转载:http://www.cnblogs.com/LexMoon/p/wave-c.html
1.C语言解析WAV音频文件
代码地址: Github : https://github.com/CasterWx/c-wave-master
在计算机中有着各式各样的文件,比如说EXE这种可执行文件,JPG这种图片文件,也有我们平时看的TXT,或者C,CPP,PHP等代码文件。
如果把这些文件用记事本或者其他纯文本编辑器打开,会发现前面这类文件打开之后基本上都是乱码,也就是非人类可读的字符,而后面这类代码或者TXT文件打开之后都是人类可读的字符串。
如果我们把这些文件统一做一个分类,那么前面的EXE,JPG之类的这种打开之后都是我们看不懂的外星球文字的文件叫做二进制文件,而后面那些文件可以称为是文本文件。
后面那种分类是文本文件很好理解,毕竟都是我们认识的文本文字,但是前面的那些乱码为什么叫他二进制文件呢?这些二进制文件是怎么被计算机识别的,为什么这些乱码就能被计算机识别,并且放出悠扬动听的音乐或者栩栩如生的图片呢?我们学编程,搞计算机的人能不能也自己写一个程序把这些数据解析出来呢?请跟听本专栏栏猪一起慢慢道来。
2.前言
我们将一步一步来了解C语言的一些基本库的使用,以及如何使用这些库来解析一个wav格式的音频文件,将其中的元数据(也就是该音频文件的一些属性)提取出来。因此您需要有基本的计算机基础知识以及了解C语言,最好还对音频或者信号处理感兴趣。
2.1.了解WAV音频文件
下面是百度百科的解释
WAV为微软公司(Microsoft)开发的一种声音文件格式,它符合RIFF(Resource Interchange File Format)文件规范,用于保存Windows平台的音频信息资源,被Windows平台及其应用程序所广泛支持,该格式也支持MSADPCM,CCITT A LAW等多种压缩运算法,支持多种音频数字,取样频率和声道,标准格式化的WAV文件和CD格式一样,也是44.1K的取样频率,16位量化数字,因此在声音文件质量和CD相差无几! WAV打开工具是WINDOWS的媒体播放器。
通常使用三个参数来表示声音,量化位数,取样频率和采样点振幅。量化位数分为8位,16位,24位三种,声道有单声道和立体声之分,单声道振幅数据为n1矩阵点,立体声为n2矩阵点,取样频率一般有11025Hz(11kHz) ,22050Hz(22kHz)和44100Hz(44kHz) 三种,不过尽管音质出色,但在压缩后的文件体积过大!相对其他音频格式而言是一个缺点,其文件大小的计算方式为:WAV格式文件所占容量(B) = (取样频率 X量化位数X 声道) X 时间 / 8 (字节= 8bit) 每一分钟WAV格式的音频文件的大小为10MB,其大小不随音量大小及清晰度的变化而变化。
我们通常在各种音乐播放器中下载歌曲的时候会看到各种参数,比如说普通音质的码流为128k,高品质是320k,还有无损的APE,FLAC等格式。还有的时候我们在使用各种音频格式转换工具中会遇到各种参数,比如说采样率,量化精度,以及该音频文件是单声道还是双声道等等。
我们现在都是听MP3格式的音乐,WAV现在除了Windows的录音机以外,基本上没有地方会用了,为什么还要用他来做示例呢?这是因为WAV本质上是无压缩的原始音频文件,而且他的文件结构不算非常复杂,因此可以作为我们初学者的学习示例格式。你可以按照同样的思路自己去学习其他格式。
2.2什么是二进制文件
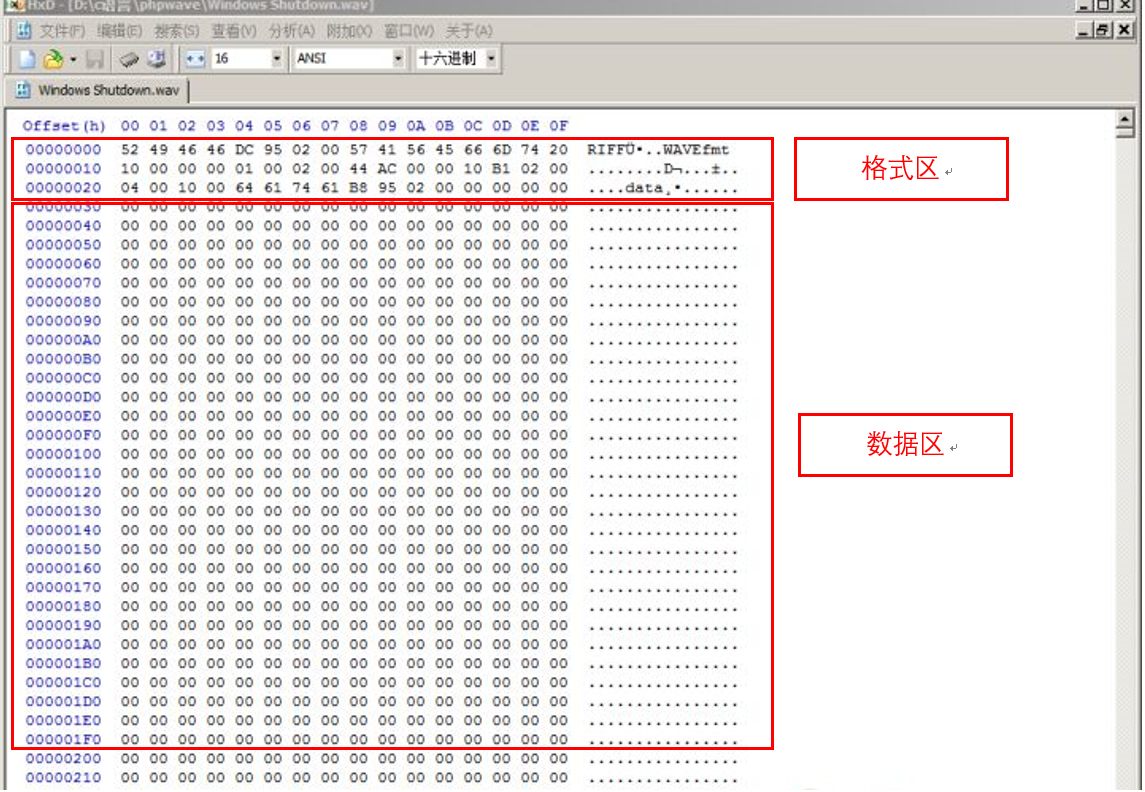
二进制文件,本质上就是一种使用二进制方式存储文件内容的文件统称,我们前面有讲过使用记事本等工具打开之后看到的是乱码,那么我们怎么分析他呢,可以使用UltraEditor,HxD,C32Asm等等。比如我这里使用HxD打开Windows 7的关机音乐(C:WindowsMediaWindows Shutdown.wav)就是这个样子,左边就是这个WAV音频文件的二进制表示,右边则是这个二进制数字对应的ASCII表示,由于像00之类的数字在ASCII中并没有有效的图像来显示,所以在这个界面的右边显示的就是一个点。而左边这些52,49之类的数字分别对应什么呢?其实这些二进制数字看似乱码,其实都是有一定的规范的,只要我们或者我们计算机上面的应用程序了解这个规范,就可以按照这个规范去解读它。
3.WAV的二进制格式解析
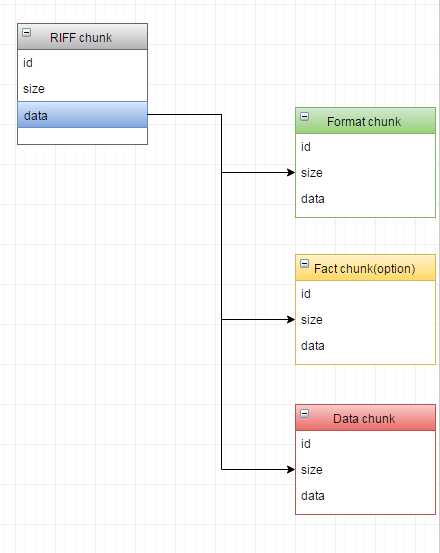
根据网络上的各种资料可以得知WAVE文件本质上就是一种RIFF格式,它可以抽象成一颗树(数据结构的一种)来看。

我们看到这张图上面,从上到下分别对应着二进制数据在文件中相对于起始位置的偏移量。每一个格子对应一个字段,field size表示每个字段所占据的大小,根据这个大小以及当前的偏移量,我们也可以计算出下一个字段的起始地址(偏移量)。
WAV 是Microsoft开发的一种音频文件格式,它符合上面提到的RIFF文件格式标准,可以看作是RIFF文件的一个具体实例。既然WAV符合RIFF规范,其基本的组成单元也是chunk。一个WAV文件通常有三个chunk以及一个可选chunk,其在文件中的排列方式依次是:RIFF chunk,Format chunk,Fact chunk(附加块,可选),Data chunk。各个chunk中字段的意义如下:
3.1 RIFF chunk
根据RIFF的规范,整个WAV文件的顶级chunk(数据块)就是最顶上的ChunkID为RIFF的这个chunk,这也可以解释为什么之前那张图片中我们可以看出wav文件开头都是RIFF几个字母。而接下来的ChunkSize则表示这个chunk下的那些子chunk的大小,如果按照“树结构”来理解,那么每一个子chunk(Subchunk)则为树的树枝。而Format则为这个chunk的实际数据。
说白了一个chunk结构其实就是三个部分,第一个部分标识符用于说明这个chunk是存什么内容的,第二个部分则是说明这个chunk的内容到底有多大,用于让程序知道如果要找到下一个chunk该把地址偏移多少去读取,而第三个部分则是实际内容。
- RIFF chunk
- id
FOURCC 值为'R' 'I' 'F' 'F' - size
其data字段中数据的大小 字节数 - data
包含其他的chunk
- id
3.2 第一个子chunk-fmt
好了说完了顶级chunk,我们就来看看子chunk,第一个子chunk的Subchunk1ID在WAV文件中恒定为fmt,表示该subchunk的内容为该WAV音频文件的一些元数据,也就是该WAV音频的一些格式信息。比如说AudioFormat这个字段一般为1,表示这个WAV音频为PCM编码。NumChannels则是该WAV音频文件的声道数量。SampleRate则为采样率,ByteRate则为采样率。BlockAlign则是每个block的平均大小,它等于NumChannels * BitsPerSample/8,至于block是什么,以及它的计算公式是怎么得来的需要来看看另一个Subchunk。BitsPerSample则为每秒采样比特,有的地方称它为量化精度或者PCM位宽。(未考究)
- Format chunk
- id
FOURCC 值为 'f' 'm' 't' ' ' - size
数据字段包含数据的大小。如无扩展块,则值为16;有扩展块,则值为= 16 + 2字节扩展块长度 + 扩展块长度或者值为18(只有扩展块的长度为2字节,值为0) - data
存放音频格式、声道数、采样率等信息- format_tag
2字节,表示音频数据的格式。如值为1,表示使用PCM格式。 - channels
2字节,声道数。值为1则为单声道,为2则是双声道。 - samples_per_sec
采样率,主要有22.05KHz,44.1kHz和48KHz。 - bytes_per sec
音频的码率,每秒播放的字节数。samples_per_sec * channels * bits_per_sample / 8,可以估算出使用缓冲区的大小 - block_align
数据块对齐单位,一次采样的大小,值为声道数 * 量化位数 / 8,在播放时需要一次处理多个该值大小的字节数据。 - bits_per_sample
音频sample的量化位数,有16位,24位和32位等。 - cbSize
