雪花算法初步完成后,我们讨论了几个位运算的写法,大家知道雪花算法一旦确定后,很多数字都是定死的,比如机器占多少位,或者时间向左位移多少,这些在算法具体逻辑确定后就不会变了。那么写成最后的数字和用位运算计算出来有什么区别呢?
其实没有区别,我们的程序分为编译期和运行期,我们直接把程序编译好,然后查看class文件,就会发现,两种写法编译结果是一样的。用位运算计算出来只是更加灵活而已,定义很多死的数字也容易写错,后期维护混乱。所以,下面我们来一个最终版,首先看基本的几个常量定义:
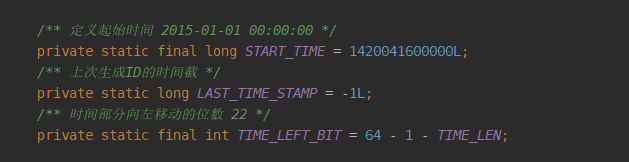
然后看时间部分的常量:
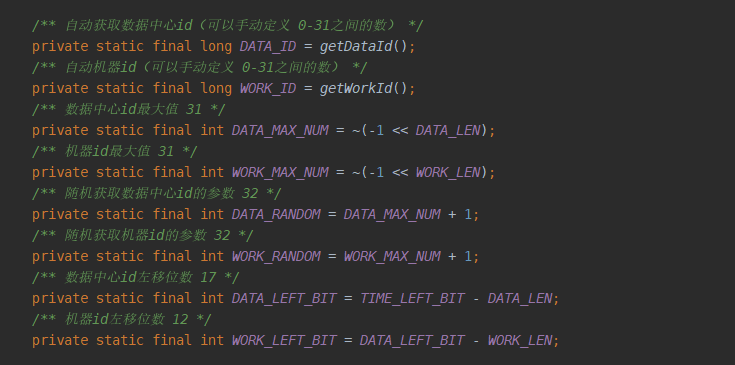
再看机器信息的常量:
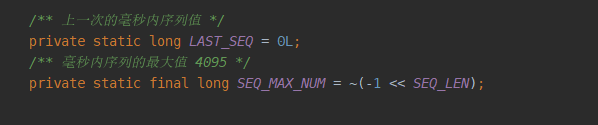
最后看毫秒内序列的常量定义:
上面的常量中,只要修改最开始的四个部分的长度,下面的所有常量都会自动修改。
再来看一下主程序:

注意上面判断统一毫秒内序列的变化。其它辅助方法都没有什么变化,不再讨论。现在我们再看看编译完后生成的class文件:

可以看到编译后的文件其实就是最终定义了死的常数。包括主程序也是一样:
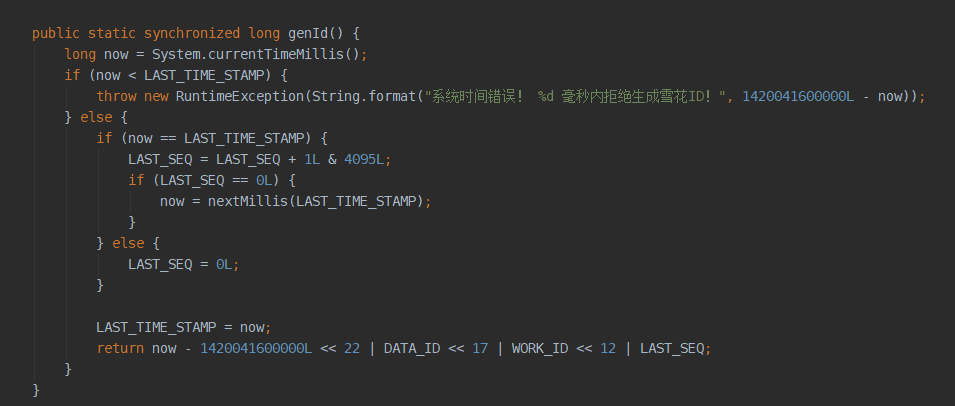
上面就是雪花算法的最终版!!!
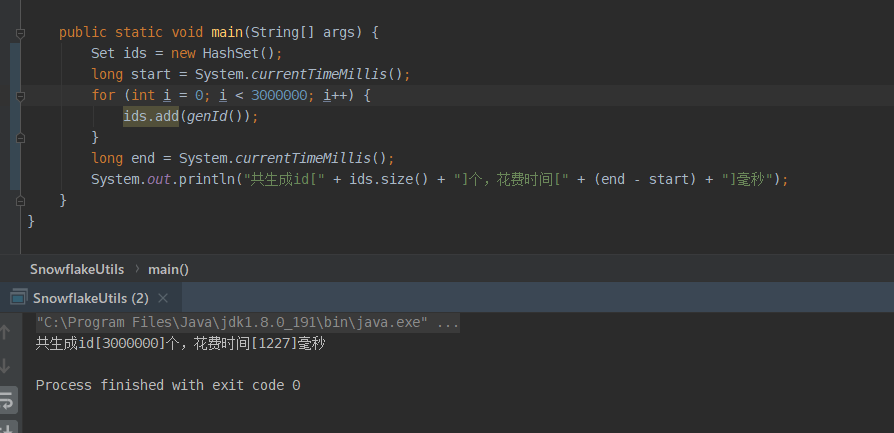
最后来测试一下效率,我们来生成300万个id看看花费的时间: