging functionality is enabled</description>
</property>
<!-- 配置HWI接口 -->
<property>
<name>hive.hwi.war.file</name>
<value>/usr/soft/apache-hive-2.3.2-bin/lib/hive-hwi-2.1.1.jar</value>
<description>This sets the path to the HWI war file, relative to ${HIVE_HOME}. </description>
</property>
<property>
<name>hive.hwi.listen.host</name>
<value>master</value>
<description>This is the host address the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>This is the port the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>master</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.http.port</name>
<value>10001</value>
</property>
<property>
<name>hive.server2.thrift.http.path</name>
<value>cliservice</value>
</property>
<!-- HiveServer2的WEB UI -->
<property>
<name>hive.server2.webui.host</name>
<value>master</value>
</property>
<property>
<name>hive.server2.webui.port</name>
<value>10002</value>
</property>
<property>
<name>hive.scratch.dir.permission</name>
<value>755</value>
</property>
<!-- 下面hive.aux.jars.path这个属性里面你这个jar包地址如果是本地的记住前面要加file://不然找不到, 而且会报org.apache.hadoop.hive.contrib.serde2.RegexSerDe错误 -->
<property>
<name>hive.aux.jars.path</name>
<value>file:///opt/spark-2.1.2-bin-hadoop2.7/jars</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<property>
<name>hive.auto.convert.join</name>
<value>false</value>
</property>
<property>
<name>spark.dynamicAllocation.enabled</name>
<value>true</value>
<description>动态分配资源</description>
</property>
<!-- 使用Hive on spark时,若不设置下列该配置会出现内存溢出异常 -->
<property>
<name>spark.driver.extraJavaOptions</name>
<value>-XX:PermSize=128M -XX:MaxPermSize=512M</value>
</property>
</configuration>
8、配置日志地址,将hive-log4j2.properties.template文件复制为hive-log4j2.properties, 编辑hive-log4j2.properties文件,配置如下:
cp hive-log4j2.properties.template hive-log4j2.properties
vim hive-log4j2.properties

9、配置$HIVE_HOME/conf/hive-config.sh文件:
## 增加以下三行
export JAVA_HOME=/home/centos/soft/java
export HIVE_HOME=/home/centos/soft/hive
export HADOOP_HOME=/home/centos/soft/hadoop
## 修改下列该行
HIVE_CONF_DIR=$HIVE_HOME/conf
10、将JDBC的jar包放入$HIVE_HOME/lib目录下:
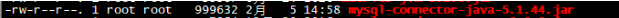
11、将$HIVE_HOME/lib目录下的jline-2.12.jar包拷贝到$HADOOP_HOME/share/hadoop/yarn/lib目录下,并删除$HADOOP_HOME/share/hadoop/yarn/lib目录下旧版本的jline包
12、复制$JAVA_HOME/lib目录下的tools.jar到$HIVE_HOME/lib下
cp $JAVA_HOME/lib/tools.jar ${HIVE_HOME}/lib
13、执行初始化Hive操作
选用MySQLysql和Derby二者之一为元数据库
注意:先查看MySQL中是否有残留的Hive元数据,若有,需先删除
schematool -dbType mysql -initSchema ## MySQL作为元数据库
其中mysql表示用mysql做为存储hive元数据的数据库, 若不用mysql做为元数据库, 则执行
schematool -dbType derby -initSchema ## Derby作为元数据库
脚本hive-schema-1.2.1.mysql.sql会在配置的Hive元数据库中初始化创建表
14、启动Metastore服务:
hive

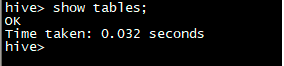
15、测试:
show databases;

show tables;