扩展区的长度 - 扩展块内容
22字节,具体介绍,后面补充。
- format_tag
- id
3.3 第二个子chunk-data(附加块,可选)
采用压缩编码的WAV文件,必须要有Fact chunk,该块中只有一个数据,为每个声道的采样总数。
- Fact chunk
- id
FOURCC 值为 'f' 'a' 'c' 't' - size
数据域的长度,4(最小值为4) - 采样总数 4字节
- id
3.4 第三个子chunk-data
另一个子chunk也就是Subchunk2ID是在WAV文件中恒定为data,也就是这个WAV音频文件的实际音频数据,说专业一点,这里面存储的是音频的采样数据。但是我们的音频如果是双声道,那么实际上某一个采样时刻采样的数据是由左声道和右声道共同组成的。而这个共同组成的采样我们把他成为block。前面有讲到BlockAlign = NumChannels * BitsPerSample / 8,这个现在就很好理解了,至于为什么末尾要除以8,这是因为计算机中是以8个二进制数表示一个字节,所以要除以8来求出字节数。
至于音频的持续长度,我们可以通过Subchunk2Size除以ByteRate,也就是实际音频data的chunk总长度除以每秒字节数得到持续多少秒。
- Data chunk
- id
FOURCC 值为'd' 'a' 't' 'a' - size
数据域的长度 - data
具体的音频数据存放在这里
- id
4.C语言解析WAV音频文件
前面讲了这么多,现在问题来了,怎么编程来实现解析上面所说的这些元数据呢。C语言基本的二进制文件操作函数有fopen,fread等等。(注意是二进制文件操作函数,所以我们不讨论fgets,这是普通的文本文件操作函数)
4.1 fopen(打开文件)
相关函数
open,fclose
表头文件
#include<stdio.h>
定义函数
FILE * fopen(const char * path,const char * mode);
函数说明
返回值文件顺利打开后,指向该流的文件指针就会被返回。
参数path字符串包含欲打开的文件路径及文件名,参数mode字符串则代表着流形态。
mode有下列几种形态字符串:
r 打开只读文件,该文件必须存在。
r+ 打开可读写的文件,该文件必须存在。
w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
w+ 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留。
a+ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。
上述的形态字符串都可以再加一个b字符,如rb、w+b或ab+等组合,加入b字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件。
不过在POSIX系统,包含Linux都会忽略该字符。由fopen()所建立的新文件会具有S_IRUSR|S_IWUSR|S_IRGRP|S_IWGRP|S_IROTH|S_IWOTH(0666)权限,此文件权限也会参考umask 值。 返回值文件顺利打开后,指向该流的文件指针就会被返回。若果文件打开失败则返回NULL,并把错误代码存在errno 中。
附加说明
一般而言,打开文件后会作一些文件读取或写入的动作,若打开文件失败,接下来的读写动作也无法顺利进行,所以一般在fopen()后作错误判断及处理
例:
#include<stdio.h> main() { FILE * fp; fp=fopen(“noexist”,”a+”); if(fp= =NULL) return; fclose(fp); }
4.2 fread和fwrite
用来读写一个数据块。
一般调用形式
fread(buffer,size,count,fp);
fwrite(buffer,size,count,fp);
说明
如果调用成功返回实际读取到的项个数(小于或等于count),如果不成功或读到文件末尾返回 0
(1)buffer:是一个指针,对fread来说,它是读入数据的存放地址。对fwrite来说,是要输出数据的地址。
