矩阵分解方法由于在Netflix中取的好成绩,成为近年来推荐系统中比较流行的推荐方法(无论是隐示数据还是显示数据,用的人都很多)。早期的方法有SVD,它通对评分矩阵进行分解,学习到潜在特征向量,但是它很容易过学习,因此,又提出了带正则化项目的分解方法。除此之外,还有基于概率论的推荐模型(Hofmann,probabilistic latent semantic model),以及基于分类问题的推荐方法,基于排序的模型等。本文我们将介绍一种在隐数据集上以个性化排序(每个用户都有不同的排序)为目标的推荐方法。这里的隐数据可以购买行为,点击行为或是观看行为。
问题的形式化
假设可观测的数据用S表示U表示用户集合,I表示item集合,则S是UxI的子集,由于我们只能观测到正例,负例通常用0来填充,我们的目标就是为每个用户进行个性化的排序。通常的思路就是为每个item预测一个个性化的得分(能够反应用户对该item的偏好),然后根据这个得分对item进行排序。机器学习的方法通常是给可观测数据S赋予正例,而其它(真正的负例和缺失值)赋予负的标签,这样做的结果就导致那些需要进行排序的item在训练过程中都被做为负例,这就是过学习问题,当然也可以通过正则化的方法来解决。
在本文中,我们采用user,item 对做为训练数据,不再给每个item一个评分,而是直接优化user,item对,这样比直接用0填充更能反应问题的本质。以下训练集的构造过程:
我们假设用户更喜欢那些能被我们观测到的item,并以此来构造偏序对,构造方法如图所示:

形式化表示方法:
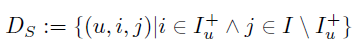
其它情况为未知项(?),而这些缺失项是我们将要排序的item对,这样训练集和测集便能很好的分开了。