(2)size:要读写的字节数;
(3)count:要进行读写多少个size字节的数据项;
(4)fp:文件型指针。
注意:
1 完成次写操(fwrite())作后必须关闭流(fclose());
2 完成一次读操作(fread())后,如果没有关闭流(fclose()),则指针(FILE * fp)自动向后移动前一次读写的长度,不关闭流继续下一次读操作则接着上次的输出继续输出;
4.3 完整代码
代码如下:
wave.c
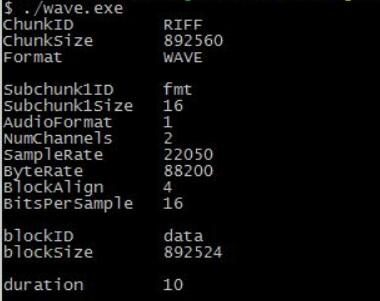
 wave.c#include <stdio.h> #include <stdint.h> #include <stdlib.h> #include "wave.h" int main() { FILE *fp = NULL; Wav wav; RIFF_t riff; FMT_t fmt; Data_t data; fp = fopen("test.wav", "rb"); if (!fp) { printf("can't open audio file "); exit(1); } fread(&wav, 1, sizeof(wav), fp); riff = wav.riff; fmt = wav.fmt; data = wav.data; printf("ChunkID %c%c%c%c ", riff.ChunkID[0], riff.ChunkID[1], riff.ChunkID[2], riff.ChunkID[3]); printf("ChunkSize %d ", riff.ChunkSize); printf("Format %c%c%c%c ", riff.Format[0], riff.Format[1], riff.Format[2], riff.Format[3]); printf(" "); printf("Subchunk1ID %c%c%c%c ", fmt.Subchunk1ID[0], fmt.Subchunk1ID[1], fmt.Subchunk1ID[2], fmt.Subchunk1ID[3]); printf("Subchunk1Size %d ", fmt.Subchunk1Size); printf("AudioFormat %d ", fmt.AudioFormat); printf("NumChannels %d ", fmt.NumChannels); printf("SampleRate %d ", fmt.SampleRate); printf("ByteRate %d ", fmt.ByteRate); printf("BlockAlign %d ", fmt.BlockAlign); printf("BitsPerSample %d ", fmt.BitsPerSample); printf(" "); printf("blockID %c%c%c%c ", data.Subchunk2ID[0], data.Subchunk2ID[1], data.Subchunk2ID[2], data.Subchunk2ID[3]); printf("blockSize %d ", data.Subchunk2Size); printf(" "); printf("duration %d ", data.Subchunk2Size / fmt.ByteRate); }
wave.c#include <stdio.h> #include <stdint.h> #include <stdlib.h> #include "wave.h" int main() { FILE *fp = NULL; Wav wav; RIFF_t riff; FMT_t fmt; Data_t data; fp = fopen("test.wav", "rb"); if (!fp) { printf("can't open audio file "); exit(1); } fread(&wav, 1, sizeof(wav), fp); riff = wav.riff; fmt = wav.fmt; data = wav.data; printf("ChunkID %c%c%c%c ", riff.ChunkID[0], riff.ChunkID[1], riff.ChunkID[2], riff.ChunkID[3]); printf("ChunkSize %d ", riff.ChunkSize); printf("Format %c%c%c%c ", riff.Format[0], riff.Format[1], riff.Format[2], riff.Format[3]); printf(" "); printf("Subchunk1ID %c%c%c%c ", fmt.Subchunk1ID[0], fmt.Subchunk1ID[1], fmt.Subchunk1ID[2], fmt.Subchunk1ID[3]); printf("Subchunk1Size %d ", fmt.Subchunk1Size); printf("AudioFormat %d ", fmt.AudioFormat); printf("NumChannels %d ", fmt.NumChannels); printf("SampleRate %d ", fmt.SampleRate); printf("ByteRate %d ", fmt.ByteRate); printf("BlockAlign %d ", fmt.BlockAlign); printf("BitsPerSample %d ", fmt.BitsPerSample); printf(" "); printf("blockID %c%c%c%c ", data.Subchunk2ID[0], data.Subchunk2ID[1], data.Subchunk2ID[2], data.Subchunk2ID[3]); printf("blockSize %d ", data.Subchunk2Size); printf(" "); printf("duration %d ", data.Subchunk2Size / fmt.ByteRate); }

wave.h
wave.htypedef struct WAV_RIFF { /* chunk "riff" */ char ChunkID[4]; /* "RIFF" */ /* sub-chunk-size */ uint32_t ChunkSize; /* 36 + Subchunk2Size */ /* sub-chunk-data */ char Format[4]; /* "WAVE" */ } RIFF_t; typedef struct WAV_FMT { /* sub-chunk "fmt" */ char Subchunk1ID[4]; /* "fmt " */ /* sub-chunk-size */ uint32_t Subchunk1Size; /* 16 for PCM */ /* sub-chunk-data */ uint16_t AudioFormat; /* PCM = 1*/ uint16_t NumChannels; /* Mono = 1, Stereo = 2, etc. */ uint32_t SampleRate; /* 8000, 44100, etc. */ uint32_t ByteRate; /* = SampleRate * NumChannels * BitsPerSample/8 */ uint16_t BlockAlign; /* = NumChannels * BitsPerSample/8 */ uint16_t BitsPerSample; /* 8bits, 16bits, etc. */ } FMT_t; typedef struct WAV_data { /* sub-chunk "data" */ char Subchunk2ID[4]; /* "data" */ /* sub-chunk-size */ uint32_t Subchunk2Size; /* data size */ /* sub-chunk-data */ // Data_block_t block; } Data_t; //typedef struct WAV_data_block { //} Data_block_t; typedef struct WAV_fotmat { RIFF_t riff; FMT_t fmt; Data_t data; } Wav;
执行结果
4.4两个细节
1、fopen的时候我们的mode要设置为"rb",r表示read,b表示binary,也就是二进制读取方式。这一点是和读取传统的文本文件格式有所区别的。
2、struct类型里面我用的是uint32_t等类型,而不是传统的int,short等等,这是为了考虑到不同的编译器,不同的平台下对于int类型分配的内存空间不一致的问题。而这些类型是由stdint.h头文件提供的,因此我们需要在头部导入它。
5.fcm文件转WAV文件
PCM(Pulse Code Modulation----脉码调制录音)。所谓PCM录音就是将声音等模拟信号变成符号化的脉冲列,再予以记录。PCM信号是由[1]、[0]等符号构成的数字信号,而未经过任何编码和压缩处理。与模拟信号比,它不易受传送系统的杂波及失真的影响。动态范围宽,可得到音质相当好的影响效果。
在Windows平台下,基于PCM编码的WAV是被支持得最好的音频格式,所有音频软件都能完美支持,由于本身可以达到较高的音质的要求,因此,WAV也是音乐编辑创作的首选格式,适合保存音乐素材。因此,基于PCM编码的WAV被作为了一种中介的格式,常常使用在其他编码的相互转换之中,例如MP3转换成WMA。
简单一句,PCM就是没有压缩的格式。
pcm 是没有头信息的,wav有44字节的头文件,pcm文件转wav在开始位置加44字节头文件即可
代码如下:
fcm转wav转换函数
fcm转wav/* * fptr:要转的文件指针 * WriteWaveHeader(FILE *fptr,Uint32 num):向fptr文件中写入WAV所需的头文件 * WriteWaveFile(FILE *fptr,Uint32 num,short *ptr): */ void WriteWaveHeader(FILE *fptr,Uint32 num) { WAVE_HEADER WaveHeader; FORMAT WaveFormat; DATA WaveData; /**************RIFF chunk 参数定义*********************/ WaveHeader.riffid[0]='R'; //ChunkID WaveHeader.riffid[1]='I'; WaveHeader.riffid[2]='F'; WaveHeader.riffid[3]='F'; WaveHeader.dwSize=num*BYTES_EACH_SAMPLE+36; //ChunkSize WaveHeader.riffType[0]='W'; //Format WaveHeader.riffType[1]='A'; WaveHeader.riffType[2]='V'; WaveHeader.riffType[3]='E'; /**************fmt chunk 参数定义**********************/ WaveFormat.fccid[0]='f'; //SubChunkID WaveFormat.fccid[1]='m'; WaveFormat.fccid[2]='t'; WaveFormat.fccid[3]=' '; WaveFormat.dwSize=16; //SubChunkSize WaveFormat.wFormatTag=1; //AudioFormat WaveFormat.wChannels=CHANNEL_NUN; //NumChannels WaveFormat.dwSamplesPerSec=SAMPLE_RATE; //SampleRate WaveFormat.dwAvgBytePerSec=BYTES_EACH_SAMPLE*SAMPLE_RATE*CHANNEL_NUN; //ByteRate WaveFormat.wBlockAlign=BYTES_EACH_SAMPLE; //BlockAlign WaveFormat.uiBitsPerSample=QUANTIZATION; //BitsPerSample /**************Data chunk 参数定义**********************/ WaveData.fccid[0]='d'; //BlockID WaveData.fccid[1]='a'; WaveData.fccid[2]='t'; WaveData.fccid[3]='a'; WaveData.dwSize=num*BYTES_EACH_SAMPLE; //BlockSize fwrite(&WaveHeader,sizeof(WAVE_HEADER),1,fptr); fwrite(&WaveFormat,sizeof(FORMAT),1,fptr); fwrite(&WaveData,sizeof(DATA),1,fptr); } void WriteWaveFile(FILE *fptr,Uint32 num,short *ptr) { WriteWaveHeader(fptr,num); //向fptr指向的wav文件写入wav标准头文件 fwrite(buffer,sizeof(short),num,fptr); //向fptr指向的wav文件写入buffer指向的fcm源文件 }
主函数:
main#include "wav.h" FILE *frpcm,*fwwav; frpcm=fopen("music2.pcm","rb"); fwwav=fopen("music.wav","wb"); numOfword=fread(buffer,sizeof(short),N,frpcm);//将music2.pcm文件写入buffer指针地址 WriteWaveFile(fwwav,numOfword,buffer);//将wav头文件和buffer指向的pcm文件合并,写入fwav指向的wav文件中 fclose(fwwav);
wav头文件:
wav.h#ifndef _WAV_H #define _WAV_H #include <stdio.h> #include <stdlib.h> #define SAMPLE_RATE 8000 #define QUANTIZATION 16 #define BYTES_EACH_SAMPLE 2 #define CHANNEL_NUN 1 #define FORMAT_TAG 1 struct RIFF_CHUNK { char riffid[4]; Uint32 dwSize; char riffType[4]; }; typedef struct RIFF_CHUNK WAVE_HEADER; struct FORMAT_CHUNK { char fccid[4]; Uint32 dwSize; short wFormatTag; short wChannels; Uint32 dwSamplesPerSec; Uint32 dwAvgBytePerSec; short wBlockAlign; short uiBitsPerSample; }; typedef struct FORMAT_CHUNK FORMAT; struct DATA_CHUNK { char fccid[4]; Uint32 dwSize; }; typedef struct DATA_CHUNK DATA; void WriteWaveHeader(FILE *fptr,Uint32 num); void WriteWaveFile(FILE *fptr,Uint32 num,short *ptr); #endif
6.总结
其实任何二进制数据都是有着属于它自己的解析规范,这就有点像我们学计算机网络的时候所说的“协议”,只要我们遵循这个规范或者“协议”,那么我们就可以将该文件真正隐含的信息读取出来。
我们这里仅仅是读取了一段WAV音频文件的元数据,没有把它的data chunk,也就是实际音频的数字信号读取出来,因为这涉及到数模信号的转换等知识,超出了我们的研究范围,